 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Large Language Models in Statistical Programming
Feb 18, 2025The programming capabilities of large language models (LLMs) have revolutionized automatic code generation and opened new avenues for automatic statistical analysis. However, the validity and quality of these generated codes need to be systematically evaluated before they can be widely adopted. Despite their growing prominence, a comprehensive evaluation of statistical code generated by LLMs remains scarce in the literature. In this paper, we assess the performance of LLMs, including two versions of ChatGPT and one version of Llama, in the domain of SAS programming for statistical analysis. Our study utilizes a set of statistical analysis tasks encompassing diverse statistical topics and datasets. Each task includes a problem description, dataset information, and human-verified SAS code. We conduct a comprehensive assessment of the quality of SAS code generated by LLMs through human expert evaluation based on correctness, effectiveness, readability, executability, and the accuracy of output results. The analysis of rating scores reveals that while LLMs demonstrate usefulness in generating syntactically correct code, they struggle with tasks requiring deep domain understanding and may produce redundant or incorrect results. This study offers valuable insights into the capabilities and limitations of LLMs in statistical programming, providing guidance for future advancements in AI-assisted coding systems for statistical analysis.
Bridging the Data Gap in AI Reliability Research and Establishing DR-AIR, a Comprehensive Data Repository for AI Reliability
Feb 17, 2025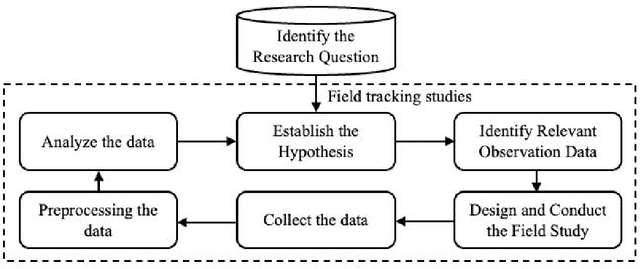
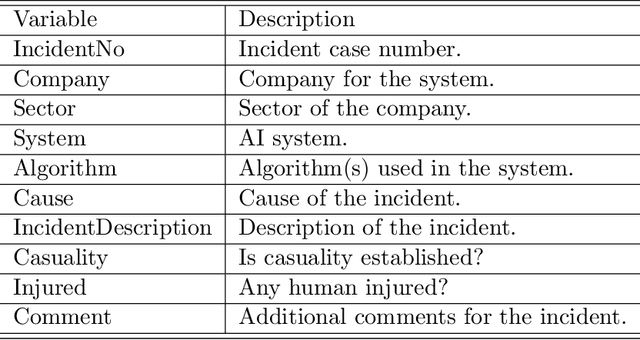


Artificial intelligence (AI) technology and systems have been advancing rapidly. However, ensuring the reliability of these systems is crucial for fostering public confidence in their use. This necessitates the modeling and analysis of reliability data specific to AI systems. A major challenge in AI reliability research, particularly for those in academia, is the lack of readily available AI reliability data. To address this gap, this paper focuses on conducting a comprehensive review of available AI reliability data and establishing DR-AIR: a data repository for AI reliability. Specifically, we introduce key measurements and data types for assessing AI reliability, along with the methodologies used to collect these data. We also provide a detailed description of the currently available datasets with illustrative examples. Furthermore, we outline the setup of the DR-AIR repository and demonstrate its practical applications. This repository provides easy access to datasets specifically curated for AI reliability research. We believe these efforts will significantly benefit the AI research community by facilitating access to valuable reliability data and promoting collaboration across various academic domains within AI. We conclude our paper with a call to action, encouraging the research community to contribute and share AI reliability data to further advance this critical field of study.