 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025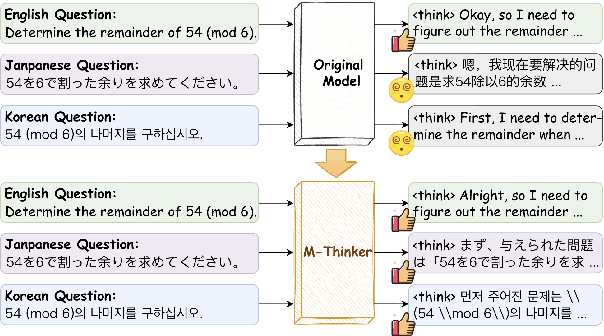
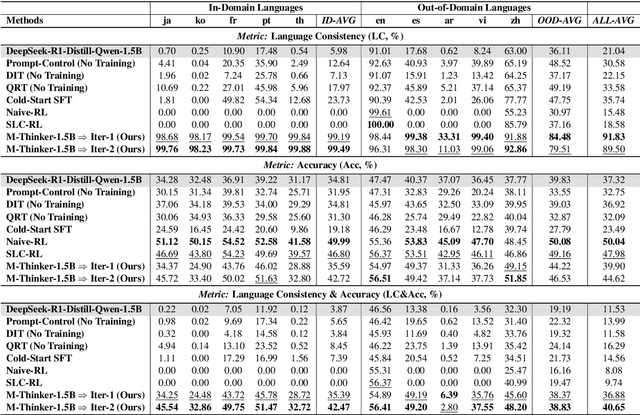
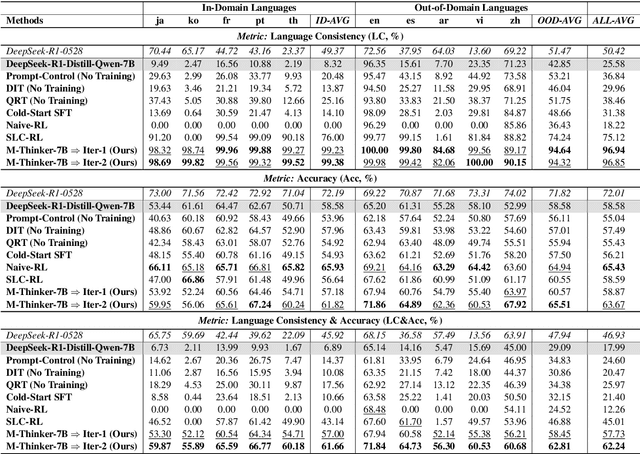

Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.
CM-Align: Consistency-based Multilingual Alignment for Large Language Models
Sep 10, 2025Current large language models (LLMs) generally show a significant performance gap in alignment between English and other languages. To bridge this gap, existing research typically leverages the model's responses in English as a reference to select the best/worst responses in other languages, which are then used for Direct Preference Optimization (DPO) training. However, we argue that there are two limitations in the current methods that result in noisy multilingual preference data and further limited alignment performance: 1) Not all English responses are of high quality, and using a response with low quality may mislead the alignment for other languages. 2) Current methods usually use biased or heuristic approaches to construct multilingual preference pairs. To address these limitations, we design a consistency-based data selection method to construct high-quality multilingual preference data for improving multilingual alignment (CM-Align). Specifically, our method includes two parts: consistency-guided English reference selection and cross-lingual consistency-based multilingual preference data construction. Experimental results on three LLMs and three common tasks demonstrate the effectiveness and superiority of our method, which further indicates the necessity of constructing high-quality preference data.
Less, but Better: Efficient Multilingual Expansion for LLMs via Layer-wise Mixture-of-Experts
May 28, 2025Continually expanding new languages for existing large language models (LLMs) is a promising yet challenging approach to building powerful multilingual LLMs. The biggest challenge is to make the model continuously learn new languages while preserving the proficient ability of old languages. To achieve this, recent work utilizes the Mixture-of-Experts (MoE) architecture to expand new languages by adding new experts and avoid catastrophic forgetting of old languages by routing corresponding tokens to the original model backbone (old experts). Although intuitive, this kind of method is parameter-costly when expanding new languages and still inevitably impacts the performance of old languages. To address these limitations, we analyze the language characteristics of different layers in LLMs and propose a layer-wise expert allocation algorithm (LayerMoE) to determine the appropriate number of new experts for each layer. Specifically, we find different layers in LLMs exhibit different representation similarities between languages and then utilize the similarity as the indicator to allocate experts for each layer, i.e., the higher similarity, the fewer experts. Additionally, to further mitigate the forgetting of old languages, we add a classifier in front of the router network on the layers with higher similarity to guide the routing of old language tokens. Experimental results show that our method outperforms the previous state-of-the-art baseline with 60% fewer experts in the single-expansion setting and with 33.3% fewer experts in the lifelong-expansion setting, demonstrating the effectiveness of our method.
THOR-MoE: Hierarchical Task-Guided and Context-Responsive Routing for Neural Machine Translation
May 20, 2025The sparse Mixture-of-Experts (MoE) has achieved significant progress for neural machine translation (NMT). However, there exist two limitations in current MoE solutions which may lead to sub-optimal performance: 1) they directly use the task knowledge of NMT into MoE (\emph{e.g.}, domain/linguistics-specific knowledge), which are generally unavailable at practical application and neglect the naturally grouped domain/linguistic properties; 2) the expert selection only depends on the localized token representation without considering the context, which fully grasps the state of each token in a global view. To address the above limitations, we propose THOR-MoE via arming the MoE with hierarchical task-guided and context-responsive routing policies. Specifically, it 1) firstly predicts the domain/language label and then extracts mixed domain/language representation to allocate task-level experts in a hierarchical manner; 2) injects the context information to enhance the token routing from the pre-selected task-level experts set, which can help each token to be accurately routed to more specialized and suitable experts. Extensive experiments on multi-domain translation and multilingual translation benchmarks with different architectures consistently demonstrate the superior performance of THOR-MoE. Additionally, the THOR-MoE operates as a plug-and-play module compatible with existing Top-$k$~\cite{shazeer2017} and Top-$p$~\cite{huang-etal-2024-harder} routing schemes, ensuring broad applicability across diverse MoE architectures. For instance, compared with vanilla Top-$p$~\cite{huang-etal-2024-harder} routing, the context-aware manner can achieve an average improvement of 0.75 BLEU with less than 22\% activated parameters on multi-domain translation tasks.
SlangDIT: Benchmarking LLMs in Interpretative Slang Translation
May 20, 2025The challenge of slang translation lies in capturing context-dependent semantic extensions, as slang terms often convey meanings beyond their literal interpretation. While slang detection, explanation, and translation have been studied as isolated tasks in the era of large language models (LLMs), their intrinsic interdependence remains underexplored. The main reason is lacking of a benchmark where the two tasks can be a prerequisite for the third one, which can facilitate idiomatic translation. In this paper, we introduce the interpretative slang translation task (named SlangDIT) consisting of three sub-tasks: slang detection, cross-lingual slang explanation, and slang translation within the current context, aiming to generate more accurate translation with the help of slang detection and slang explanation. To this end, we construct a SlangDIT dataset, containing over 25k English-Chinese sentence pairs. Each source sentence mentions at least one slang term and is labeled with corresponding cross-lingual slang explanation. Based on the benchmark, we propose a deep thinking model, named SlangOWL. It firstly identifies whether the sentence contains a slang, and then judges whether the slang is polysemous and analyze its possible meaning. Further, the SlangOWL provides the best explanation of the slang term targeting on the current context. Finally, according to the whole thought, the SlangOWL offers a suitable translation. Our experiments on LLMs (\emph{e.g.}, Qwen2.5 and LLama-3.1), show that our deep thinking approach indeed enhances the performance of LLMs where the proposed SLangOWL significantly surpasses the vanilla models and supervised fine-tuned models without thinking.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025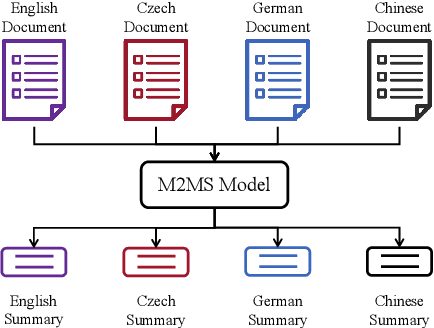
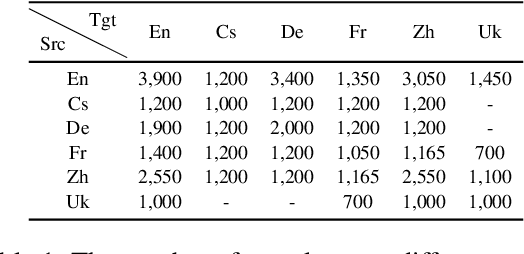
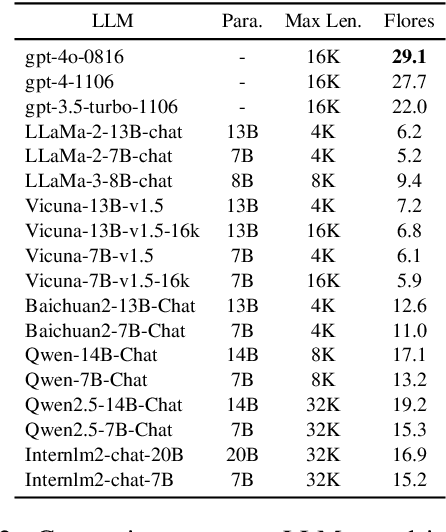
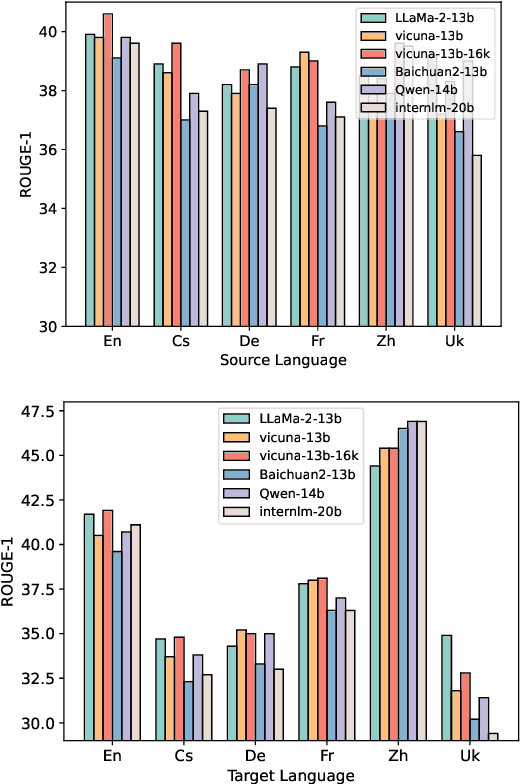
Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
A Dual-Space Framework for General Knowledge Distillation of Large Language Models
Apr 15, 2025Knowledge distillation (KD) is a promising solution to compress large language models (LLMs) by transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the teacher model and the student model to transfer more information. However, we reveal that the current white-box KD framework exhibits two limitations: a) bridging probability distributions from different output spaces will limit the similarity between the teacher model and the student model; b) this framework cannot be applied to LLMs with different vocabularies. One of the root causes for these limitations is that the distributions from the teacher and the student for KD are output by different prediction heads, which yield distributions in different output spaces and dimensions. Therefore, in this paper, we propose a dual-space knowledge distillation (DSKD) framework that unifies the prediction heads of the teacher and the student models for KD. Specifically, we first introduce two projectors with ideal initialization to project the teacher/student hidden states into the student/teacher representation spaces. After this, the hidden states from different models can share the same head and unify the output spaces of the distributions. Furthermore, we develop an exact token alignment (ETA) algorithm to align the same tokens in two differently-tokenized sequences. Based on the above, our DSKD framework is a general KD framework that supports both off-policy and on-policy KD, and KD between any two LLMs regardless of their vocabularies. Extensive experiments on instruction-following, mathematical reasoning, and code generation benchmarks show that DSKD significantly outperforms existing methods based on the current white-box KD framework and surpasses other cross-tokenizer KD methods for LLMs with different vocabularies.
DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought
Dec 23, 2024



Recently, O1-like models have emerged as representative examples, illustrating the effectiveness of long chain-of-thought (CoT) in reasoning tasks such as math and coding tasks. In this paper, we introduce DRT-o1, an attempt to bring the success of long CoT to neural machine translation (MT). Specifically, in view of the literature books that might involve similes and metaphors, translating these texts to a target language is very difficult in practice due to cultural differences. In such cases, literal translation often fails to convey the intended meaning effectively. Even for professional human translators, considerable thought must be given to preserving semantics throughout the translation process. To simulate LLMs' long thought ability in MT, we first mine sentences containing similes or metaphors from existing literature books, and then develop a multi-agent framework to translate these sentences via long thought. In the multi-agent framework, a translator is used to iteratively translate the source sentence under the suggestions provided by an advisor. To ensure the effectiveness of the long thoughts, an evaluator is also employed to judge whether the translation in the current round is better than the previous one or not. In this manner, we collect tens of thousands of long-thought MT data, which is used to train our DRT-o1. The experimental results on literature translation demonstrate the effectiveness of the DRT-o1. Using Qwen2.5-7B and Qwen2.5-14B as the backbones, the improvement brought by DRT-o1 achieves 7.33~8.26 BLEU and 1.66~3.36 CometScore. Besides, DRT-o1-7B can outperform QwQ-32B-Preview by 7.82 BLEU and 1.46 CometScore, showing its effectiveness. The project is available at https://github.com/krystalan/DRT-o1
Multilingual Knowledge Editing with Language-Agnostic Factual Neurons
Jun 24, 2024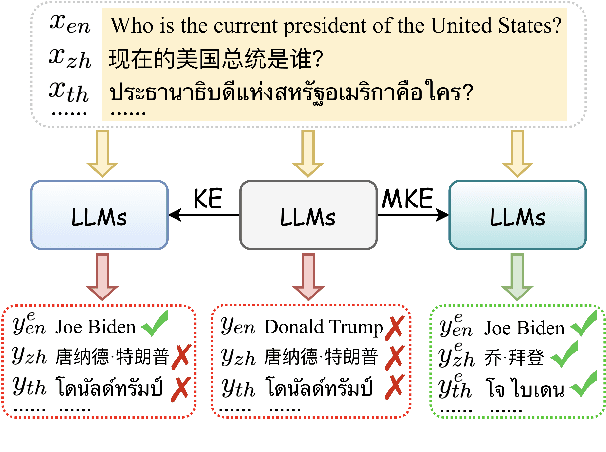
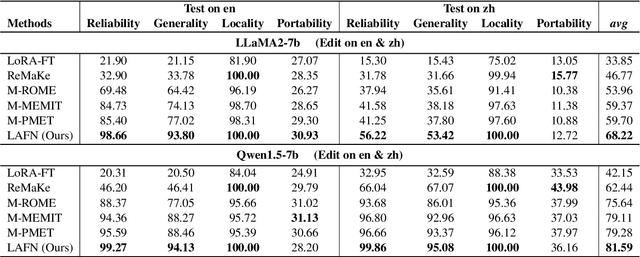
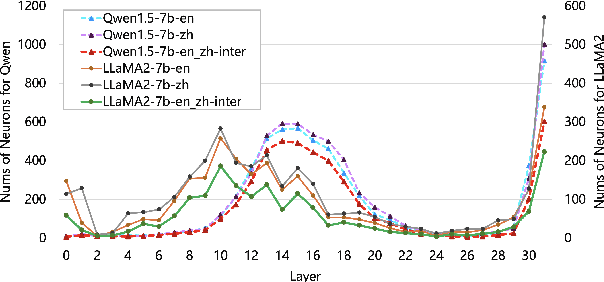
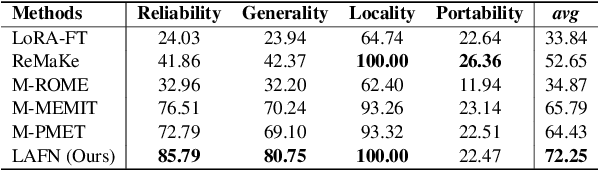
Multilingual knowledge editing (MKE) aims to simultaneously revise factual knowledge across multilingual languages within large language models (LLMs). However, most existing MKE methods just adapt existing monolingual editing methods to multilingual scenarios, overlooking the deep semantic connections of the same factual knowledge between different languages, thereby limiting edit performance. To address this issue, we first investigate how LLMs represent multilingual factual knowledge and discover that the same factual knowledge in different languages generally activates a shared set of neurons, which we call language-agnostic factual neurons. These neurons represent the semantic connections between multilingual knowledge and are mainly located in certain layers. Inspired by this finding, we propose a new MKE method by locating and modifying Language-Agnostic Factual Neurons (LAFN) to simultaneously edit multilingual knowledge. Specifically, we first generate a set of paraphrases for each multilingual knowledge to be edited to precisely locate the corresponding language-agnostic factual neurons. Then we optimize the update values for modifying these located neurons to achieve simultaneous modification of the same factual knowledge in multiple languages. Experimental results on Bi-ZsRE and MzsRE benchmarks demonstrate that our method outperforms existing MKE methods and achieves remarkable edit performance, indicating the importance of considering the semantic connections among multilingual knowledge.
Towards Faster k-Nearest-Neighbor Machine Translation
Dec 12, 2023



Recent works have proven the effectiveness of k-nearest-neighbor machine translation(a.k.a kNN-MT) approaches to produce remarkable improvement in cross-domain translations. However, these models suffer from heavy retrieve overhead on the entire datastore when decoding each token. We observe that during the decoding phase, about 67% to 84% of tokens are unvaried after searching over the corpus datastore, which means most of the tokens cause futile retrievals and introduce unnecessary computational costs by initiating k-nearest-neighbor searches. We consider this phenomenon is explainable in linguistics and propose a simple yet effective multi-layer perceptron (MLP) network to predict whether a token should be translated jointly by the neural machine translation model and probabilities produced by the kNN or just by the neural model. The results show that our method succeeds in reducing redundant retrieval operations and significantly reduces the overhead of kNN retrievals by up to 53% at the expense of a slight decline in translation quality. Moreover, our method could work together with all existing kNN-MT systems.