 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-STAR: Multi-Scale Spatiotemporal Autoregression for Human Mobility Modeling
Dec 08, 2025Modeling human mobility is vital for extensive applications such as transportation planning and epidemic modeling. With the rise of the Artificial Intelligence Generated Content (AIGC) paradigm, recent works explore synthetic trajectory generation using autoregressive and diffusion models. While these methods show promise for generating single-day trajectories, they remain limited by inefficiencies in long-term generation (e.g., weekly trajectories) and a lack of explicit spatiotemporal multi-scale modeling. This study proposes Multi-Scale Spatio-Temporal AutoRegression (M-STAR), a new framework that generates long-term trajectories through a coarse-to-fine spatiotemporal prediction process. M-STAR combines a Multi-scale Spatiotemporal Tokenizer that encodes hierarchical mobility patterns with a Transformer-based decoder for next-scale autoregressive prediction. Experiments on two real-world datasets show that M-STAR outperforms existing methods in fidelity and significantly improves generation speed. The data and codes are available at https://github.com/YuxiaoLuo0013/M-STAR.
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025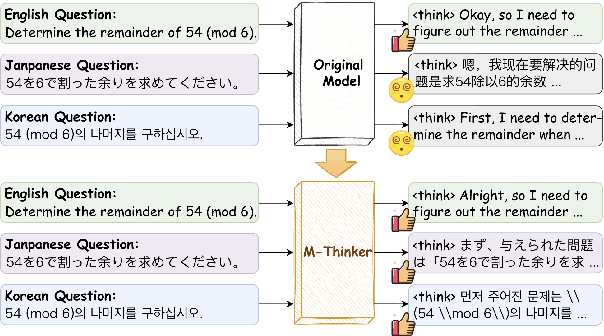
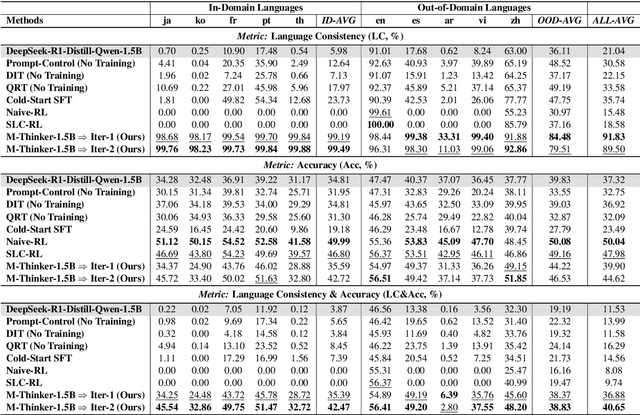
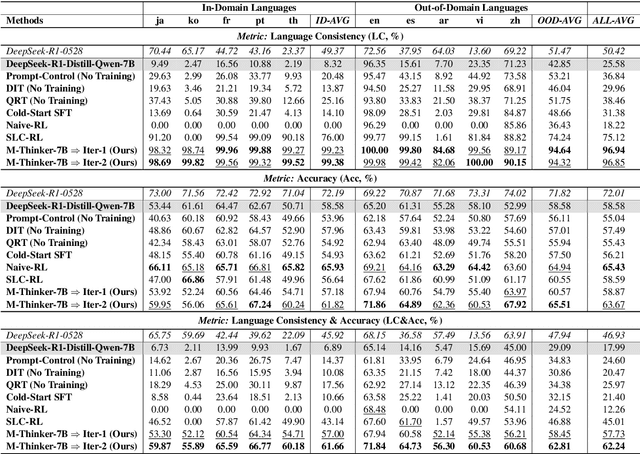

Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.
CM-Align: Consistency-based Multilingual Alignment for Large Language Models
Sep 10, 2025Current large language models (LLMs) generally show a significant performance gap in alignment between English and other languages. To bridge this gap, existing research typically leverages the model's responses in English as a reference to select the best/worst responses in other languages, which are then used for Direct Preference Optimization (DPO) training. However, we argue that there are two limitations in the current methods that result in noisy multilingual preference data and further limited alignment performance: 1) Not all English responses are of high quality, and using a response with low quality may mislead the alignment for other languages. 2) Current methods usually use biased or heuristic approaches to construct multilingual preference pairs. To address these limitations, we design a consistency-based data selection method to construct high-quality multilingual preference data for improving multilingual alignment (CM-Align). Specifically, our method includes two parts: consistency-guided English reference selection and cross-lingual consistency-based multilingual preference data construction. Experimental results on three LLMs and three common tasks demonstrate the effectiveness and superiority of our method, which further indicates the necessity of constructing high-quality preference data.
Less, but Better: Efficient Multilingual Expansion for LLMs via Layer-wise Mixture-of-Experts
May 28, 2025Continually expanding new languages for existing large language models (LLMs) is a promising yet challenging approach to building powerful multilingual LLMs. The biggest challenge is to make the model continuously learn new languages while preserving the proficient ability of old languages. To achieve this, recent work utilizes the Mixture-of-Experts (MoE) architecture to expand new languages by adding new experts and avoid catastrophic forgetting of old languages by routing corresponding tokens to the original model backbone (old experts). Although intuitive, this kind of method is parameter-costly when expanding new languages and still inevitably impacts the performance of old languages. To address these limitations, we analyze the language characteristics of different layers in LLMs and propose a layer-wise expert allocation algorithm (LayerMoE) to determine the appropriate number of new experts for each layer. Specifically, we find different layers in LLMs exhibit different representation similarities between languages and then utilize the similarity as the indicator to allocate experts for each layer, i.e., the higher similarity, the fewer experts. Additionally, to further mitigate the forgetting of old languages, we add a classifier in front of the router network on the layers with higher similarity to guide the routing of old language tokens. Experimental results show that our method outperforms the previous state-of-the-art baseline with 60% fewer experts in the single-expansion setting and with 33.3% fewer experts in the lifelong-expansion setting, demonstrating the effectiveness of our method.
A Dual-Space Framework for General Knowledge Distillation of Large Language Models
Apr 15, 2025Knowledge distillation (KD) is a promising solution to compress large language models (LLMs) by transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the teacher model and the student model to transfer more information. However, we reveal that the current white-box KD framework exhibits two limitations: a) bridging probability distributions from different output spaces will limit the similarity between the teacher model and the student model; b) this framework cannot be applied to LLMs with different vocabularies. One of the root causes for these limitations is that the distributions from the teacher and the student for KD are output by different prediction heads, which yield distributions in different output spaces and dimensions. Therefore, in this paper, we propose a dual-space knowledge distillation (DSKD) framework that unifies the prediction heads of the teacher and the student models for KD. Specifically, we first introduce two projectors with ideal initialization to project the teacher/student hidden states into the student/teacher representation spaces. After this, the hidden states from different models can share the same head and unify the output spaces of the distributions. Furthermore, we develop an exact token alignment (ETA) algorithm to align the same tokens in two differently-tokenized sequences. Based on the above, our DSKD framework is a general KD framework that supports both off-policy and on-policy KD, and KD between any two LLMs regardless of their vocabularies. Extensive experiments on instruction-following, mathematical reasoning, and code generation benchmarks show that DSKD significantly outperforms existing methods based on the current white-box KD framework and surpasses other cross-tokenizer KD methods for LLMs with different vocabularies.
AlignDistil: Token-Level Language Model Alignment as Adaptive Policy Distillation
Mar 04, 2025In modern large language models (LLMs), LLM alignment is of crucial importance and is typically achieved through methods such as reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO). However, in most existing methods for LLM alignment, all tokens in the response are optimized using a sparse, response-level reward or preference annotation. The ignorance of token-level rewards may erroneously punish high-quality tokens or encourage low-quality tokens, resulting in suboptimal performance and slow convergence speed. To address this issue, we propose AlignDistil, an RLHF-equivalent distillation method for token-level reward optimization. Specifically, we introduce the reward learned by DPO into the RLHF objective and theoretically prove the equivalence between this objective and a token-level distillation process, where the teacher distribution linearly combines the logits from the DPO model and a reference model. On this basis, we further bridge the accuracy gap between the reward from the DPO model and the pure reward model, by building a contrastive DPO reward with a normal and a reverse DPO model. Moreover, to avoid under- and over-optimization on different tokens, we design a token adaptive logit extrapolation mechanism to construct an appropriate teacher distribution for each token. Experimental results demonstrate the superiority of our AlignDistil over existing methods and showcase fast convergence due to its token-level distributional reward optimization.
Dual-Space Knowledge Distillation for Large Language Models
Jun 25, 2024
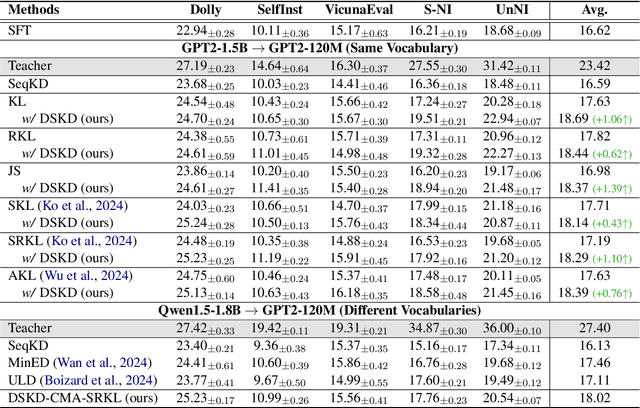


Knowledge distillation (KD) is known as a promising solution to compress large language models (LLMs) via transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the two models so that more knowledge can be transferred. However, in the current white-box KD framework, the output distributions are from the respective output spaces of the two models, using their own prediction heads. We argue that the space discrepancy will lead to low similarity between the teacher model and the student model on both representation and distribution levels. Furthermore, this discrepancy also hinders the KD process between models with different vocabularies, which is common for current LLMs. To address these issues, we propose a dual-space knowledge distillation (DSKD) framework that unifies the output spaces of the two models for KD. On the basis of DSKD, we further develop a cross-model attention mechanism, which can automatically align the representations of the two models with different vocabularies. Thus, our framework is not only compatible with various distance functions for KD (e.g., KL divergence) like the current framework, but also supports KD between any two LLMs regardless of their vocabularies. Experiments on task-agnostic instruction-following benchmarks show that DSKD significantly outperforms the current white-box KD framework with various distance functions, and also surpasses existing KD methods for LLMs with different vocabularies.
Multilingual Knowledge Editing with Language-Agnostic Factual Neurons
Jun 24, 2024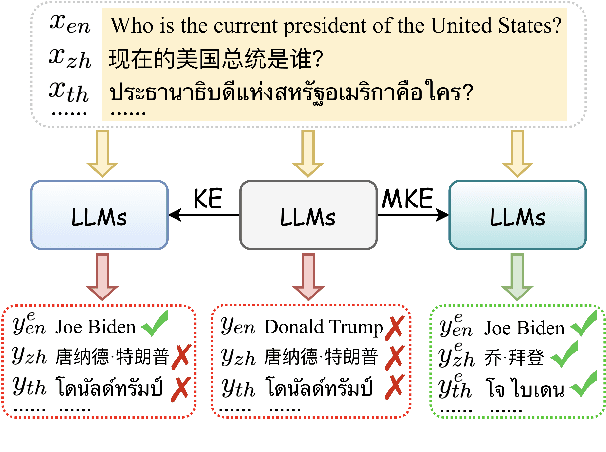
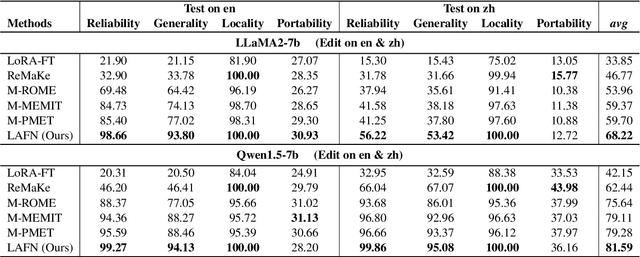
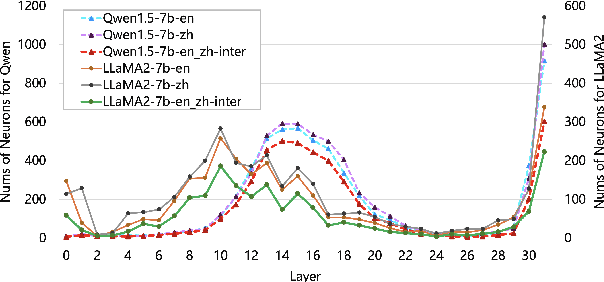
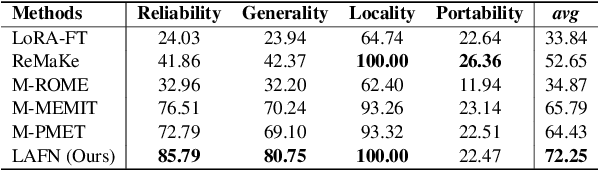
Multilingual knowledge editing (MKE) aims to simultaneously revise factual knowledge across multilingual languages within large language models (LLMs). However, most existing MKE methods just adapt existing monolingual editing methods to multilingual scenarios, overlooking the deep semantic connections of the same factual knowledge between different languages, thereby limiting edit performance. To address this issue, we first investigate how LLMs represent multilingual factual knowledge and discover that the same factual knowledge in different languages generally activates a shared set of neurons, which we call language-agnostic factual neurons. These neurons represent the semantic connections between multilingual knowledge and are mainly located in certain layers. Inspired by this finding, we propose a new MKE method by locating and modifying Language-Agnostic Factual Neurons (LAFN) to simultaneously edit multilingual knowledge. Specifically, we first generate a set of paraphrases for each multilingual knowledge to be edited to precisely locate the corresponding language-agnostic factual neurons. Then we optimize the update values for modifying these located neurons to achieve simultaneous modification of the same factual knowledge in multiple languages. Experimental results on Bi-ZsRE and MzsRE benchmarks demonstrate that our method outperforms existing MKE methods and achieves remarkable edit performance, indicating the importance of considering the semantic connections among multilingual knowledge.
Revisiting Knowledge Distillation under Distribution Shift
Jan 07, 2024Knowledge distillation transfers knowledge from large models into small models, and has recently made remarkable achievements. However, few studies has investigated the mechanism of knowledge distillation against distribution shift. Distribution shift refers to the data distribution drifts between training and testing phases. In this paper, we reconsider the paradigm of knowledge distillation by reformulating the objective function in shift situations. Under the real scenarios, we propose a unified and systematic framework to benchmark knowledge distillation against two general distributional shifts including diversity and correlation shift. The evaluation benchmark covers more than 30 methods from algorithmic, data-driven, and optimization perspectives for five benchmark datasets. Overall, we conduct extensive experiments on the student model. We reveal intriguing observations of poor teaching performance under distribution shifts; in particular, complex algorithms and data augmentation offer limited gains in many cases.
Are All Unseen Data Out-of-Distribution?
Jan 02, 2024



Distributions of unseen data have been all treated as out-of-distribution (OOD), making their generalization a significant challenge. Much evidence suggests that the size increase of training data can monotonically decrease generalization errors in test data. However, this is not true from other observations and analysis. In particular, when the training data have multiple source domains and the test data contain distribution drifts, then not all generalization errors on the test data decrease monotonically with the increasing size of training data. Such a non-decreasing phenomenon is formally investigated under a linear setting with empirical verification across varying visual benchmarks. Motivated by these results, we redefine the OOD data as a type of data outside the convex hull of the training domains and prove a new generalization bound based on this new definition. It implies that the effectiveness of a well-trained model can be guaranteed for the unseen data that is within the convex hull of the training domains. But, for some data beyond the convex hull, a non-decreasing error trend can happen. Therefore, we investigate the performance of popular strategies such as data augmentation and pre-training to overcome this issue. Moreover, we propose a novel reinforcement learning selection algorithm in the source domains only that can deliver superior performance over the baseline methods.