 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARDO: Reinforcing Diffusion Models without Reward Hacking
Dec 30, 2025Fine-tuning diffusion models via online reinforcement learning (RL) has shown great potential for enhancing text-to-image alignment. However, since precisely specifying a ground-truth objective for visual tasks remains challenging, the models are often optimized using a proxy reward that only partially captures the true goal. This mismatch often leads to reward hacking, where proxy scores increase while real image quality deteriorates and generation diversity collapses. While common solutions add regularization against the reference policy to prevent reward hacking, they compromise sample efficiency and impede the exploration of novel, high-reward regions, as the reference policy is usually sub-optimal. To address the competing demands of sample efficiency, effective exploration, and mitigation of reward hacking, we propose Gated and Adaptive Regularization with Diversity-aware Optimization (GARDO), a versatile framework compatible with various RL algorithms. Our key insight is that regularization need not be applied universally; instead, it is highly effective to selectively penalize a subset of samples that exhibit high uncertainty. To address the exploration challenge, GARDO introduces an adaptive regularization mechanism wherein the reference model is periodically updated to match the capabilities of the online policy, ensuring a relevant regularization target. To address the mode collapse issue in RL, GARDO amplifies the rewards for high-quality samples that also exhibit high diversity, encouraging mode coverage without destabilizing the optimization process. Extensive experiments across diverse proxy rewards and hold-out unseen metrics consistently show that GARDO mitigates reward hacking and enhances generation diversity without sacrificing sample efficiency or exploration, highlighting its effectiveness and robustness.
EIFNet: Leveraging Event-Image Fusion for Robust Semantic Segmentation
Jul 29, 2025Event-based semantic segmentation explores the potential of event cameras, which offer high dynamic range and fine temporal resolution, to achieve robust scene understanding in challenging environments. Despite these advantages, the task remains difficult due to two main challenges: extracting reliable features from sparse and noisy event streams, and effectively fusing them with dense, semantically rich image data that differ in structure and representation. To address these issues, we propose EIFNet, a multi-modal fusion network that combines the strengths of both event and frame-based inputs. The network includes an Adaptive Event Feature Refinement Module (AEFRM), which improves event representations through multi-scale activity modeling and spatial attention. In addition, we introduce a Modality-Adaptive Recalibration Module (MARM) and a Multi-Head Attention Gated Fusion Module (MGFM), which align and integrate features across modalities using attention mechanisms and gated fusion strategies. Experiments on DDD17-Semantic and DSEC-Semantic datasets show that EIFNet achieves state-of-the-art performance, demonstrating its effectiveness in event-based semantic segmentation.
Spintronic Bayesian Hardware Driven by Stochastic Magnetic Domain Wall Dynamics
Jul 23, 2025As artificial intelligence (AI) advances into diverse applications, ensuring reliability of AI models is increasingly critical. Conventional neural networks offer strong predictive capabilities but produce deterministic outputs without inherent uncertainty estimation, limiting their reliability in safety-critical domains. Probabilistic neural networks (PNNs), which introduce randomness, have emerged as a powerful approach for enabling intrinsic uncertainty quantification. However, traditional CMOS architectures are inherently designed for deterministic operation and actively suppress intrinsic randomness. This poses a fundamental challenge for implementing PNNs, as probabilistic processing introduces significant computational overhead. To address this challenge, we introduce a Magnetic Probabilistic Computing (MPC) platform-an energy-efficient, scalable hardware accelerator that leverages intrinsic magnetic stochasticity for uncertainty-aware computing. This physics-driven strategy utilizes spintronic systems based on magnetic domain walls (DWs) and their dynamics to establish a new paradigm of physical probabilistic computing for AI. The MPC platform integrates three key mechanisms: thermally induced DW stochasticity, voltage controlled magnetic anisotropy (VCMA), and tunneling magnetoresistance (TMR), enabling fully electrical and tunable probabilistic functionality at the device level. As a representative demonstration, we implement a Bayesian Neural Network (BNN) inference structure and validate its functionality on CIFAR-10 classification tasks. Compared to standard 28nm CMOS implementations, our approach achieves a seven orders of magnitude improvement in the overall figure of merit, with substantial gains in area efficiency, energy consumption, and speed. These results underscore the MPC platform's potential to enable reliable and trustworthy physical AI systems.
Scaling Image and Video Generation via Test-Time Evolutionary Search
May 23, 2025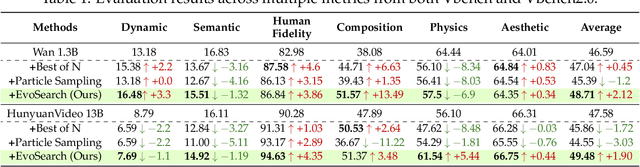

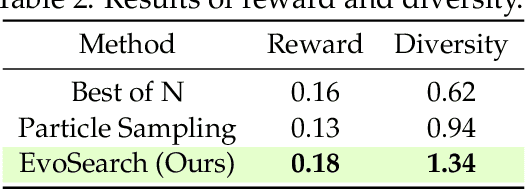
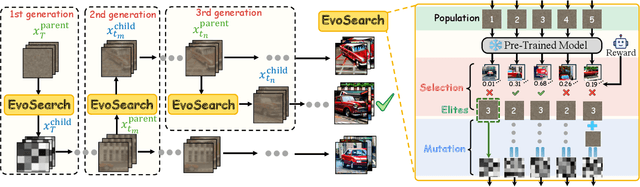
As the marginal cost of scaling computation (data and parameters) during model pre-training continues to increase substantially, test-time scaling (TTS) has emerged as a promising direction for improving generative model performance by allocating additional computation at inference time. While TTS has demonstrated significant success across multiple language tasks, there remains a notable gap in understanding the test-time scaling behaviors of image and video generative models (diffusion-based or flow-based models). Although recent works have initiated exploration into inference-time strategies for vision tasks, these approaches face critical limitations: being constrained to task-specific domains, exhibiting poor scalability, or falling into reward over-optimization that sacrifices sample diversity. In this paper, we propose \textbf{Evo}lutionary \textbf{Search} (EvoSearch), a novel, generalist, and efficient TTS method that effectively enhances the scalability of both image and video generation across diffusion and flow models, without requiring additional training or model expansion. EvoSearch reformulates test-time scaling for diffusion and flow models as an evolutionary search problem, leveraging principles from biological evolution to efficiently explore and refine the denoising trajectory. By incorporating carefully designed selection and mutation mechanisms tailored to the stochastic differential equation denoising process, EvoSearch iteratively generates higher-quality offspring while preserving population diversity. Through extensive evaluation across both diffusion and flow architectures for image and video generation tasks, we demonstrate that our method consistently outperforms existing approaches, achieves higher diversity, and shows strong generalizability to unseen evaluation metrics. Our project is available at the website https://tinnerhrhe.github.io/evosearch.
Performance Evaluation of Large Language Models in Statistical Programming
Feb 18, 2025The programming capabilities of large language models (LLMs) have revolutionized automatic code generation and opened new avenues for automatic statistical analysis. However, the validity and quality of these generated codes need to be systematically evaluated before they can be widely adopted. Despite their growing prominence, a comprehensive evaluation of statistical code generated by LLMs remains scarce in the literature. In this paper, we assess the performance of LLMs, including two versions of ChatGPT and one version of Llama, in the domain of SAS programming for statistical analysis. Our study utilizes a set of statistical analysis tasks encompassing diverse statistical topics and datasets. Each task includes a problem description, dataset information, and human-verified SAS code. We conduct a comprehensive assessment of the quality of SAS code generated by LLMs through human expert evaluation based on correctness, effectiveness, readability, executability, and the accuracy of output results. The analysis of rating scores reveals that while LLMs demonstrate usefulness in generating syntactically correct code, they struggle with tasks requiring deep domain understanding and may produce redundant or incorrect results. This study offers valuable insights into the capabilities and limitations of LLMs in statistical programming, providing guidance for future advancements in AI-assisted coding systems for statistical analysis.
Pre-Trained Video Generative Models as World Simulators
Feb 10, 2025



Video generative models pre-trained on large-scale internet datasets have achieved remarkable success, excelling at producing realistic synthetic videos. However, they often generate clips based on static prompts (e.g., text or images), limiting their ability to model interactive and dynamic scenarios. In this paper, we propose Dynamic World Simulation (DWS), a novel approach to transform pre-trained video generative models into controllable world simulators capable of executing specified action trajectories. To achieve precise alignment between conditioned actions and generated visual changes, we introduce a lightweight, universal action-conditioned module that seamlessly integrates into any existing model. Instead of focusing on complex visual details, we demonstrate that consistent dynamic transition modeling is the key to building powerful world simulators. Building upon this insight, we further introduce a motion-reinforced loss that enhances action controllability by compelling the model to capture dynamic changes more effectively. Experiments demonstrate that DWS can be versatilely applied to both diffusion and autoregressive transformer models, achieving significant improvements in generating action-controllable, dynamically consistent videos across games and robotics domains. Moreover, to facilitate the applications of the learned world simulator in downstream tasks such as model-based reinforcement learning, we propose prioritized imagination to improve sample efficiency, demonstrating competitive performance compared with state-of-the-art methods.
Task-agnostic Pre-training and Task-guided Fine-tuning for Versatile Diffusion Planner
Sep 30, 2024



Diffusion models have demonstrated their capabilities in modeling trajectories of multi-tasks. However, existing multi-task planners or policies typically rely on task-specific demonstrations via multi-task imitation, or require task-specific reward labels to facilitate policy optimization via Reinforcement Learning (RL). To address these challenges, we aim to develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks. In this paper, we propose \textbf{SODP}, a two-stage framework that leverages \textbf{S}ub-\textbf{O}ptimal data to learn a \textbf{D}iffusion \textbf{P}lanner, which is generalizable for various downstream tasks. Specifically, in the pre-training stage, we train a foundation diffusion planner that extracts general planning capabilities by modeling the versatile distribution of multi-task trajectories, which can be sub-optimal and has wide data coverage. Then for downstream tasks, we adopt RL-based fine-tuning with task-specific rewards to fast refine the diffusion planner, which aims to generate action sequences with higher task-specific returns. Experimental results from multi-task domains including Meta-World and Adroit demonstrate that SODP outperforms state-of-the-art methods with only a small amount of data for reward-guided fine-tuning.
Voltage-Controlled Magnetoelectric Devices for Neuromorphic Diffusion Process
Jul 17, 2024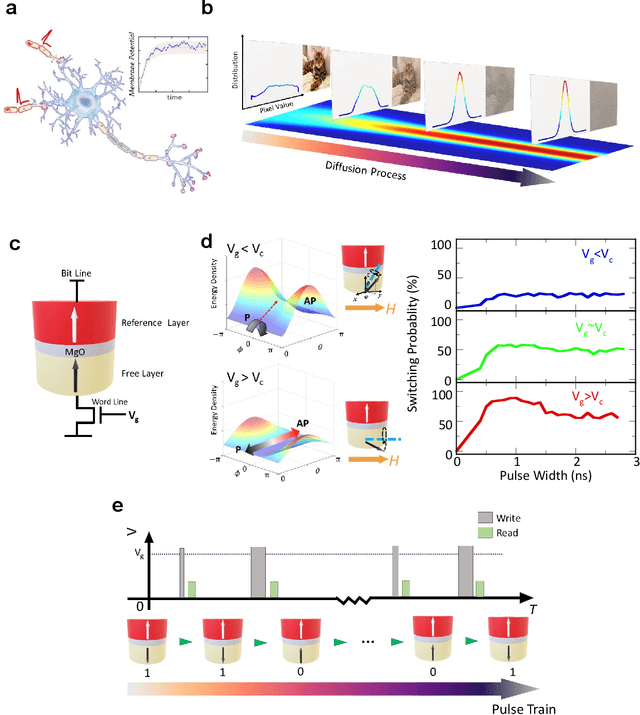
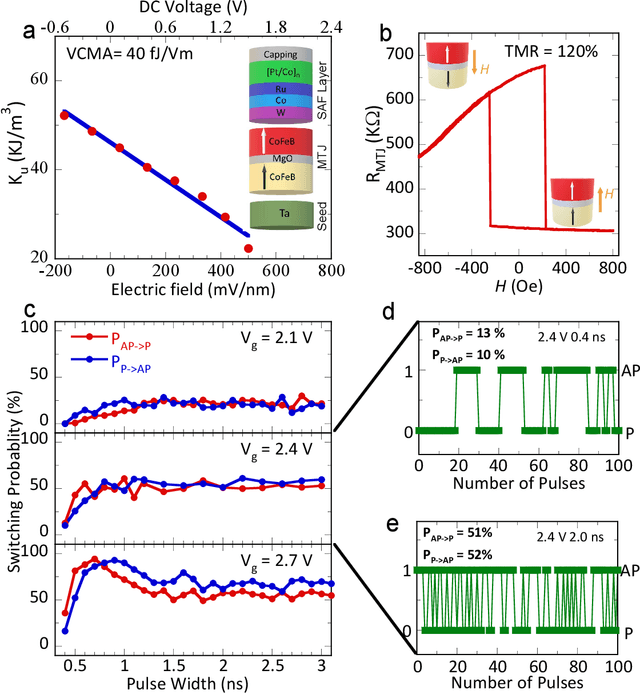
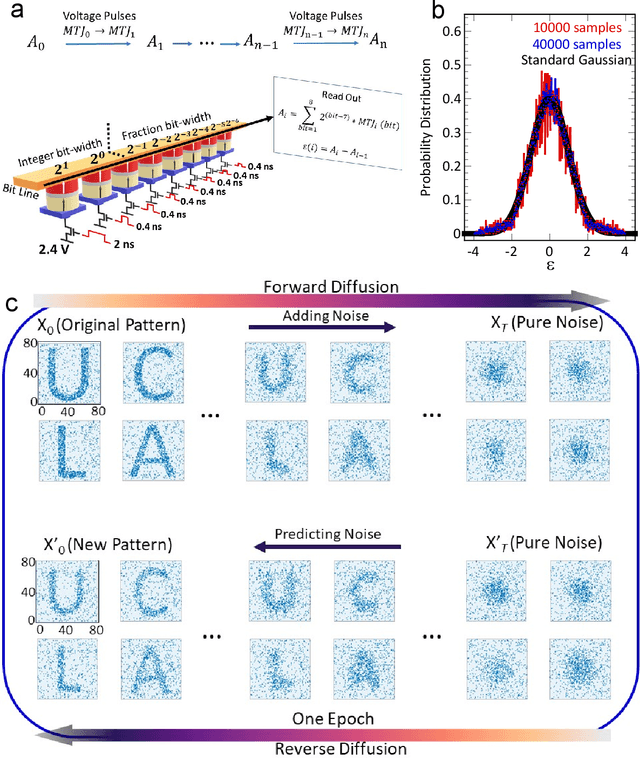
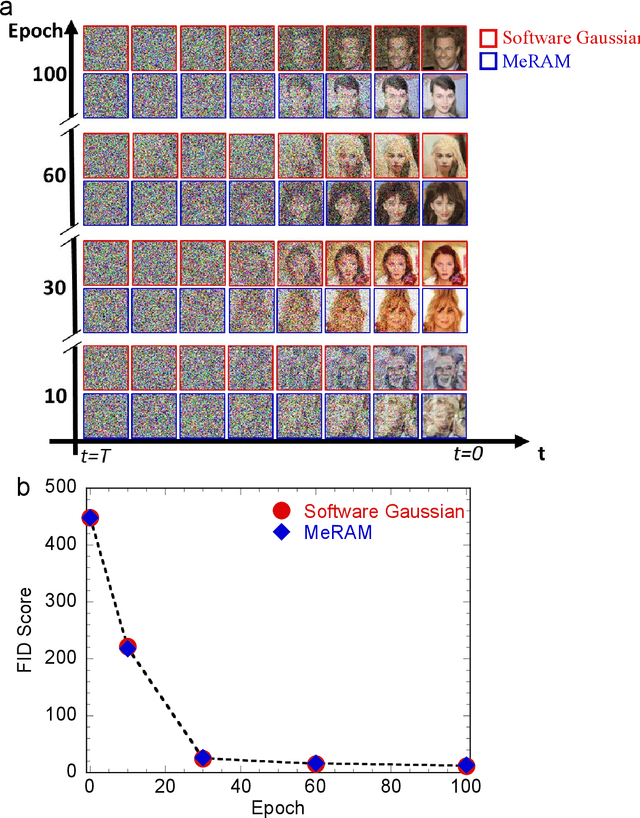
Stochastic diffusion processes are pervasive in nature, from the seemingly erratic Brownian motion to the complex interactions of synaptically-coupled spiking neurons. Recently, drawing inspiration from Langevin dynamics, neuromorphic diffusion models were proposed and have become one of the major breakthroughs in the field of generative artificial intelligence. Unlike discriminative models that have been well developed to tackle classification or regression tasks, diffusion models as well as other generative models such as ChatGPT aim at creating content based upon contexts learned. However, the more complex algorithms of these models result in high computational costs using today's technologies, creating a bottleneck in their efficiency, and impeding further development. Here, we develop a spintronic voltage-controlled magnetoelectric memory hardware for the neuromorphic diffusion process. The in-memory computing capability of our spintronic devices goes beyond current Von Neumann architecture, where memory and computing units are separated. Together with the non-volatility of magnetic memory, we can achieve high-speed and low-cost computing, which is desirable for the increasing scale of generative models in the current era. We experimentally demonstrate that the hardware-based true random diffusion process can be implemented for image generation and achieve comparable image quality to software-based training as measured by the Frechet inception distance (FID) score, achieving ~10^3 better energy-per-bit-per-area over traditional hardware.
Rectifying Reinforcement Learning for Reward Matching
Jun 04, 2024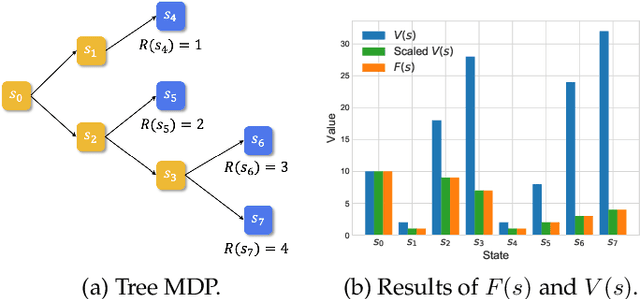
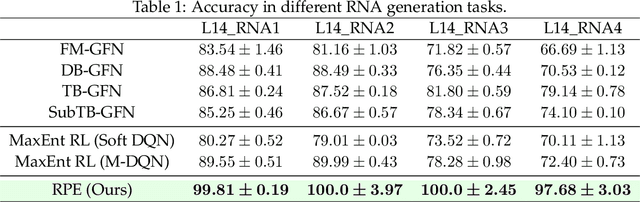
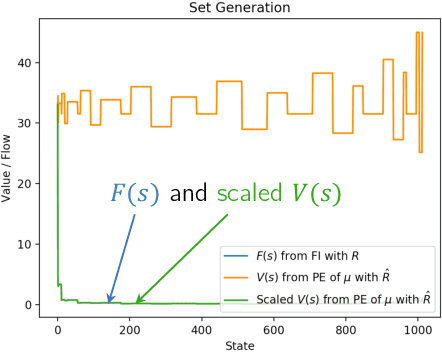
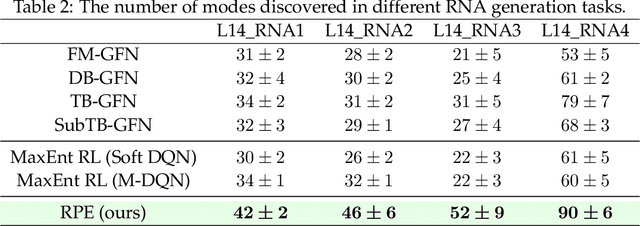
The Generative Flow Network (GFlowNet) is a probabilistic framework in which an agent learns a stochastic policy and flow functions to sample objects with probability proportional to an unnormalized reward function. GFlowNets share a strong resemblance to reinforcement learning (RL), that typically aims to maximize reward, due to their sequential decision-making processes. Recent works have studied connections between GFlowNets and maximum entropy (MaxEnt) RL, which modifies the standard objective of RL agents by learning an entropy-regularized objective. However, a critical theoretical gap persists: despite the apparent similarities in their sequential decision-making nature, a direct link between GFlowNets and standard RL has yet to be discovered, while bridging this gap could further unlock the potential of both fields. In this paper, we establish a new connection between GFlowNets and policy evaluation for a uniform policy. Surprisingly, we find that the resulting value function for the uniform policy has a close relationship to the flows in GFlowNets. Leveraging these insights, we further propose a novel rectified policy evaluation (RPE) algorithm, which achieves the same reward-matching effect as GFlowNets, offering a new perspective. We compare RPE, MaxEnt RL, and GFlowNets in a number of benchmarks, and show that RPE achieves competitive results compared to previous approaches. This work sheds light on the previously unexplored connection between (non-MaxEnt) RL and GFlowNets, potentially opening new avenues for future research in both fields.
Looking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
Jun 03, 2024Generative Flow Networks (GFlowNets) are amortized sampling methods for learning a stochastic policy to sequentially generate compositional objects with probabilities proportional to their rewards. GFlowNets exhibit a remarkable ability to generate diverse sets of high-reward objects, in contrast to standard return maximization reinforcement learning approaches, which often converge to a single optimal solution. Recent works have arisen for learning goal-conditioned GFlowNets to acquire various useful properties, aiming to train a single GFlowNet capable of achieving different goals as the task specifies. However, training a goal-conditioned GFlowNet poses critical challenges due to extremely sparse rewards, which is further exacerbated in large state spaces. In this work, we propose a novel method named Retrospective Backward Synthesis (RBS) to address these challenges. Specifically, RBS synthesizes a new backward trajectory based on the backward policy in GFlowNets to enrich training trajectories with enhanced quality and diversity, thereby efficiently solving the sparse reward problem. Extensive empirical results show that our method improves sample efficiency by a large margin and outperforms strong baselines on various standard evaluation benchmarks.