 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025
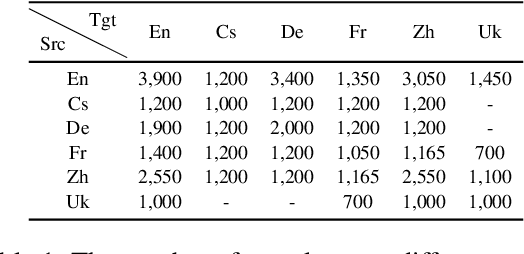
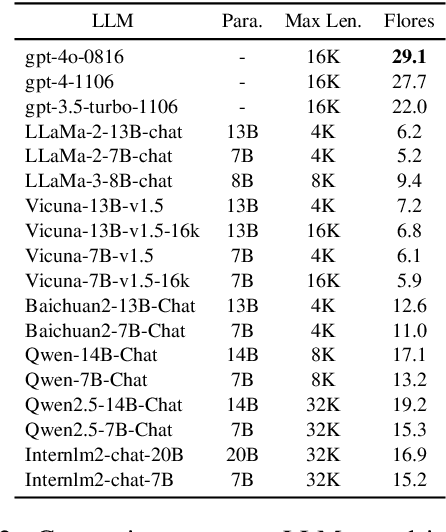
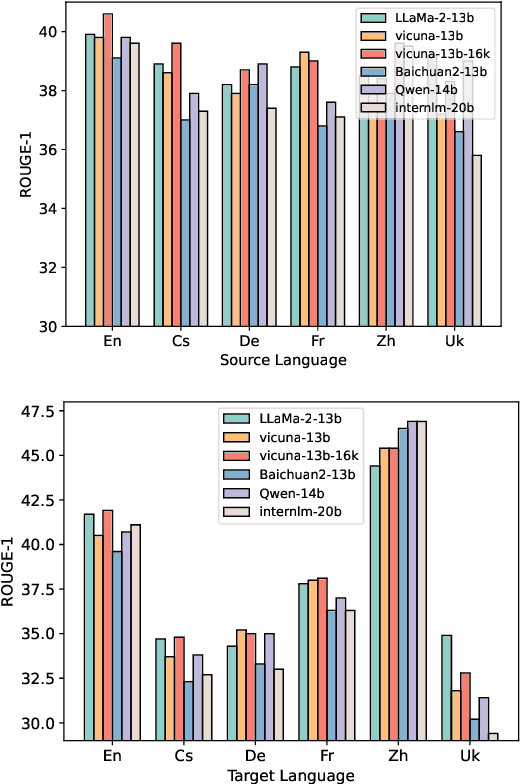
Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
Warmup-Distill: Bridge the Distribution Mismatch between Teacher and Student before Knowledge Distillation
Feb 17, 2025The widespread deployment of Large Language Models (LLMs) is hindered by the high computational demands, making knowledge distillation (KD) crucial for developing compact smaller ones. However, the conventional KD methods endure the distribution mismatch issue between the teacher and student models, leading to the poor performance of distillation. For instance, the widely-used KL-based methods suffer the mode-averaging and mode-collapsing problems, since the mismatched probabitliy distribution between both models. Previous studies mainly optimize this issue via different distance calculations towards the distribution of both models. Unfortunately, the distribution mismatch issue still exists in the early stage of the distillation. Hence, to reduce the impact of distribution mismatch, we propose a simple yet efficient method, named Warmup-Distill, which aligns the distillation of the student to that of the teacher in advance of distillation. Specifically, we first detect the distribution of the student model in practical scenarios with its internal knowledge, and then modify the knowledge with low probability via the teacher as the checker. Consequently, Warmup-Distill aligns the internal student's knowledge to that of the teacher, which expands the distribution of the student with the teacher's, and assists the student model to learn better in the subsequent distillation. Experiments on the seven benchmarks demonstrate that Warmup-Distill could provide a warmup student more suitable for distillation, which outperforms the vanilla student by as least +0.4 averaged score among all benchmarks. Noteably, with the assistance of Warmup-Distill, the distillation on the math task could yield a further improvement, at most +1.9% accuracy.
Dual-Space Knowledge Distillation for Large Language Models
Jun 25, 2024
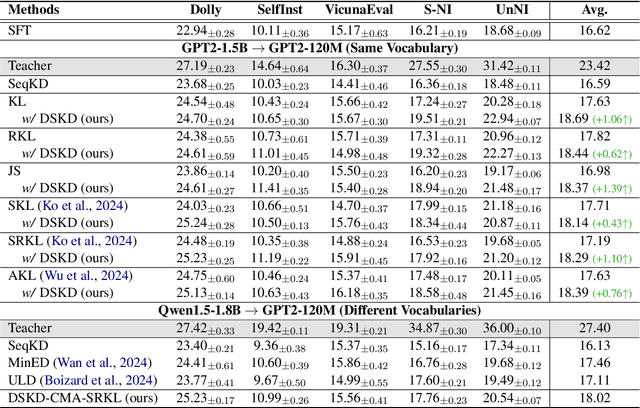


Knowledge distillation (KD) is known as a promising solution to compress large language models (LLMs) via transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the two models so that more knowledge can be transferred. However, in the current white-box KD framework, the output distributions are from the respective output spaces of the two models, using their own prediction heads. We argue that the space discrepancy will lead to low similarity between the teacher model and the student model on both representation and distribution levels. Furthermore, this discrepancy also hinders the KD process between models with different vocabularies, which is common for current LLMs. To address these issues, we propose a dual-space knowledge distillation (DSKD) framework that unifies the output spaces of the two models for KD. On the basis of DSKD, we further develop a cross-model attention mechanism, which can automatically align the representations of the two models with different vocabularies. Thus, our framework is not only compatible with various distance functions for KD (e.g., KL divergence) like the current framework, but also supports KD between any two LLMs regardless of their vocabularies. Experiments on task-agnostic instruction-following benchmarks show that DSKD significantly outperforms the current white-box KD framework with various distance functions, and also surpasses existing KD methods for LLMs with different vocabularies.
Outdated Issue Aware Decoding for Factual Knowledge Editing
Jun 06, 2024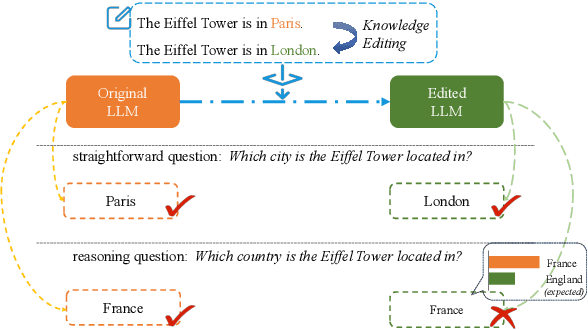
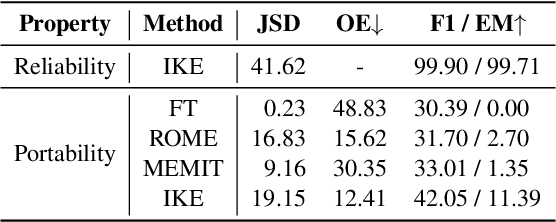
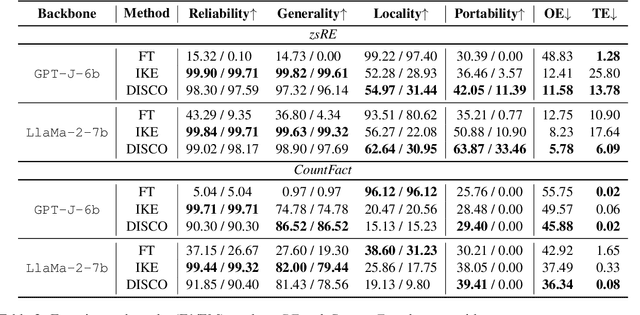
Recently, Knowledge Editing has received increasing attention, since it could update the specific knowledge from outdated ones in pretrained models without re-training. However, as pointed out by recent studies, existing related methods tend to merely memorize the superficial word composition of the edited knowledge, rather than truly learning and absorbing it. Consequently, on the reasoning questions, we discover that existing methods struggle to utilize the edited knowledge to reason the new answer, and tend to retain outdated responses, which are generated by the original models utilizing original knowledge. Nevertheless, the outdated responses are unexpected for the correct answers to reasoning questions, which we named as the outdated issue. To alleviate this issue, in this paper, we propose a simple yet effective decoding strategy, i.e., outDated ISsue aware deCOding (DISCO), to enhance the performance of edited models on reasoning questions. Specifically, we capture the difference in the probability distribution between the original and edited models. Further, we amplify the difference of the token prediction in the edited model to alleviate the outdated issue, and thus enhance the model performance w.r.t the edited knowledge. Experimental results suggest that applying DISCO could enhance edited models to reason, e.g., on reasoning questions, DISCO outperforms the prior SOTA method by 12.99 F1 scores, and reduces the ratio of the outdated issue to 5.78% on the zsRE dataset.
LCS: A Language Converter Strategy for Zero-Shot Neural Machine Translation
Jun 06, 2024
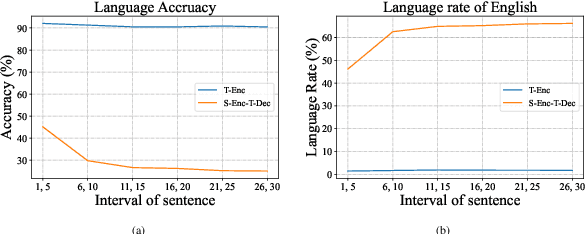
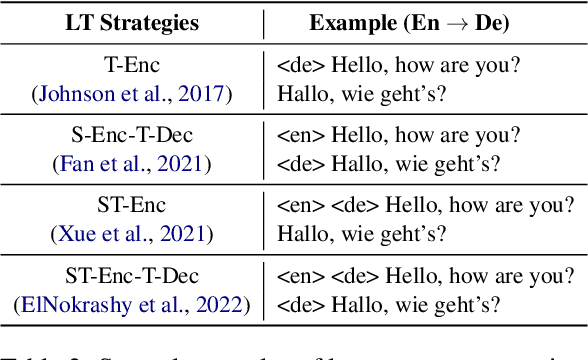
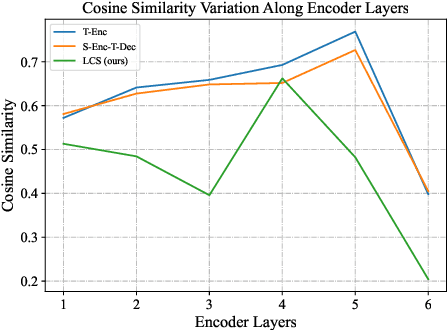
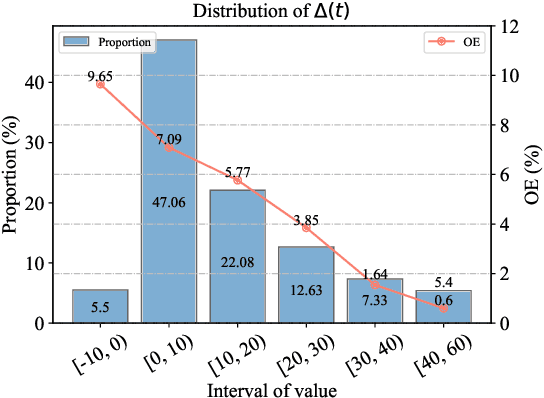
Multilingual neural machine translation models generally distinguish translation directions by the language tag (LT) in front of the source or target sentences. However, current LT strategies cannot indicate the desired target language as expected on zero-shot translation, i.e., the off-target issue. Our analysis reveals that the indication of the target language is sensitive to the placement of the target LT. For example, when placing the target LT on the decoder side, the indication would rapidly degrade along with decoding steps, while placing the target LT on the encoder side would lead to copying or paraphrasing the source input. To address the above issues, we propose a simple yet effective strategy named Language Converter Strategy (LCS). By introducing the target language embedding into the top encoder layers, LCS mitigates confusion in the encoder and ensures stable language indication for the decoder. Experimental results on MultiUN, TED, and OPUS-100 datasets demonstrate that LCS could significantly mitigate the off-target issue, with language accuracy up to 95.28%, 96.21%, and 85.35% meanwhile outperforming the vanilla LT strategy by 3.07, 3,3, and 7.93 BLEU scores on zero-shot translation, respectively.
Cross-Lingual Knowledge Editing in Large Language Models
Sep 16, 2023Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges.