 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computationally Efficient Learning of Artificial Intelligence System Reliability Considering Error Propagation
Mar 18, 2026Artificial Intelligence (AI) systems are increasingly prominent in emerging smart cities, yet their reliability remains a critical concern. These systems typically operate through a sequence of interconnected functional stages, where upstream errors may propagate to downstream stages, ultimately affecting overall system reliability. Quantifying such error propagation is essential for accurate modeling of AI system reliability. However, this task is challenging due to: i) data availability: real-world AI system reliability data are often scarce and constrained by privacy concerns; ii) model validity: recurring error events across sequential stages are interdependent, violating the independence assumptions of statistical inference; and iii) computational complexity: AI systems process large volumes of high-speed data, resulting in frequent and complex recurrent error events that are difficult to track and analyze. To address these challenges, this paper leverages a physics-based autonomous vehicle simulation platform with a justifiable error injector to generate high-quality data for AI system reliability analysis. Building on this data, a new reliability modeling framework is developed to explicitly characterize error propagation across stages. Model parameters are estimated using a computationally efficient, theoretically guaranteed composite likelihood expectation - maximization algorithm. Its application to the reliability modeling for autonomous vehicle perception systems demonstrates its predictive accuracy and computational efficiency.
StatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis
Feb 24, 2025
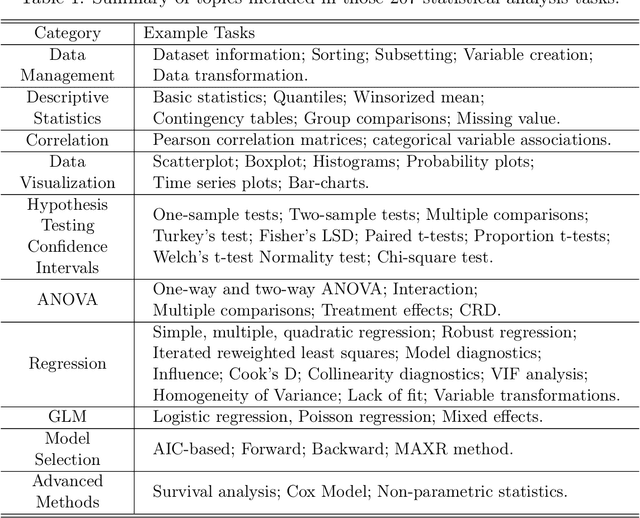
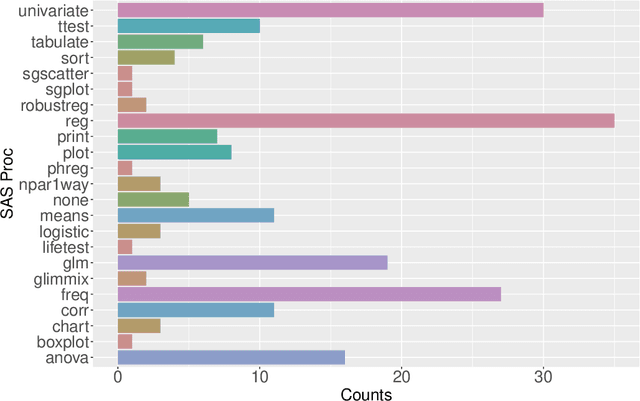
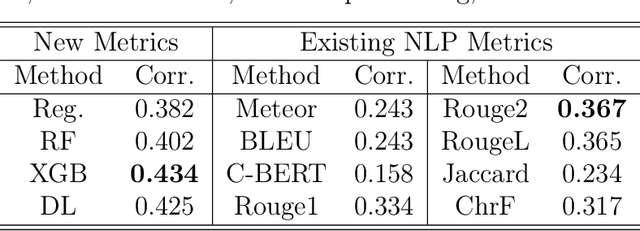
The coding capabilities of large language models (LLMs) have opened up new opportunities for automatic statistical analysis in machine learning and data science. However, before their widespread adoption, it is crucial to assess the accuracy of code generated by LLMs. A major challenge in this evaluation lies in the absence of a benchmark dataset for statistical code (e.g., SAS and R). To fill in this gap, this paper introduces StatLLM, an open-source dataset for evaluating the performance of LLMs in statistical analysis. The StatLLM dataset comprises three key components: statistical analysis tasks, LLM-generated SAS code, and human evaluation scores. The first component includes statistical analysis tasks spanning a variety of analyses and datasets, providing problem descriptions, dataset details, and human-verified SAS code. The second component features SAS code generated by ChatGPT 3.5, ChatGPT 4.0, and Llama 3.1 for those tasks. The third component contains evaluation scores from human experts in assessing the correctness, effectiveness, readability, executability, and output accuracy of the LLM-generated code. We also illustrate the unique potential of the established benchmark dataset for (1) evaluating and enhancing natural language processing metrics, (2) assessing and improving LLM performance in statistical coding, and (3) developing and testing of next-generation statistical software - advancements that are crucial for data science and machine learning research.
Performance Evaluation of Large Language Models in Statistical Programming
Feb 18, 2025The programming capabilities of large language models (LLMs) have revolutionized automatic code generation and opened new avenues for automatic statistical analysis. However, the validity and quality of these generated codes need to be systematically evaluated before they can be widely adopted. Despite their growing prominence, a comprehensive evaluation of statistical code generated by LLMs remains scarce in the literature. In this paper, we assess the performance of LLMs, including two versions of ChatGPT and one version of Llama, in the domain of SAS programming for statistical analysis. Our study utilizes a set of statistical analysis tasks encompassing diverse statistical topics and datasets. Each task includes a problem description, dataset information, and human-verified SAS code. We conduct a comprehensive assessment of the quality of SAS code generated by LLMs through human expert evaluation based on correctness, effectiveness, readability, executability, and the accuracy of output results. The analysis of rating scores reveals that while LLMs demonstrate usefulness in generating syntactically correct code, they struggle with tasks requiring deep domain understanding and may produce redundant or incorrect results. This study offers valuable insights into the capabilities and limitations of LLMs in statistical programming, providing guidance for future advancements in AI-assisted coding systems for statistical analysis.
Bridging the Data Gap in AI Reliability Research and Establishing DR-AIR, a Comprehensive Data Repository for AI Reliability
Feb 17, 2025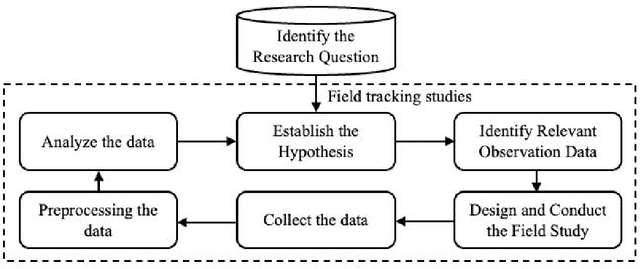
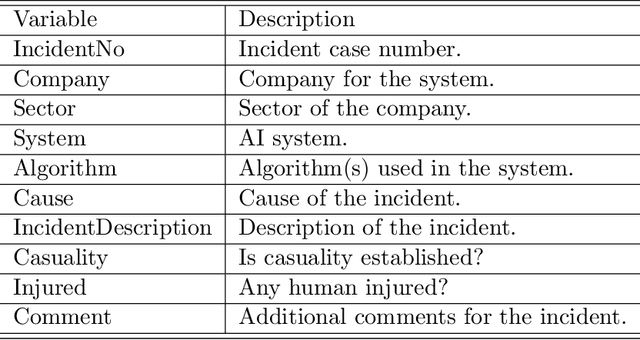


Artificial intelligence (AI) technology and systems have been advancing rapidly. However, ensuring the reliability of these systems is crucial for fostering public confidence in their use. This necessitates the modeling and analysis of reliability data specific to AI systems. A major challenge in AI reliability research, particularly for those in academia, is the lack of readily available AI reliability data. To address this gap, this paper focuses on conducting a comprehensive review of available AI reliability data and establishing DR-AIR: a data repository for AI reliability. Specifically, we introduce key measurements and data types for assessing AI reliability, along with the methodologies used to collect these data. We also provide a detailed description of the currently available datasets with illustrative examples. Furthermore, we outline the setup of the DR-AIR repository and demonstrate its practical applications. This repository provides easy access to datasets specifically curated for AI reliability research. We believe these efforts will significantly benefit the AI research community by facilitating access to valuable reliability data and promoting collaboration across various academic domains within AI. We conclude our paper with a call to action, encouraging the research community to contribute and share AI reliability data to further advance this critical field of study.
A Comprehensive Case Study on the Performance of Machine Learning Methods on the Classification of Solar Panel Electroluminescence Images
Aug 12, 2024Photovoltaics (PV) are widely used to harvest solar energy, an important form of renewable energy. Photovoltaic arrays consist of multiple solar panels constructed from solar cells. Solar cells in the field are vulnerable to various defects, and electroluminescence (EL) imaging provides effective and non-destructive diagnostics to detect those defects. We use multiple traditional machine learning and modern deep learning models to classify EL solar cell images into different functional/defective categories. Because of the asymmetry in the number of functional vs. defective cells, an imbalanced label problem arises in the EL image data. The current literature lacks insights on which methods and metrics to use for model training and prediction. In this paper, we comprehensively compare different machine learning and deep learning methods under different performance metrics on the classification of solar cell EL images from monocrystalline and polycrystalline modules. We provide a comprehensive discussion on different metrics. Our results provide insights and guidelines for practitioners in selecting prediction methods and performance metrics.
Planning Reliability Assurance Tests for Autonomous Vehicles
Nov 30, 2023Artificial intelligence (AI) technology has become increasingly prevalent and transforms our everyday life. One important application of AI technology is the development of autonomous vehicles (AV). However, the reliability of an AV needs to be carefully demonstrated via an assurance test so that the product can be used with confidence in the field. To plan for an assurance test, one needs to determine how many AVs need to be tested for how many miles and the standard for passing the test. Existing research has made great efforts in developing reliability demonstration tests in the other fields of applications for product development and assessment. However, statistical methods have not been utilized in AV test planning. This paper aims to fill in this gap by developing statistical methods for planning AV reliability assurance tests based on recurrent events data. We explore the relationship between multiple criteria of interest in the context of planning AV reliability assurance tests. Specifically, we develop two test planning strategies based on homogeneous and non-homogeneous Poisson processes while balancing multiple objectives with the Pareto front approach. We also offer recommendations for practical use. The disengagement events data from the California Department of Motor Vehicles AV testing program is used to illustrate the proposed assurance test planning methods.
Deep Neural Network Identification of Limnonectes Species and New Class Detection Using Image Data
Nov 15, 2023



As is true of many complex tasks, the work of discovering, describing, and understanding the diversity of life on Earth (viz., biological systematics and taxonomy) requires many tools. Some of this work can be accomplished as it has been done in the past, but some aspects present us with challenges which traditional knowledge and tools cannot adequately resolve. One such challenge is presented by species complexes in which the morphological similarities among the group members make it difficult to reliably identify known species and detect new ones. We address this challenge by developing new tools using the principles of machine learning to resolve two specific questions related to species complexes. The first question is formulated as a classification problem in statistics and machine learning and the second question is an out-of-distribution (OOD) detection problem. We apply these tools to a species complex comprising Southeast Asian stream frogs (Limnonectes kuhlii complex) and employ a morphological character (hind limb skin texture) traditionally treated qualitatively in a quantitative and objective manner. We demonstrate that deep neural networks can successfully automate the classification of an image into a known species group for which it has been trained. We further demonstrate that the algorithm can successfully classify an image into a new class if the image does not belong to the existing classes. Additionally, we use the larger MNIST dataset to test the performance of our OOD detection algorithm. We finish our paper with some concluding remarks regarding the application of these methods to species complexes and our efforts to document true biodiversity. This paper has online supplementary materials.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021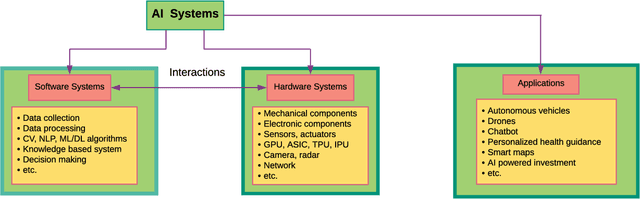
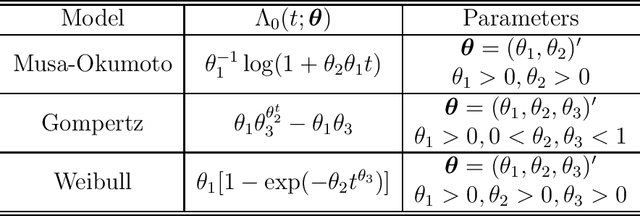
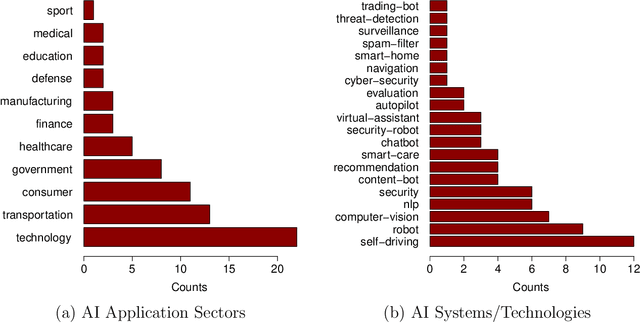
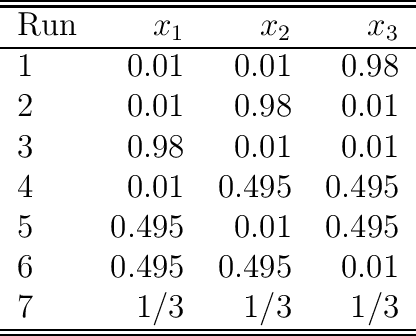
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
Reliability Analysis of Artificial Intelligence Systems Using Recurrent Events Data from Autonomous Vehicles
Feb 02, 2021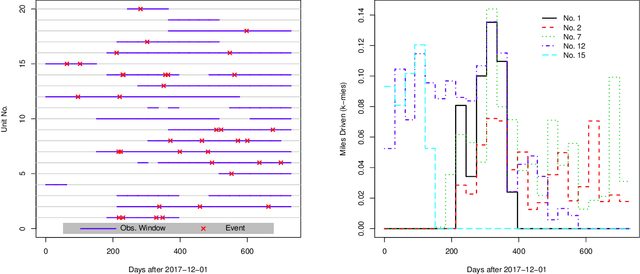


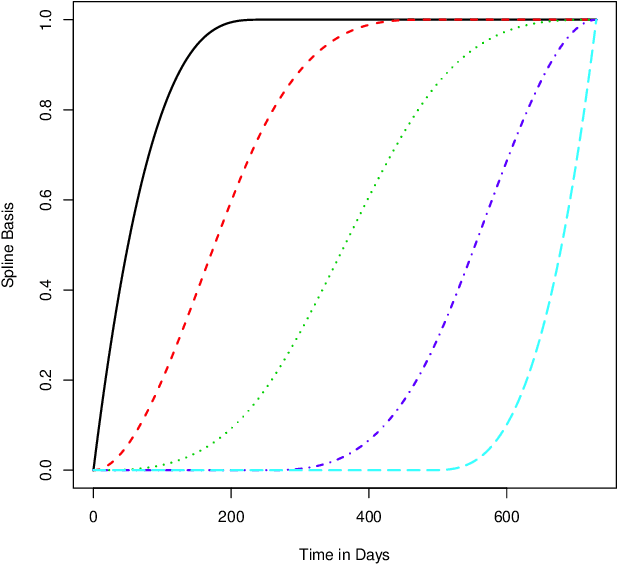
Artificial intelligence (AI) systems have become increasingly common and the trend will continue. Examples of AI systems include autonomous vehicles (AV), computer vision, natural language processing, and AI medical experts. To allow for safe and effective deployment of AI systems, the reliability of such systems needs to be assessed. Traditionally, reliability assessment is based on reliability test data and the subsequent statistical modeling and analysis. The availability of reliability data for AI systems, however, is limited because such data are typically sensitive and proprietary. The California Department of Motor Vehicles (DMV) oversees and regulates an AV testing program, in which many AV manufacturers are conducting AV road tests. Manufacturers participating in the program are required to report recurrent disengagement events to California DMV. This information is being made available to the public. In this paper, we use recurrent disengagement events as a representation of the reliability of the AI system in AV, and propose a statistical framework for modeling and analyzing the recurrent events data from AV driving tests. We use traditional parametric models in software reliability and propose a new nonparametric model based on monotonic splines to describe the event process. We develop inference procedures for selecting the best models, quantifying uncertainty, and testing heterogeneity in the event process. We then analyze the recurrent events data from four AV manufacturers, and make inferences on the reliability of the AI systems in AV. We also describe how the proposed analysis can be applied to assess the reliability of other AI systems.
Investigating the Robustness of Artificial Intelligent Algorithms with Mixture Experiments
Oct 10, 2020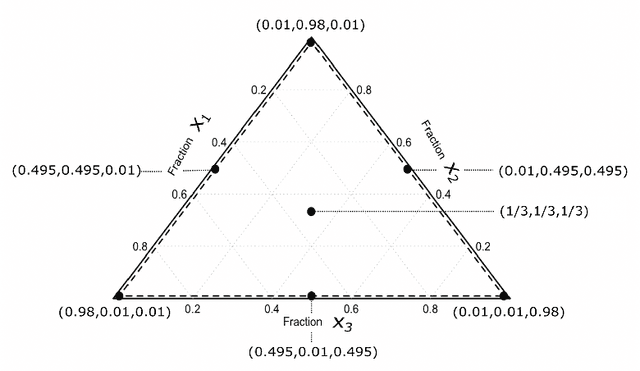
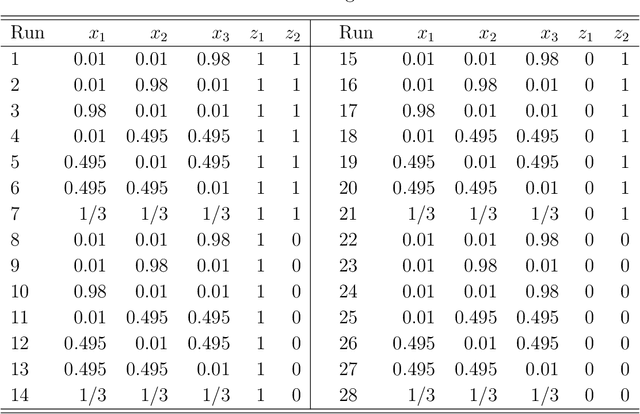
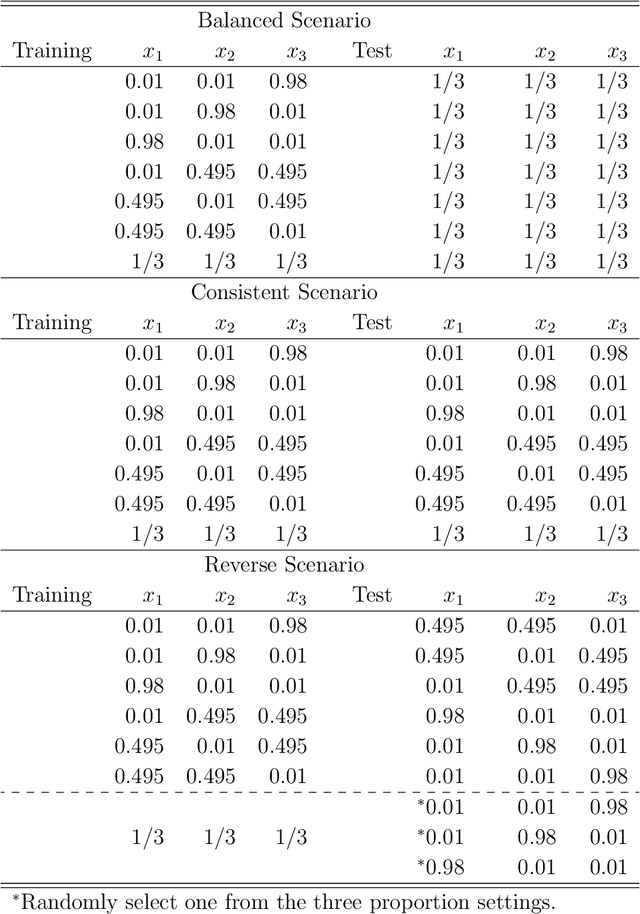
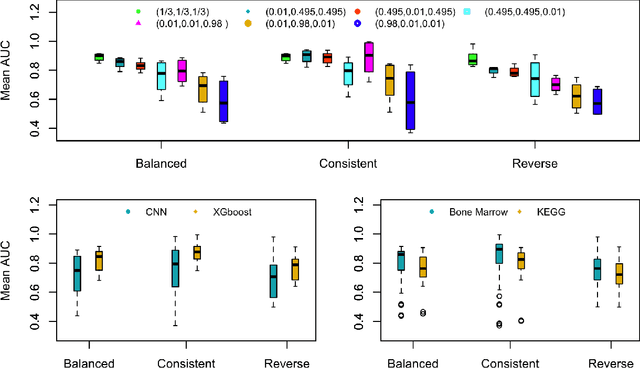
Artificial intelligent (AI) algorithms, such as deep learning and XGboost, are used in numerous applications including computer vision, autonomous driving, and medical diagnostics. The robustness of these AI algorithms is of great interest as inaccurate prediction could result in safety concerns and limit the adoption of AI systems. In this paper, we propose a framework based on design of experiments to systematically investigate the robustness of AI classification algorithms. A robust classification algorithm is expected to have high accuracy and low variability under different application scenarios. The robustness can be affected by a wide range of factors such as the imbalance of class labels in the training dataset, the chosen prediction algorithm, the chosen dataset of the application, and a change of distribution in the training and test datasets. To investigate the robustness of AI classification algorithms, we conduct a comprehensive set of mixture experiments to collect prediction performance results. Then statistical analyses are conducted to understand how various factors affect the robustness of AI classification algorithms. We summarize our findings and provide suggestions to practitioners in AI applications.