 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-Inspired Color Space Design for Photo White Balance Editing
Dec 11, 2025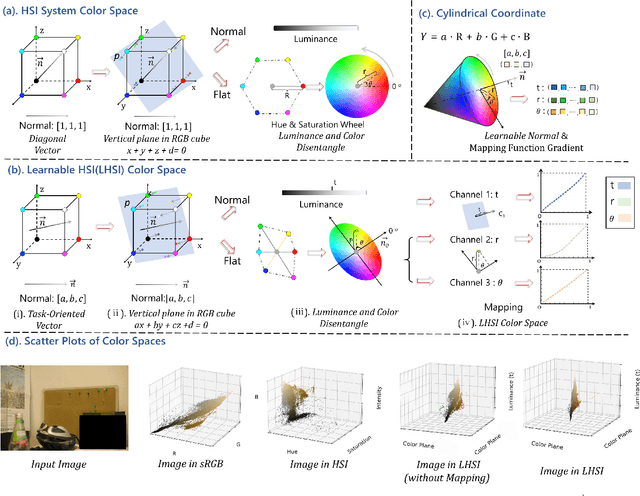
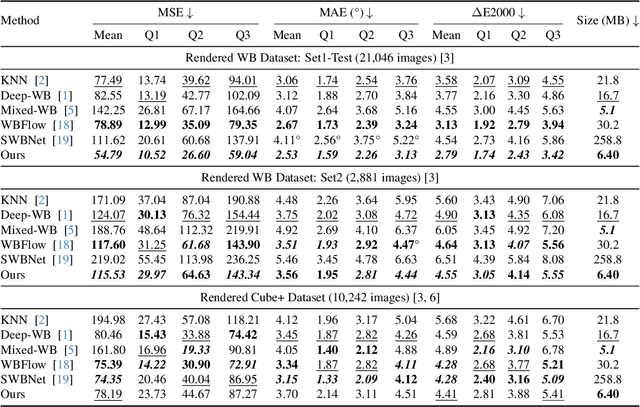
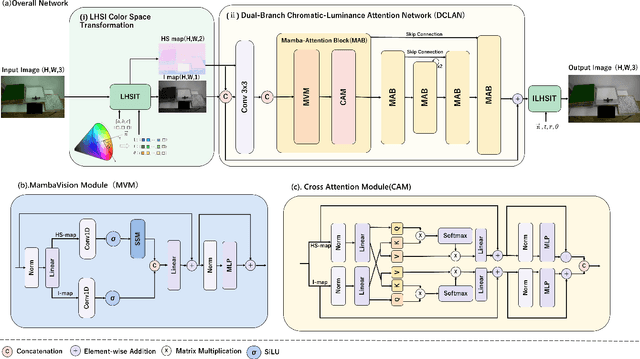
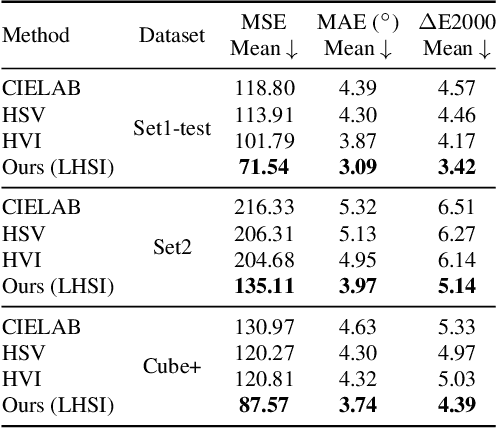
White balance (WB) is a key step in the image signal processor (ISP) pipeline that mitigates color casts caused by varying illumination and restores the scene's true colors. Currently, sRGB-based WB editing for post-ISP WB correction is widely used to address color constancy failures in the ISP pipeline when the original camera RAW is unavailable. However, additive color models (e.g., sRGB) are inherently limited by fixed nonlinear transformations and entangled color channels, which often impede their generalization to complex lighting conditions. To address these challenges, we propose a novel framework for WB correction that leverages a perception-inspired Learnable HSI (LHSI) color space. Built upon a cylindrical color model that naturally separates luminance from chromatic components, our framework further introduces dedicated parameters to enhance this disentanglement and learnable mapping to adaptively refine the flexibility. Moreover, a new Mamba-based network is introduced, which is tailored to the characteristics of the proposed LHSI color space. Experimental results on benchmark datasets demonstrate the superiority of our method, highlighting the potential of perception-inspired color space design in computational photography. The source code is available at https://github.com/YangCheng58/WB_Color_Space.
Spintronic Bayesian Hardware Driven by Stochastic Magnetic Domain Wall Dynamics
Jul 23, 2025As artificial intelligence (AI) advances into diverse applications, ensuring reliability of AI models is increasingly critical. Conventional neural networks offer strong predictive capabilities but produce deterministic outputs without inherent uncertainty estimation, limiting their reliability in safety-critical domains. Probabilistic neural networks (PNNs), which introduce randomness, have emerged as a powerful approach for enabling intrinsic uncertainty quantification. However, traditional CMOS architectures are inherently designed for deterministic operation and actively suppress intrinsic randomness. This poses a fundamental challenge for implementing PNNs, as probabilistic processing introduces significant computational overhead. To address this challenge, we introduce a Magnetic Probabilistic Computing (MPC) platform-an energy-efficient, scalable hardware accelerator that leverages intrinsic magnetic stochasticity for uncertainty-aware computing. This physics-driven strategy utilizes spintronic systems based on magnetic domain walls (DWs) and their dynamics to establish a new paradigm of physical probabilistic computing for AI. The MPC platform integrates three key mechanisms: thermally induced DW stochasticity, voltage controlled magnetic anisotropy (VCMA), and tunneling magnetoresistance (TMR), enabling fully electrical and tunable probabilistic functionality at the device level. As a representative demonstration, we implement a Bayesian Neural Network (BNN) inference structure and validate its functionality on CIFAR-10 classification tasks. Compared to standard 28nm CMOS implementations, our approach achieves a seven orders of magnitude improvement in the overall figure of merit, with substantial gains in area efficiency, energy consumption, and speed. These results underscore the MPC platform's potential to enable reliable and trustworthy physical AI systems.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Stereophotoclinometry Revisited
Apr 11, 2025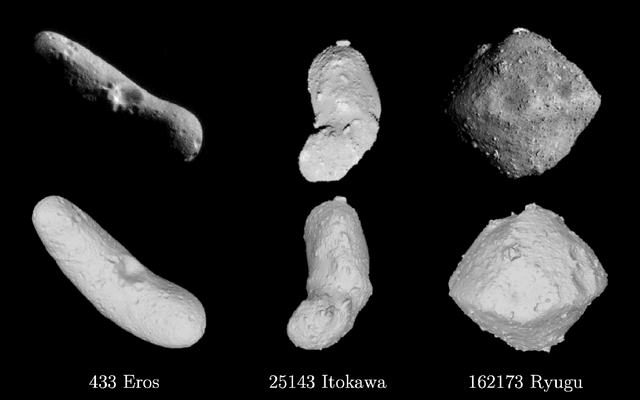

Image-based surface reconstruction and characterization is crucial for missions to small celestial bodies, as it informs mission planning, navigation, and scientific analysis. However, current state-of-the-practice methods, such as stereophotoclinometry (SPC), rely heavily on human-in-the-loop verification and high-fidelity a priori information. This paper proposes Photoclinometry-from-Motion (PhoMo), a novel framework that incorporates photoclinometry techniques into a keypoint-based structure-from-motion (SfM) system to estimate the surface normal and albedo at detected landmarks to improve autonomous surface and shape characterization of small celestial bodies from in-situ imagery. In contrast to SPC, we forego the expensive maplet estimation step and instead use dense keypoint measurements and correspondences from an autonomous keypoint detection and matching method based on deep learning. Moreover, we develop a factor graph-based approach allowing for simultaneous optimization of the spacecraft's pose, landmark positions, Sun-relative direction, and surface normals and albedos via fusion of Sun vector measurements and image keypoint measurements. The proposed framework is validated on real imagery taken by the Dawn mission to the asteroid 4 Vesta and the minor planet 1 Ceres and compared against an SPC reconstruction, where we demonstrate superior rendering performance compared to an SPC solution and precise alignment to a stereophotogrammetry (SPG) solution without relying on any a priori camera pose and topography information or humans-in-the-loop.
MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
Apr 03, 2025



Mixture-of-Experts (MoE) showcases tremendous potential to scale large language models (LLMs) with enhanced performance and reduced computational complexity. However, its sparsely activated architecture shifts feed-forward networks (FFNs) from being compute-intensive to memory-intensive during inference, leading to substantially lower GPU utilization and increased operational costs. We present MegaScale-Infer, an efficient and cost-effective system for serving large-scale MoE models. MegaScale-Infer disaggregates attention and FFN modules within each model layer, enabling independent scaling, tailored parallelism strategies, and heterogeneous deployment for both modules. To fully exploit disaggregation in the presence of MoE's sparsity, MegaScale-Infer introduces ping-pong pipeline parallelism, which partitions a request batch into micro-batches and shuttles them between attention and FFNs for inference. Combined with distinct model parallelism for each module, MegaScale-Infer effectively hides communication overhead and maximizes GPU utilization. To adapt to disaggregated attention and FFN modules and minimize data transmission overhead (e.g., token dispatch), MegaScale-Infer provides a high-performance M2N communication library that eliminates unnecessary GPU-to-CPU data copies, group initialization overhead, and GPU synchronization. Experimental results indicate that MegaScale-Infer achieves up to 1.90x higher per-GPU throughput than state-of-the-art solutions.
V2X-LLM: Enhancing V2X Integration and Understanding in Connected Vehicle Corridors
Mar 04, 2025



The advancement of Connected and Automated Vehicles (CAVs) and Vehicle-to-Everything (V2X) offers significant potential for enhancing transportation safety, mobility, and sustainability. However, the integration and analysis of the diverse and voluminous V2X data, including Basic Safety Messages (BSMs) and Signal Phase and Timing (SPaT) data, present substantial challenges, especially on Connected Vehicle Corridors. These challenges include managing large data volumes, ensuring real-time data integration, and understanding complex traffic scenarios. Although these projects have developed an advanced CAV data pipeline that enables real-time communication between vehicles, infrastructure, and other road users for managing connected vehicle and roadside unit (RSU) data, significant hurdles in data comprehension and real-time scenario analysis and reasoning persist. To address these issues, we introduce the V2X-LLM framework, a novel enhancement to the existing CV data pipeline. V2X-LLM leverages Large Language Models (LLMs) to improve the understanding and real-time analysis of V2X data. The framework includes four key tasks: Scenario Explanation, offering detailed narratives of traffic conditions; V2X Data Description, detailing vehicle and infrastructure statuses; State Prediction, forecasting future traffic states; and Navigation Advisory, providing optimized routing instructions. By integrating LLM-driven reasoning with V2X data within the data pipeline, the V2X-LLM framework offers real-time feedback and decision support for traffic management. This integration enhances the accuracy of traffic analysis, safety, and traffic optimization. Demonstrations in a real-world urban corridor highlight the framework's potential to advance intelligent transportation systems.
Real-World Data Inspired Interactive Connected Traffic Scenario Generation
Sep 25, 2024


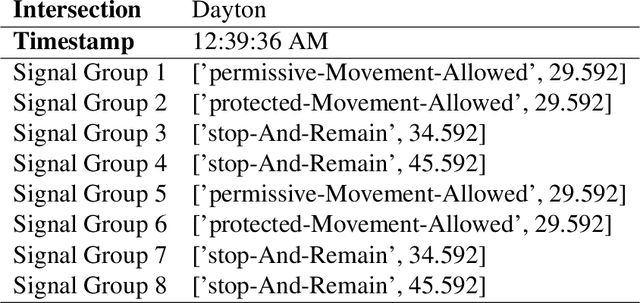
Simulation is a crucial step in ensuring accurate, efficient, and realistic Connected and Autonomous Vehicles (CAVs) testing and validation. As the adoption of CAV accelerates, the integration of real-world data into simulation environments becomes increasingly critical. Among various technologies utilized by CAVs, Vehicle-to-Everything (V2X) communication plays a crucial role in ensuring a seamless transmission of information between CAVs, infrastructure, and other road users. However, most existing studies have focused on developing and testing communication protocols, resource allocation strategies, and data dissemination techniques in V2X. There is a gap where real-world V2X data is integrated into simulations to generate diverse and high-fidelity traffic scenarios. To fulfill this research gap, we leverage real-world Signal Phase and Timing (SPaT) data from Roadside Units (RSUs) to enhance the fidelity of CAV simulations. Moreover, we developed an algorithm that enables Autonomous Vehicles (AVs) to respond dynamically to real-time traffic signal data, simulating realistic V2X communication scenarios. Such high-fidelity simulation environments can generate multimodal data, including trajectory, semantic camera, depth camera, and bird's eye view data for various traffic scenarios. The generated scenarios and data provide invaluable insights into AVs' interactions with traffic infrastructure and other road users. This work aims to bridge the gap between theoretical research and practical deployment of CAVs, facilitating the development of smarter and safer transportation systems.
Untie the Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models
Sep 07, 2024Large language models (LLM) have prioritized expanding the context window from which models can incorporate more information. However, training models to handle long contexts presents significant challenges. These include the scarcity of high-quality natural long-context data, the potential for performance degradation on short-context tasks, and the reduced training efficiency associated with attention mechanisms. In this paper, we introduce Untie the Knots (\textbf{UtK}), a novel data augmentation strategy employed during the continue pre-training phase, designed to efficiently enable LLMs to gain long-context capabilities without the need to modify the existing data mixture. In particular, we chunk the documents, shuffle the chunks, and create a complex and knotted structure of long texts; LLMs are then trained to untie these knots and identify relevant segments within seemingly chaotic token sequences. This approach greatly improves the model's performance by accurately attending to relevant information in long context and the training efficiency is also largely increased. We conduct extensive experiments on models with 7B and 72B parameters, trained on 20 billion tokens, demonstrating that UtK achieves 75\% and 84.5\% accurracy on RULER at 128K context length, significantly outperforming other long context strategies. The trained models will open-source for further research.
Voltage-Controlled Magnetoelectric Devices for Neuromorphic Diffusion Process
Jul 17, 2024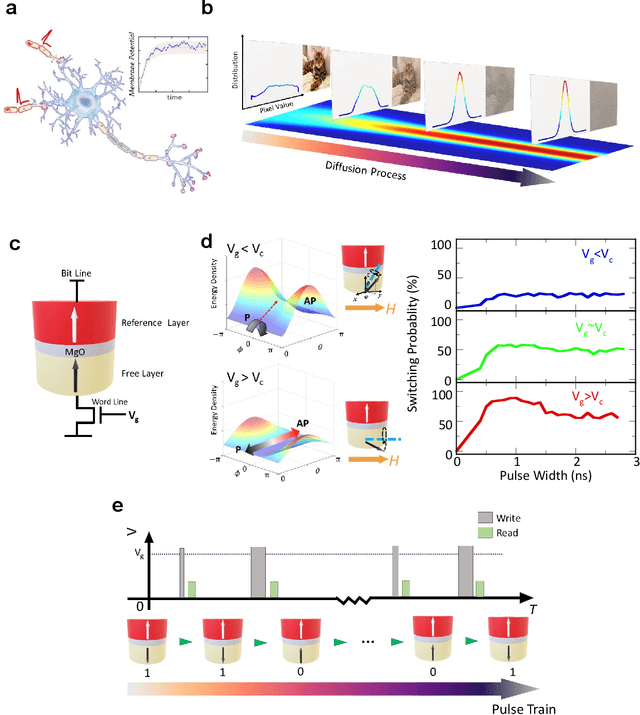
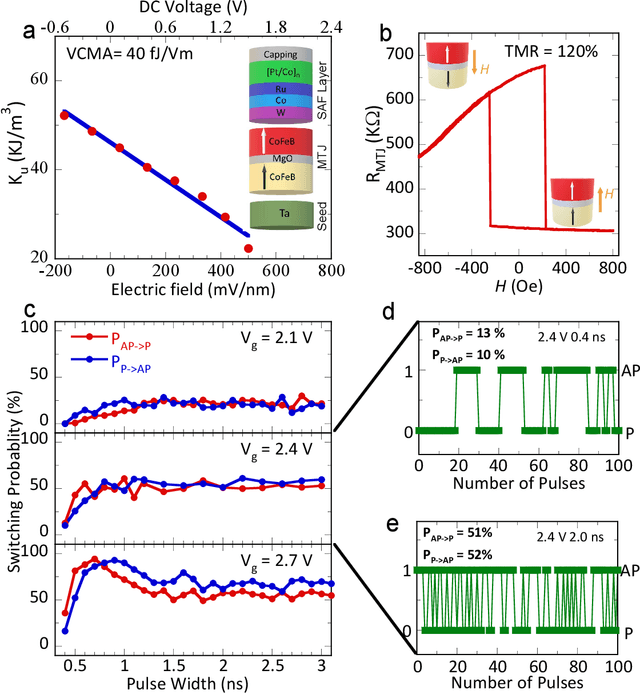
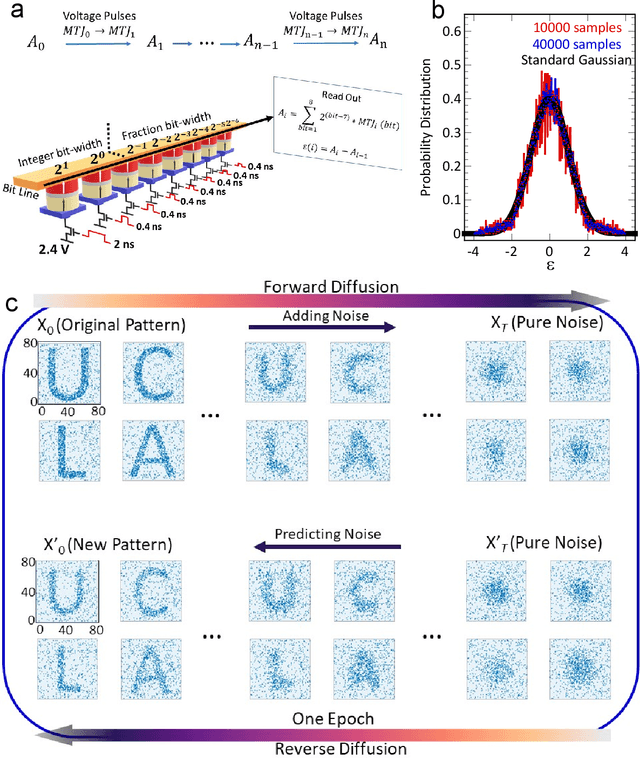
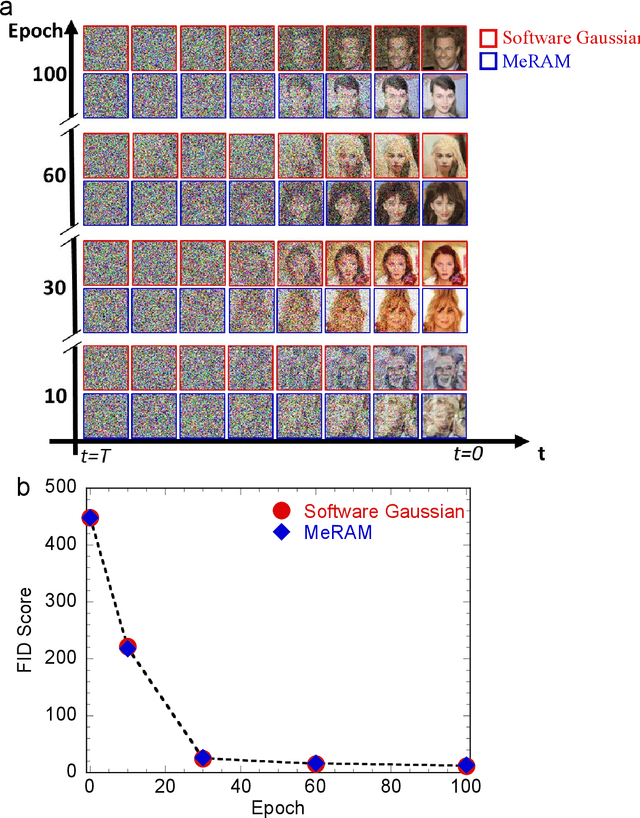
Stochastic diffusion processes are pervasive in nature, from the seemingly erratic Brownian motion to the complex interactions of synaptically-coupled spiking neurons. Recently, drawing inspiration from Langevin dynamics, neuromorphic diffusion models were proposed and have become one of the major breakthroughs in the field of generative artificial intelligence. Unlike discriminative models that have been well developed to tackle classification or regression tasks, diffusion models as well as other generative models such as ChatGPT aim at creating content based upon contexts learned. However, the more complex algorithms of these models result in high computational costs using today's technologies, creating a bottleneck in their efficiency, and impeding further development. Here, we develop a spintronic voltage-controlled magnetoelectric memory hardware for the neuromorphic diffusion process. The in-memory computing capability of our spintronic devices goes beyond current Von Neumann architecture, where memory and computing units are separated. Together with the non-volatility of magnetic memory, we can achieve high-speed and low-cost computing, which is desirable for the increasing scale of generative models in the current era. We experimentally demonstrate that the hardware-based true random diffusion process can be implemented for image generation and achieve comparable image quality to software-based training as measured by the Frechet inception distance (FID) score, achieving ~10^3 better energy-per-bit-per-area over traditional hardware.
On Large Language Models' Hallucination with Regard to Known Facts
Mar 29, 2024



Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88\% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.