 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR: Facilitating Artificial Intelligence Resilience in Manufacturing Industrial Internet
Mar 03, 2025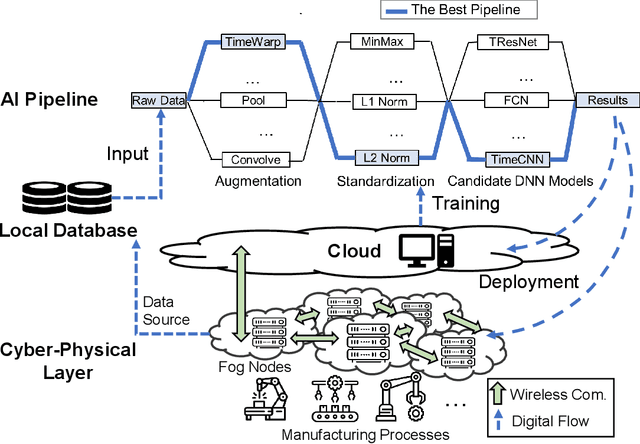
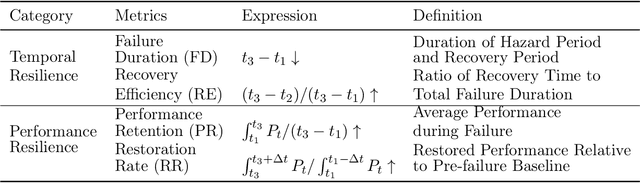
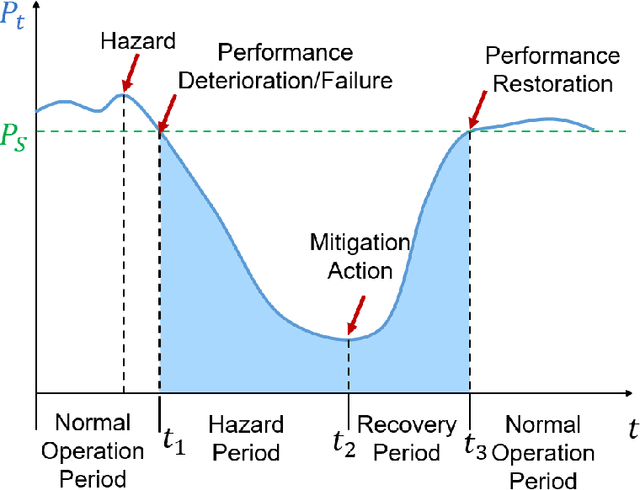
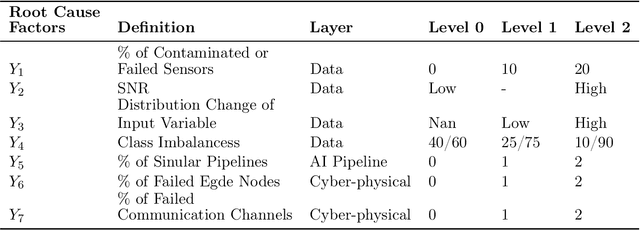
Artificial intelligence (AI) systems have been increasingly adopted in the Manufacturing Industrial Internet (MII). Investigating and enabling the AI resilience is very important to alleviate profound impact of AI system failures in manufacturing and Industrial Internet of Things (IIoT) operations, leading to critical decision making. However, there is a wide knowledge gap in defining the resilience of AI systems and analyzing potential root causes and corresponding mitigation strategies. In this work, we propose a novel framework for investigating the resilience of AI performance over time under hazard factors in data quality, AI pipelines, and the cyber-physical layer. The proposed method can facilitate effective diagnosis and mitigation strategies to recover AI performance based on a multimodal multi-head self latent attention model. The merits of the proposed method are elaborated using an MII testbed of connected Aerosol Jet Printing (AJP) machines, fog nodes, and Cloud with inference tasks via AI pipelines.
A Multifacet Hierarchical Sentiment-Topic Model with Application to Multi-Brand Online Review Analysis
Feb 26, 2025Multi-brand analysis based on review comments and ratings is a commonly used strategy to compare different brands in marketing. It can help consumers make more informed decisions and help marketers understand their brand's position in the market. In this work, we propose a multifacet hierarchical sentiment-topic model (MH-STM) to detect brand-associated sentiment polarities towards multiple comparative aspects from online customer reviews. The proposed method is built on a unified generative framework that explains review words with a hierarchical brand-associated topic model and the overall polarity score with a regression model on the empirical topic distribution. Moreover, a novel hierarchical Polya urn (HPU) scheme is proposed to enhance the topic-word association among topic hierarchy, such that the general topics shared by all brands are separated effectively from the unique topics specific to individual brands. The performance of the proposed method is evaluated on both synthetic data and two real-world review corpora. Experimental studies demonstrate that the proposed method can be effective in detecting reasonable topic hierarchy and deriving accurate brand-associated rankings on multi-aspects.
StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis
Feb 24, 2025
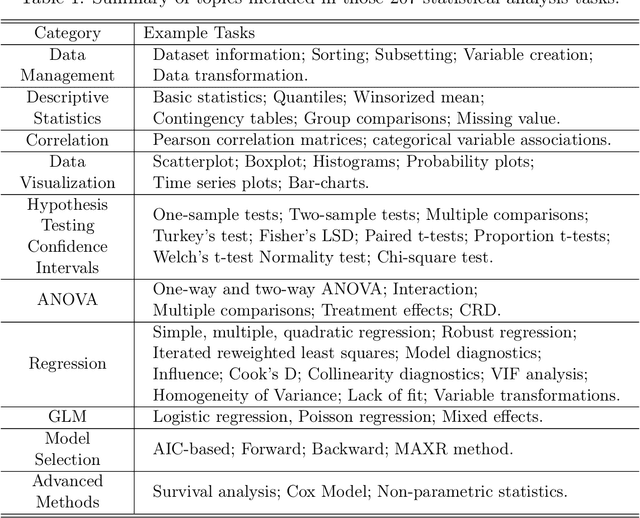
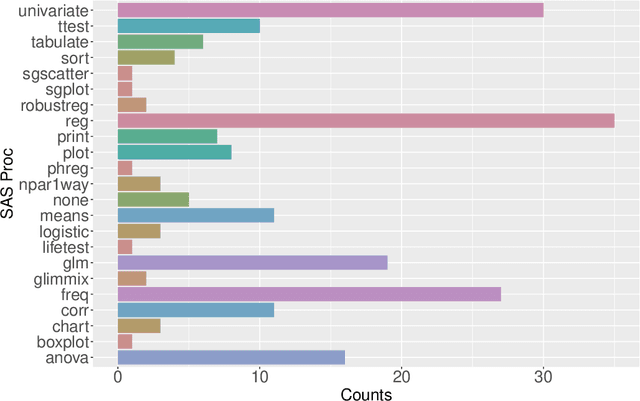
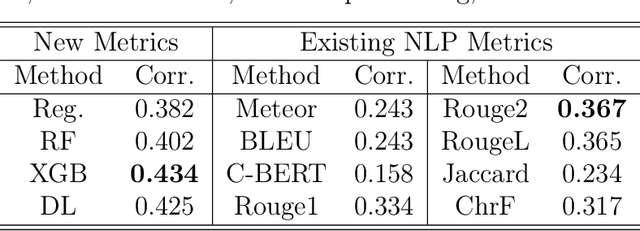
The coding capabilities of large language models (LLMs) have opened up new opportunities for automatic statistical analysis in machine learning and data science. However, before their widespread adoption, it is crucial to assess the accuracy of code generated by LLMs. A major challenge in this evaluation lies in the absence of a benchmark dataset for statistical code (e.g., SAS and R). To fill in this gap, this paper introduces StatLLM, an open-source dataset for evaluating the performance of LLMs in statistical analysis. The StatLLM dataset comprises three key components: statistical analysis tasks, LLM-generated SAS code, and human evaluation scores. The first component includes statistical analysis tasks spanning a variety of analyses and datasets, providing problem descriptions, dataset details, and human-verified SAS code. The second component features SAS code generated by ChatGPT 3.5, ChatGPT 4.0, and Llama 3.1 for those tasks. The third component contains evaluation scores from human experts in assessing the correctness, effectiveness, readability, executability, and output accuracy of the LLM-generated code. We also illustrate the unique potential of the established benchmark dataset for (1) evaluating and enhancing natural language processing metrics, (2) assessing and improving LLM performance in statistical coding, and (3) developing and testing of next-generation statistical software - advancements that are crucial for data science and machine learning research.
Performance Evaluation of Large Language Models in Statistical Programming
Feb 18, 2025The programming capabilities of large language models (LLMs) have revolutionized automatic code generation and opened new avenues for automatic statistical analysis. However, the validity and quality of these generated codes need to be systematically evaluated before they can be widely adopted. Despite their growing prominence, a comprehensive evaluation of statistical code generated by LLMs remains scarce in the literature. In this paper, we assess the performance of LLMs, including two versions of ChatGPT and one version of Llama, in the domain of SAS programming for statistical analysis. Our study utilizes a set of statistical analysis tasks encompassing diverse statistical topics and datasets. Each task includes a problem description, dataset information, and human-verified SAS code. We conduct a comprehensive assessment of the quality of SAS code generated by LLMs through human expert evaluation based on correctness, effectiveness, readability, executability, and the accuracy of output results. The analysis of rating scores reveals that while LLMs demonstrate usefulness in generating syntactically correct code, they struggle with tasks requiring deep domain understanding and may produce redundant or incorrect results. This study offers valuable insights into the capabilities and limitations of LLMs in statistical programming, providing guidance for future advancements in AI-assisted coding systems for statistical analysis.
Bridging the Data Gap in AI Reliability Research and Establishing DR-AIR, a Comprehensive Data Repository for AI Reliability
Feb 17, 2025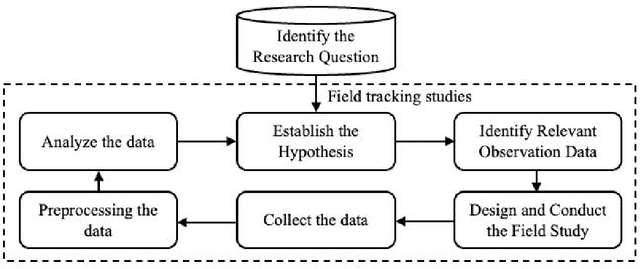


Artificial intelligence (AI) technology and systems have been advancing rapidly. However, ensuring the reliability of these systems is crucial for fostering public confidence in their use. This necessitates the modeling and analysis of reliability data specific to AI systems. A major challenge in AI reliability research, particularly for those in academia, is the lack of readily available AI reliability data. To address this gap, this paper focuses on conducting a comprehensive review of available AI reliability data and establishing DR-AIR: a data repository for AI reliability. Specifically, we introduce key measurements and data types for assessing AI reliability, along with the methodologies used to collect these data. We also provide a detailed description of the currently available datasets with illustrative examples. Furthermore, we outline the setup of the DR-AIR repository and demonstrate its practical applications. This repository provides easy access to datasets specifically curated for AI reliability research. We believe these efforts will significantly benefit the AI research community by facilitating access to valuable reliability data and promoting collaboration across various academic domains within AI. We conclude our paper with a call to action, encouraging the research community to contribute and share AI reliability data to further advance this critical field of study.
Deep Neural Network Identification of Limnonectes Species and New Class Detection Using Image Data
Nov 15, 2023



As is true of many complex tasks, the work of discovering, describing, and understanding the diversity of life on Earth (viz., biological systematics and taxonomy) requires many tools. Some of this work can be accomplished as it has been done in the past, but some aspects present us with challenges which traditional knowledge and tools cannot adequately resolve. One such challenge is presented by species complexes in which the morphological similarities among the group members make it difficult to reliably identify known species and detect new ones. We address this challenge by developing new tools using the principles of machine learning to resolve two specific questions related to species complexes. The first question is formulated as a classification problem in statistics and machine learning and the second question is an out-of-distribution (OOD) detection problem. We apply these tools to a species complex comprising Southeast Asian stream frogs (Limnonectes kuhlii complex) and employ a morphological character (hind limb skin texture) traditionally treated qualitatively in a quantitative and objective manner. We demonstrate that deep neural networks can successfully automate the classification of an image into a known species group for which it has been trained. We further demonstrate that the algorithm can successfully classify an image into a new class if the image does not belong to the existing classes. Additionally, we use the larger MNIST dataset to test the performance of our OOD detection algorithm. We finish our paper with some concluding remarks regarding the application of these methods to species complexes and our efforts to document true biodiversity. This paper has online supplementary materials.
Bayesian Sparse Regression for Mixed Multi-Responses with Application to Runtime Metrics Prediction in Fog Manufacturing
Oct 11, 2022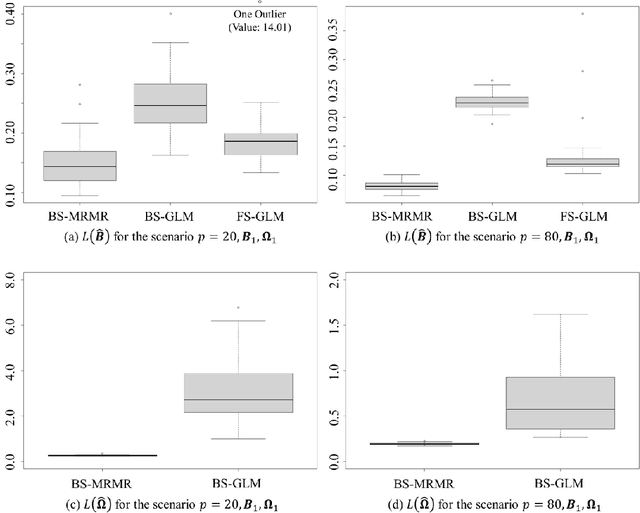
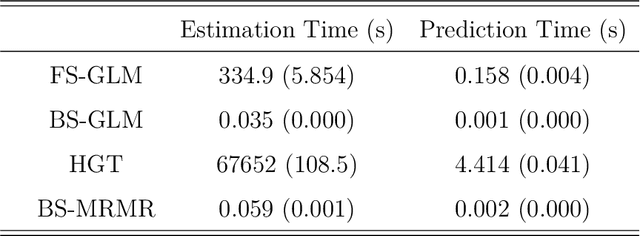
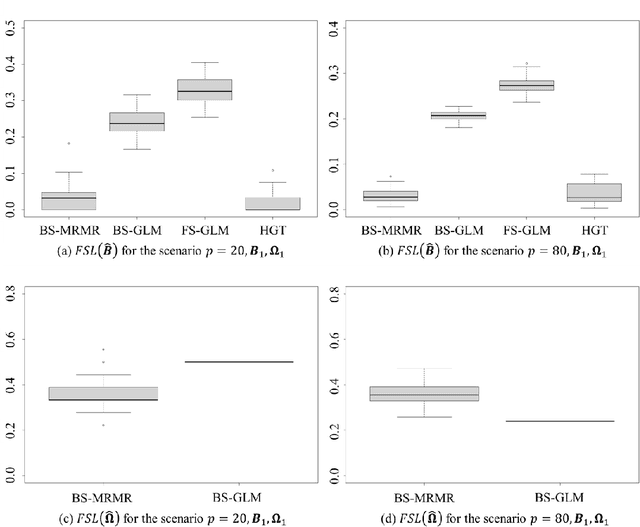

Fog manufacturing can greatly enhance traditional manufacturing systems through distributed Fog computation units, which are governed by predictive computational workload offloading methods under different Industrial Internet architectures. It is known that the predictive offloading methods highly depend on accurate prediction and uncertainty quantification of runtime performance metrics, containing multivariate mixed-type responses (i.e., continuous, counting, binary). In this work, we propose a Bayesian sparse regression for multivariate mixed responses to enhance the prediction of runtime performance metrics and to enable the statistical inferences. The proposed method considers both group and individual variable selection to jointly model the mixed types of runtime performance metrics. The conditional dependency among multiple responses is described by a graphical model using the precision matrix, where a spike-and-slab prior is used to enable the sparse estimation of the graph. The proposed method not only achieves accurate prediction, but also makes the predictive model more interpretable with statistical inferences on model parameters and prediction in the Fog manufacturing. A simulation study and a real case example in a Fog manufacturing are conducted to demonstrate the merits of the proposed model.
Boosting Sensitivity of Large-scale Online Experimentation via Dropout Buyer Imputation
Sep 09, 2022
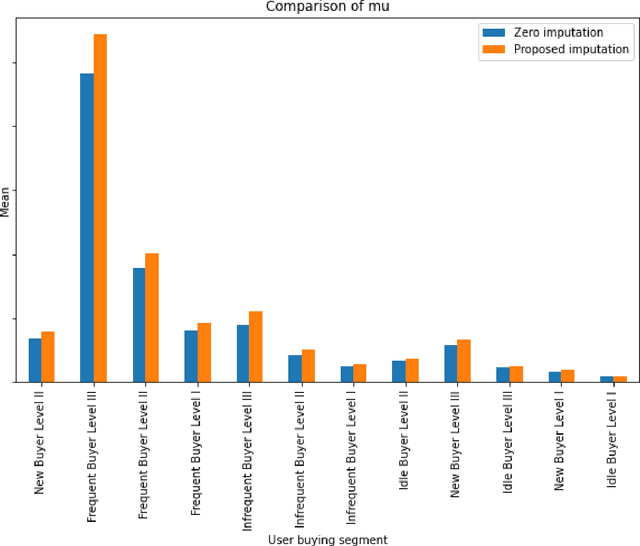
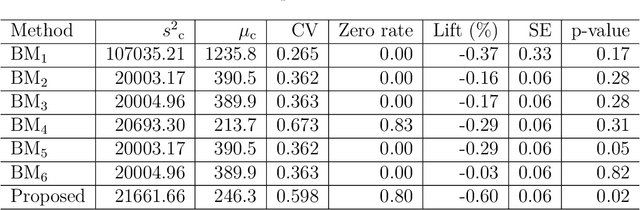
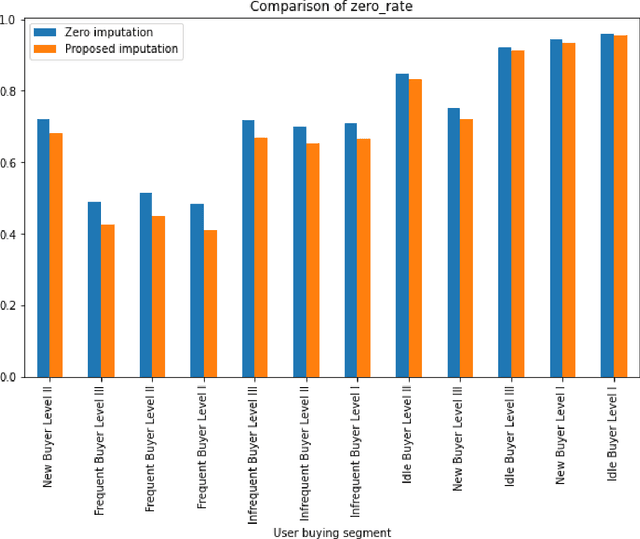
Metrics provide strong evidence to support hypotheses in online experimentation and hence reduce debates in the decision-making process. In this work, we introduce the concept of dropout buyers and categorize users with incomplete metric values into two groups: visitors and dropout buyers. For the analysis of incomplete metrics, we propose a cluster-based k-nearest neighbors-based imputation method. Our proposed imputation method considers both the experiment-specific features and users' activities along their shopping paths, allowing different imputation values for different users. To facilitate efficient imputation in large-scale data sets in online experimentation, the proposed method uses a combination of stratification and clustering. The performance of the proposed method was compared to several conventional methods in a past experiment at eBay.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021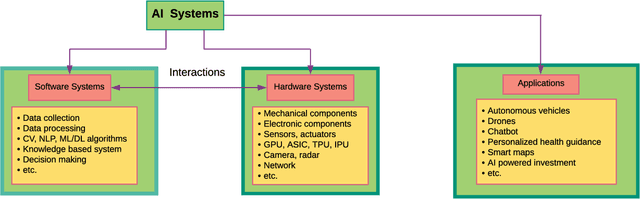
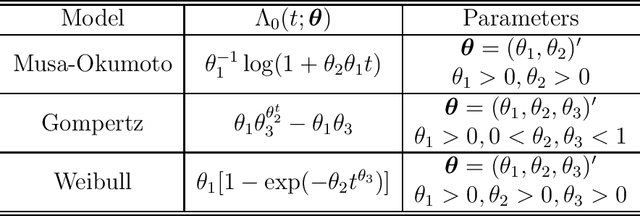
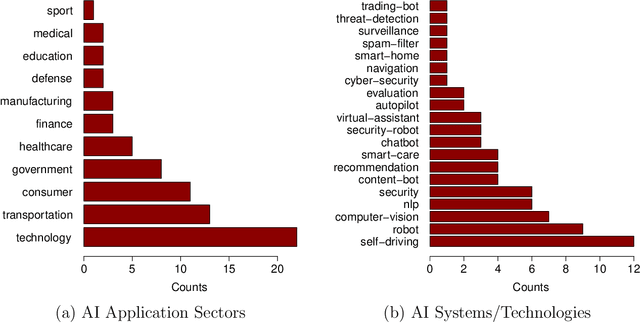
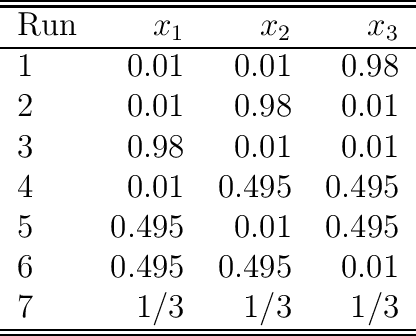
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
Tight Mutual Information Estimation With Contrastive Fenchel-Legendre Optimization
Jul 02, 2021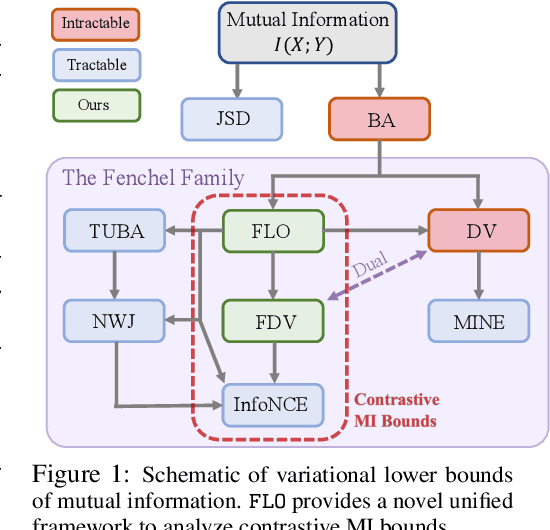
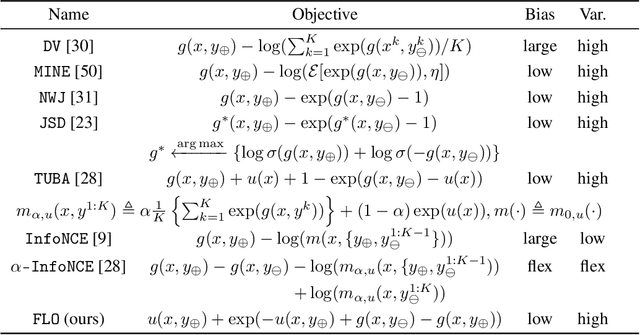
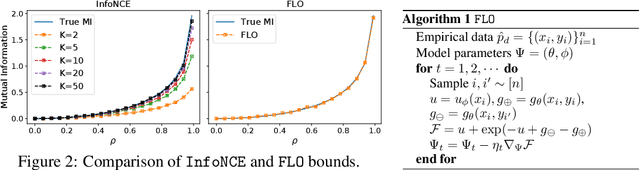

Successful applications of InfoNCE and its variants have popularized the use of contrastive variational mutual information (MI) estimators in machine learning. While featuring superior stability, these estimators crucially depend on costly large-batch training, and they sacrifice bound tightness for variance reduction. To overcome these limitations, we revisit the mathematics of popular variational MI bounds from the lens of unnormalized statistical modeling and convex optimization. Our investigation not only yields a new unified theoretical framework encompassing popular variational MI bounds but also leads to a novel, simple, and powerful contrastive MI estimator named as FLO. Theoretically, we show that the FLO estimator is tight, and it provably converges under stochastic gradient descent. Empirically, our FLO estimator overcomes the limitations of its predecessors and learns more efficiently. The utility of FLO is verified using an extensive set of benchmarks, which also reveals the trade-offs in practical MI estimation.