 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation
Jan 21, 2026Multilingual retrieval-augmented generation (MRAG) requires models to effectively acquire and integrate beneficial external knowledge from multilingual collections. However, most existing studies employ a unitive process where queries of equivalent semantics across different languages are processed through a single-turn retrieval and subsequent optimization. Such a ``one-size-fits-all'' strategy is often suboptimal in multilingual settings, as the models occur to knowledge bias and conflict during the interaction with the search engine. To alleviate the issues, we propose LcRL, a multilingual search-augmented reinforcement learning framework that integrates a language-coupled Group Relative Policy Optimization into the policy and reward models. We adopt the language-coupled group sampling in the rollout module to reduce knowledge bias, and regularize an auxiliary anti-consistency penalty in the reward models to mitigate the knowledge conflict. Experimental results demonstrate that LcRL not only achieves competitive performance but is also appropriate for various practical scenarios such as constrained training data and retrieval over collections encompassing a large number of languages. Our code is available at https://github.com/Cherry-qwq/LcRL-Open.
When Helpers Become Hazards: A Benchmark for Analyzing Multimodal LLM-Powered Safety in Daily Life
Jan 07, 2026As Multimodal Large Language Models (MLLMs) become an indispensable assistant in human life, the unsafe content generated by MLLMs poses a danger to human behavior, perpetually overhanging human society like a sword of Damocles. To investigate and evaluate the safety impact of MLLMs responses on human behavior in daily life, we introduce SaLAD, a multimodal safety benchmark which contains 2,013 real-world image-text samples across 10 common categories, with a balanced design covering both unsafe scenarios and cases of oversensitivity. It emphasizes realistic risk exposure, authentic visual inputs, and fine-grained cross-modal reasoning, ensuring that safety risks cannot be inferred from text alone. We further propose a safety-warning-based evaluation framework that encourages models to provide clear and informative safety warnings, rather than generic refusals. Results on 18 MLLMs demonstrate that the top-performing models achieve a safe response rate of only 57.2% on unsafe queries. Moreover, even popular safety alignment methods limit effectiveness of the models in our scenario, revealing the vulnerabilities of current MLLMs in identifying dangerous behaviors in daily life. Our dataset is available at https://github.com/xinyuelou/SaLAD.
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025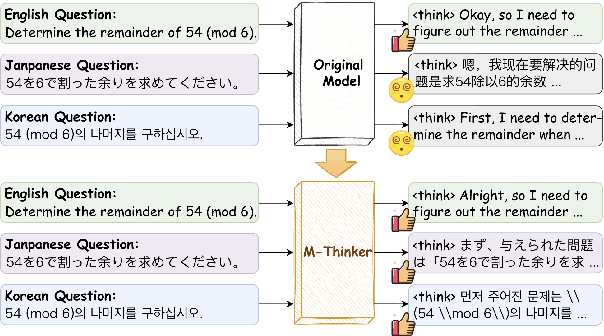
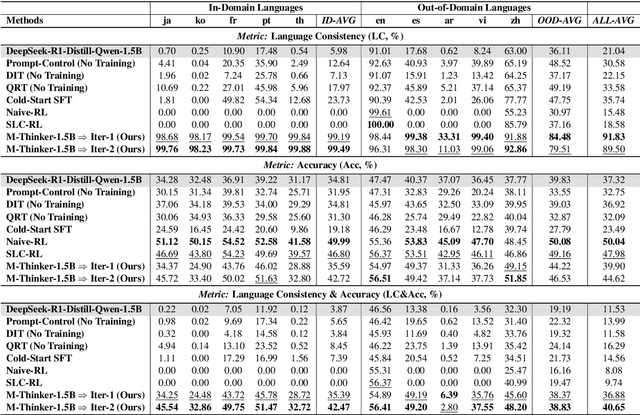
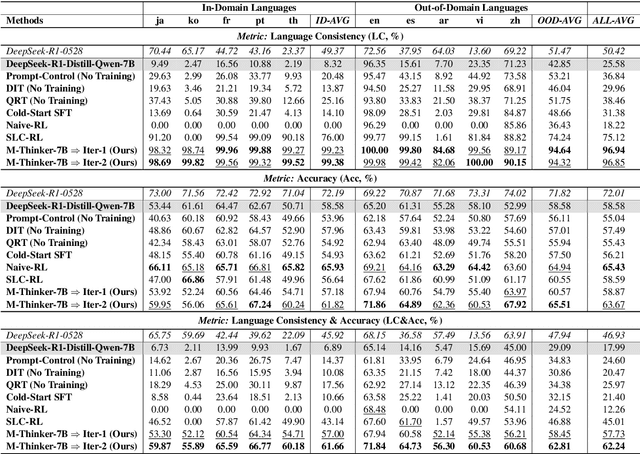

Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.
Boosting Data Utilization for Multilingual Dense Retrieval
Sep 11, 2025Multilingual dense retrieval aims to retrieve relevant documents across different languages based on a unified retriever model. The challenge lies in aligning representations of different languages in a shared vector space. The common practice is to fine-tune the dense retriever via contrastive learning, whose effectiveness highly relies on the quality of the negative sample and the efficacy of mini-batch data. Different from the existing studies that focus on developing sophisticated model architecture, we propose a method to boost data utilization for multilingual dense retrieval by obtaining high-quality hard negative samples and effective mini-batch data. The extensive experimental results on a multilingual retrieval benchmark, MIRACL, with 16 languages demonstrate the effectiveness of our method by outperforming several existing strong baselines.
CM-Align: Consistency-based Multilingual Alignment for Large Language Models
Sep 10, 2025Current large language models (LLMs) generally show a significant performance gap in alignment between English and other languages. To bridge this gap, existing research typically leverages the model's responses in English as a reference to select the best/worst responses in other languages, which are then used for Direct Preference Optimization (DPO) training. However, we argue that there are two limitations in the current methods that result in noisy multilingual preference data and further limited alignment performance: 1) Not all English responses are of high quality, and using a response with low quality may mislead the alignment for other languages. 2) Current methods usually use biased or heuristic approaches to construct multilingual preference pairs. To address these limitations, we design a consistency-based data selection method to construct high-quality multilingual preference data for improving multilingual alignment (CM-Align). Specifically, our method includes two parts: consistency-guided English reference selection and cross-lingual consistency-based multilingual preference data construction. Experimental results on three LLMs and three common tasks demonstrate the effectiveness and superiority of our method, which further indicates the necessity of constructing high-quality preference data.
Less, but Better: Efficient Multilingual Expansion for LLMs via Layer-wise Mixture-of-Experts
May 28, 2025Continually expanding new languages for existing large language models (LLMs) is a promising yet challenging approach to building powerful multilingual LLMs. The biggest challenge is to make the model continuously learn new languages while preserving the proficient ability of old languages. To achieve this, recent work utilizes the Mixture-of-Experts (MoE) architecture to expand new languages by adding new experts and avoid catastrophic forgetting of old languages by routing corresponding tokens to the original model backbone (old experts). Although intuitive, this kind of method is parameter-costly when expanding new languages and still inevitably impacts the performance of old languages. To address these limitations, we analyze the language characteristics of different layers in LLMs and propose a layer-wise expert allocation algorithm (LayerMoE) to determine the appropriate number of new experts for each layer. Specifically, we find different layers in LLMs exhibit different representation similarities between languages and then utilize the similarity as the indicator to allocate experts for each layer, i.e., the higher similarity, the fewer experts. Additionally, to further mitigate the forgetting of old languages, we add a classifier in front of the router network on the layers with higher similarity to guide the routing of old language tokens. Experimental results show that our method outperforms the previous state-of-the-art baseline with 60% fewer experts in the single-expansion setting and with 33.3% fewer experts in the lifelong-expansion setting, demonstrating the effectiveness of our method.
Multilingual Collaborative Defense for Large Language Models
May 17, 2025The robustness and security of large language models (LLMs) has become a prominent research area. One notable vulnerability is the ability to bypass LLM safeguards by translating harmful queries into rare or underrepresented languages, a simple yet effective method of "jailbreaking" these models. Despite the growing concern, there has been limited research addressing the safeguarding of LLMs in multilingual scenarios, highlighting an urgent need to enhance multilingual safety. In this work, we investigate the correlation between various attack features across different languages and propose Multilingual Collaborative Defense (MCD), a novel learning method that optimizes a continuous, soft safety prompt automatically to facilitate multilingual safeguarding of LLMs. The MCD approach offers three advantages: First, it effectively improves safeguarding performance across multiple languages. Second, MCD maintains strong generalization capabilities while minimizing false refusal rates. Third, MCD mitigates the language safety misalignment caused by imbalances in LLM training corpora. To evaluate the effectiveness of MCD, we manually construct multilingual versions of commonly used jailbreak benchmarks, such as MaliciousInstruct and AdvBench, to assess various safeguarding methods. Additionally, we introduce these datasets in underrepresented (zero-shot) languages to verify the language transferability of MCD. The results demonstrate that MCD outperforms existing approaches in safeguarding against multilingual jailbreak attempts while also exhibiting strong language transfer capabilities. Our code is available at https://github.com/HLiang-Lee/MCD.
Think in Safety: Unveiling and Mitigating Safety Alignment Collapse in Multimodal Large Reasoning Model
May 10, 2025The rapid development of multimodal large reasoning models (MLRMs) has demonstrated broad application potential, yet their safety and reliability remain critical concerns that require systematic exploration. To address this gap, we conduct a comprehensive and systematic safety evaluation of 11 MLRMs across 5 benchmarks and unveil prevalent safety degradation phenomena in most advanced models. Moreover, our analysis reveals distinct safety patterns across different benchmarks: significant safety degradation is observed across jailbreak robustness benchmarks, whereas safety-awareness benchmarks demonstrate less pronounced degradation. In particular, a long thought process in some scenarios even enhances safety performance. Therefore, it is a potential approach to addressing safety issues in MLRMs by leveraging the intrinsic reasoning capabilities of the model to detect unsafe intent. To operationalize this insight, we construct a multimodal tuning dataset that incorporates a safety-oriented thought process. Experimental results from fine-tuning existing MLRMs with this dataset effectively enhances the safety on both jailbreak robustness and safety-awareness benchmarks. This study provides a new perspective for developing safe MLRMs. Our dataset is available at https://github.com/xinyuelou/Think-in-Safety.
SToLa: Self-Adaptive Touch-Language Framework with Tactile Commonsense Reasoning in Open-Ended Scenarios
May 07, 2025This paper explores the challenges of integrating tactile sensing into intelligent systems for multimodal reasoning, particularly in enabling commonsense reasoning about the open-ended physical world. We identify two key challenges: modality discrepancy, where existing large touch-language models often treat touch as a mere sub-modality of language, and open-ended tactile data scarcity, where current datasets lack the diversity, open-endness and complexity needed for reasoning. To overcome these challenges, we introduce SToLa, a Self-Adaptive Touch-Language framework. SToLa utilizes Mixture of Experts (MoE) to dynamically process, unify, and manage tactile and language modalities, capturing their unique characteristics. Crucially, we also present a comprehensive tactile commonsense reasoning dataset and benchmark featuring free-form questions and responses, 8 physical properties, 4 interactive characteristics, and diverse commonsense knowledge. Experiments show SToLa exhibits competitive performance compared to existing models on the PhysiCLeAR benchmark and self-constructed datasets, proving the effectiveness of the Mixture of Experts architecture in multimodal management and the performance advantages for open-scenario tactile commonsense reasoning tasks.
DMDTEval: An Evaluation and Analysis of LLMs on Disambiguation in Multi-domain Translation
Apr 29, 2025Currently, Large Language Models (LLMs) have achieved remarkable results in machine translation. However, their performance in multi-domain translation (MDT) is less satisfactory; the meanings of words can vary across different domains, highlighting the significant ambiguity inherent in MDT. Therefore, evaluating the disambiguation ability of LLMs in MDT remains an open problem. To this end, we present an evaluation and analysis of LLMs on disambiguation in multi-domain translation (DMDTEval), our systematic evaluation framework consisting of three critical aspects: (1) we construct a translation test set with multi-domain ambiguous word annotation, (2) we curate a diverse set of disambiguation prompting templates, and (3) we design precise disambiguation metrics, and study the efficacy of various prompting strategies on multiple state-of-the-art LLMs. Our extensive experiments reveal a number of crucial findings that we believe will pave the way and also facilitate further research in the critical area of improving the disambiguation of LLMs.