 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
No Global Plan in Chain-of-Thought: Uncover the Latent Planning Horizon of LLMs
Feb 02, 2026This work stems from prior complementary observations on the dynamics of Chain-of-Thought (CoT): Large Language Models (LLMs) is shown latent planning of subsequent reasoning prior to CoT emergence, thereby diminishing the significance of explicit CoT; whereas CoT remains critical for tasks requiring multi-step reasoning. To deepen the understanding between LLM's internal states and its verbalized reasoning trajectories, we investigate the latent planning strength of LLMs, through our probing method, Tele-Lens, applying to hidden states across diverse task domains. Our empirical results indicate that LLMs exhibit a myopic horizon, primarily conducting incremental transitions without precise global planning. Leveraging this characteristic, we propose a hypothesis on enhancing uncertainty estimation of CoT, which we validate that a small subset of CoT positions can effectively represent the uncertainty of the entire path. We further underscore the significance of exploiting CoT dynamics, and demonstrate that automatic recognition of CoT bypass can be achieved without performance degradation. Our code, data and models are released at https://github.com/lxucs/tele-lens.
Spava: Accelerating Long-Video Understanding via Sequence-Parallelism-aware Approximate Attention
Jan 29, 2026The efficiency of long-video inference remains a critical bottleneck, mainly due to the dense computation in the prefill stage of Large Multimodal Models (LMMs). Existing methods either compress visual embeddings or apply sparse attention on a single GPU, yielding limited acceleration or degraded performance and restricting LMMs from handling longer, more complex videos. To overcome these issues, we propose Spava, a sequence-parallel framework with optimized attention that accelerates long-video inference across multiple GPUs. By distributing approximate attention, Spava reduces computation and increases parallelism, enabling efficient processing of more visual embeddings without compression and thereby improving task performance. System-level optimizations, such as load balancing and fused forward passes, further unleash the potential of Spava, delivering speedups of 12.72x, 1.70x, and 1.18x over FlashAttn, ZigZagRing, and APB, without notable performance loss. Code available at https://github.com/thunlp/APB
ArrowGEV: Grounding Events in Video via Learning the Arrow of Time
Jan 10, 2026Grounding events in videos serves as a fundamental capability in video analysis. While Vision-Language Models (VLMs) are increasingly employed for this task, existing approaches predominantly train models to associate events with timestamps in the forward video only. This paradigm hinders VLMs from capturing the inherent temporal structure and directionality of events, thereby limiting robustness and generalization. To address this limitation, inspired by the arrow of time in physics, which characterizes the intrinsic directionality of temporal processes, we propose ArrowGEV, a reinforcement learning framework that explicitly models temporal directionality in events to improve both event grounding and temporal directionality understanding in VLMs. Specifically, we categorize events into time-sensitive (e.g., putting down a bag) and time-insensitive (e.g., holding a towel in the left hand). The former denote events whose reversal substantially alters their meaning, while the latter remain semantically unchanged under reversal. For time-sensitive events, ArrowGEV introduces a reward that encourages VLMs to discriminate between forward and backward videos, whereas for time-insensitive events, it enforces consistent grounding across both directions. Extensive experiments demonstrate that ArrowGEV not only improves grounding precision and temporal directionality recognition, but also enhances general video understanding and reasoning ability.
Figure It Out: Improve the Frontier of Reasoning with Executable Visual States
Jan 06, 2026Complex reasoning problems often involve implicit spatial and geometric relationships that are not explicitly encoded in text. While recent reasoning models perform well across many domains, purely text-based reasoning struggles to capture structural constraints in complex settings. In this paper, we introduce FIGR, which integrates executable visual construction into multi-turn reasoning via end-to-end reinforcement learning. Rather than relying solely on textual chains of thought, FIGR externalizes intermediate hypotheses by generating executable code that constructs diagrams within the reasoning loop. An adaptive reward mechanism selectively regulates when visual construction is invoked, enabling more consistent reasoning over latent global properties that are difficult to infer from text alone. Experiments on eight challenging mathematical benchmarks demonstrate that FIGR outperforms strong text-only chain-of-thought baselines, improving the base model by 13.12% on AIME 2025 and 11.00% on BeyondAIME. These results highlight the effectiveness of precise, controllable figure construction of FIGR in enhancing complex reasoning ability.
Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling
Dec 30, 2025Multi-step retrieval-augmented generation (RAG) has become a widely adopted strategy for enhancing large language models (LLMs) on tasks that demand global comprehension and intensive reasoning. Many RAG systems incorporate a working memory module to consolidate retrieved information. However, existing memory designs function primarily as passive storage that accumulates isolated facts for the purpose of condensing the lengthy inputs and generating new sub-queries through deduction. This static nature overlooks the crucial high-order correlations among primitive facts, the compositions of which can often provide stronger guidance for subsequent steps. Therefore, their representational strength and impact on multi-step reasoning and knowledge evolution are limited, resulting in fragmented reasoning and weak global sense-making capacity in extended contexts. We introduce HGMem, a hypergraph-based memory mechanism that extends the concept of memory beyond simple storage into a dynamic, expressive structure for complex reasoning and global understanding. In our approach, memory is represented as a hypergraph whose hyperedges correspond to distinct memory units, enabling the progressive formation of higher-order interactions within memory. This mechanism connects facts and thoughts around the focal problem, evolving into an integrated and situated knowledge structure that provides strong propositions for deeper reasoning in subsequent steps. We evaluate HGMem on several challenging datasets designed for global sense-making. Extensive experiments and in-depth analyses show that our method consistently improves multi-step RAG and substantially outperforms strong baseline systems across diverse tasks.
Figure It Out: Improving the Frontier of Reasoning with Active Visual Thinking
Dec 30, 2025Complex reasoning problems often involve implicit spatial, geometric, and structural relationships that are not explicitly encoded in text. While recent reasoning models have achieved strong performance across many domains, purely text-based reasoning struggles to represent global structural constraints in complex settings. In this paper, we introduce FIGR, which integrates active visual thinking into multi-turn reasoning via end-to-end reinforcement learning. FIGR externalizes intermediate structural hypotheses by constructing visual representations during problem solving. By adaptively regulating when and how visual reasoning should be invoked, FIGR enables more stable and coherent reasoning over global structural properties that are difficult to capture from text alone. Experiments on challenging mathematical reasoning benchmarks demonstrate that FIGR outperforms strong text-only chain-of-thought baselines. In particular, FIGR improves the base model by 13.12% on AIME 2025 and 11.00% on BeyondAIME, highlighting the effectiveness of figure-guided multimodal reasoning in enhancing the stability and reliability of complex reasoning.
Continuous Autoregressive Language Models
Oct 31, 2025The efficiency of large language models (LLMs) is fundamentally limited by their sequential, token-by-token generation process. We argue that overcoming this bottleneck requires a new design axis for LLM scaling: increasing the semantic bandwidth of each generative step. To this end, we introduce Continuous Autoregressive Language Models (CALM), a paradigm shift from discrete next-token prediction to continuous next-vector prediction. CALM uses a high-fidelity autoencoder to compress a chunk of K tokens into a single continuous vector, from which the original tokens can be reconstructed with over 99.9\% accuracy. This allows us to model language as a sequence of continuous vectors instead of discrete tokens, which reduces the number of generative steps by a factor of K. The paradigm shift necessitates a new modeling toolkit; therefore, we develop a comprehensive likelihood-free framework that enables robust training, evaluation, and controllable sampling in the continuous domain. Experiments show that CALM significantly improves the performance-compute trade-off, achieving the performance of strong discrete baselines at a significantly lower computational cost. More importantly, these findings establish next-vector prediction as a powerful and scalable pathway towards ultra-efficient language models. Code: https://github.com/shaochenze/calm. Project: https://shaochenze.github.io/blog/2025/CALM.
Conan: Progressive Learning to Reason Like a Detective over Multi-Scale Visual Evidence
Oct 23, 2025Video reasoning, which requires multi-step deduction across frames, remains a major challenge for multimodal large language models (MLLMs). While reinforcement learning (RL)-based methods enhance reasoning capabilities, they often rely on text-only chains that yield ungrounded or hallucinated conclusions. Conversely, frame-retrieval approaches introduce visual grounding but still struggle with inaccurate evidence localization. To address these challenges, we present Conan, a framework for evidence-grounded multi-step video reasoning. Conan identifies contextual and evidence frames, reasons over cross-frame clues, and adaptively decides when to conclude or explore further. To achieve this, we (1) construct Conan-91K, a large-scale dataset of automatically generated reasoning traces that includes frame identification, evidence reasoning, and action decision, and (2) design a multi-stage progressive cold-start strategy combined with an Identification-Reasoning-Action (AIR) RLVR training framework to jointly enhance multi-step visual reasoning. Extensive experiments on six multi-step reasoning benchmarks demonstrate that Conan surpasses the baseline Qwen2.5-VL-7B-Instruct by an average of over 10% in accuracy, achieving state-of-the-art performance. Furthermore, Conan generalizes effectively to long-video understanding tasks, validating its strong scalability and robustness.
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025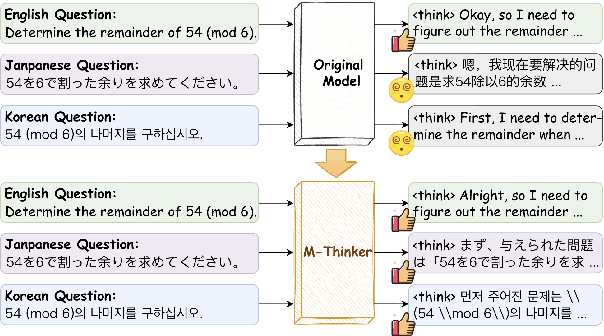
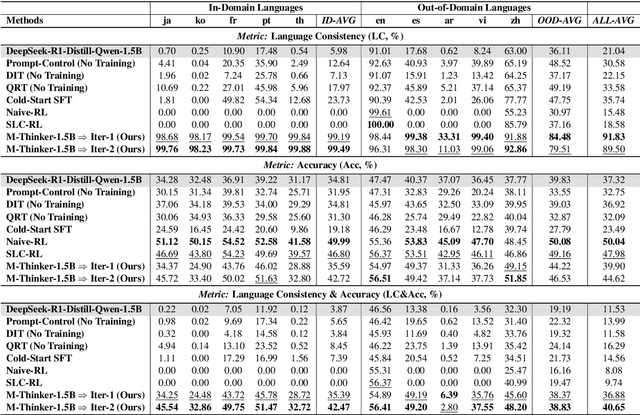
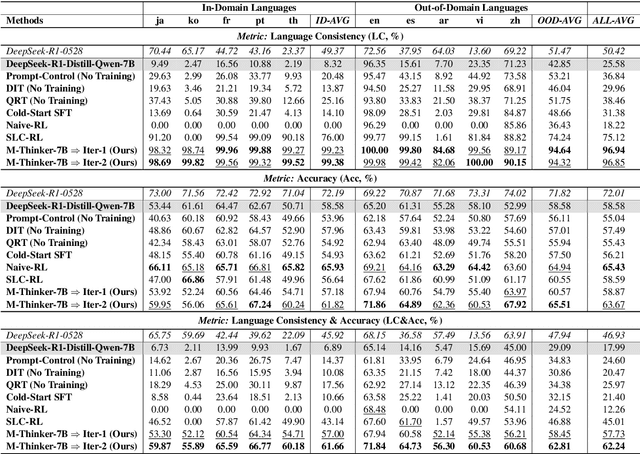

Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.