 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicySim: An LLM-Based Agent Social Simulation Sandbox for Proactive Policy Optimization
Mar 20, 2026Social platforms serve as central hubs for information exchange, where user behaviors and platform interventions jointly shape opinions. However, intervention policies like recommendation and content filtering, can unintentionally amplify echo chambers and polarization, posing significant societal risks. Proactively evaluating the impact of such policies is therefore crucial. Existing approaches primarily rely on reactive online A/B testing, where risks are identified only after deployment, making risk identification delayed and costly. LLM-based social simulations offer a promising pre-deployment alternative, but current methods fall short in realistically modeling platform interventions and incorporating feedback from the platform. Bridging these gaps is essential for building actionable frameworks to assess and optimize platform policies. To this end, we propose PolicySim, an LLM-based social simulation sandbox for the proactive assessment and optimization of intervention policies. PolicySim models the bidirectional dynamics between user behavior and platform interventions through two key components: (1) a user agent module refined via supervised fine-tuning (SFT) and direct preference optimization (DPO) to achieve platform-specific behavioral realism; and (2) an adaptive intervention module that employs a contextual bandit with message passing to capture dynamic network structures. Experiments show that PolicySim can accurately simulate platform ecosystems at both micro and macro levels and support effective intervention policy.
Comparative Study of Large Language Models on Chinese Film Script Continuation: An Empirical Analysis Based on GPT-5.2 and Qwen-Max
Jan 21, 2026As large language models (LLMs) are increasingly applied to creative writing, their performance on culturally specific narrative tasks warrants systematic investigation. This study constructs the first Chinese film script continuation benchmark comprising 53 classic films, and designs a multi-dimensional evaluation framework comparing GPT-5.2 and Qwen-Max-Latest. Using a "first half to second half" continuation paradigm with 3 samples per film, we obtained 303 valid samples (GPT-5.2: 157, 98.7% validity; Qwen-Max: 146, 91.8% validity). Evaluation integrates ROUGE-L, Structural Similarity, and LLM-as-Judge scoring (DeepSeek-Reasoner). Statistical analysis of 144 paired samples reveals: Qwen-Max achieves marginally higher ROUGE-L (0.2230 vs 0.2114, d=-0.43); however, GPT-5.2 significantly outperforms in structural preservation (0.93 vs 0.75, d=0.46), overall quality (44.79 vs 25.72, d=1.04), and composite scores (0.50 vs 0.39, d=0.84). The overall quality effect size reaches large effect level (d>0.8). GPT-5.2 excels in character consistency, tone-style matching, and format preservation, while Qwen-Max shows deficiencies in generation stability. This study provides a reproducible framework for LLM evaluation in Chinese creative writing.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.
How to Use Graph Data in the Wild to Help Graph Anomaly Detection?
Jun 04, 2025In recent years, graph anomaly detection has found extensive applications in various domains such as social, financial, and communication networks. However, anomalies in graph-structured data present unique challenges, including label scarcity, ill-defined anomalies, and varying anomaly types, making supervised or semi-supervised methods unreliable. Researchers often adopt unsupervised approaches to address these challenges, assuming that anomalies deviate significantly from the normal data distribution. Yet, when the available data is insufficient, capturing the normal distribution accurately and comprehensively becomes difficult. To overcome this limitation, we propose to utilize external graph data (i.e., graph data in the wild) to help anomaly detection tasks. This naturally raises the question: How can we use external data to help graph anomaly detection tasks? To answer this question, we propose a framework called Wild-GAD. It is built upon a unified database, UniWildGraph, which comprises a large and diverse collection of graph data with broad domain coverage, ample data volume, and a unified feature space. Further, we develop selection criteria based on representativity and diversity to identify the most suitable external data for anomaly detection task. Extensive experiments on six real-world datasets demonstrate the effectiveness of Wild-GAD. Compared to the baseline methods, our framework has an average 18% AUCROC and 32% AUCPR improvement over the best-competing methods.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025
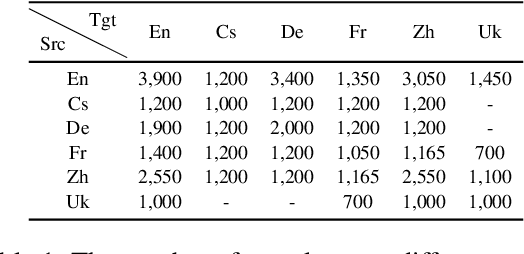
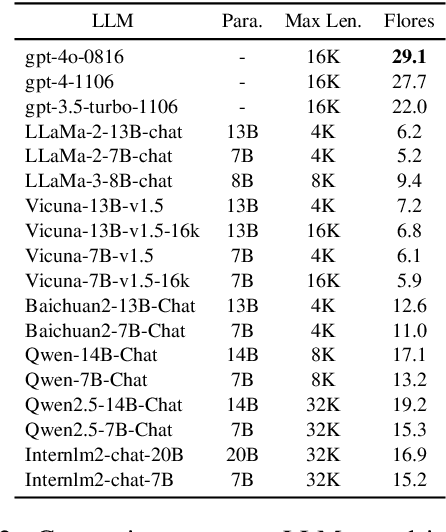
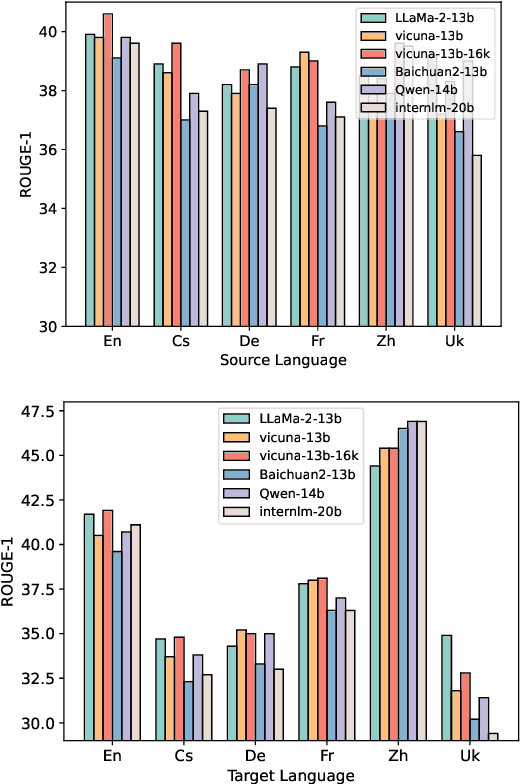
Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
Better with Less: A Data-Active Perspective on Pre-Training Graph Neural Networks
Nov 21, 2023Pre-training on graph neural networks (GNNs) aims to learn transferable knowledge for downstream tasks with unlabeled data, and it has recently become an active research area. The success of graph pre-training models is often attributed to the massive amount of input data. In this paper, however, we identify the curse of big data phenomenon in graph pre-training: more training data do not necessarily lead to better downstream performance. Motivated by this observation, we propose a better-with-less framework for graph pre-training: fewer, but carefully chosen data are fed into a GNN model to enhance pre-training. The proposed pre-training pipeline is called the data-active graph pre-training (APT) framework, and is composed of a graph selector and a pre-training model. The graph selector chooses the most representative and instructive data points based on the inherent properties of graphs as well as predictive uncertainty. The proposed predictive uncertainty, as feedback from the pre-training model, measures the confidence level of the model in the data. When fed with the chosen data, on the other hand, the pre-training model grasps an initial understanding of the new, unseen data, and at the same time attempts to remember the knowledge learned from previous data. Therefore, the integration and interaction between these two components form a unified framework (APT), in which graph pre-training is performed in a progressive and iterative way. Experiment results show that the proposed APT is able to obtain an efficient pre-training model with fewer training data and better downstream performance.
Cross-Lingual Knowledge Editing in Large Language Models
Sep 16, 2023Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges.
When to Pre-Train Graph Neural Networks? An Answer from Data Generation Perspective!
Apr 03, 2023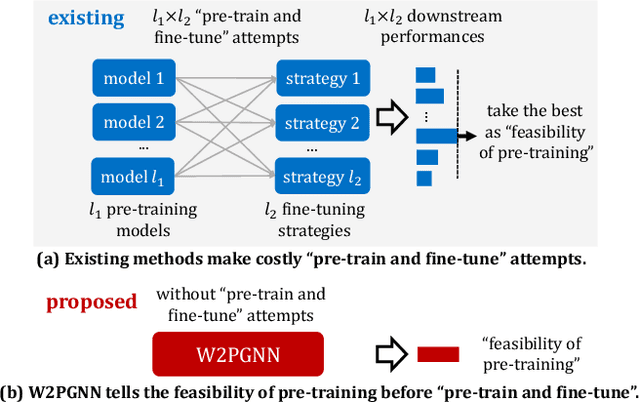
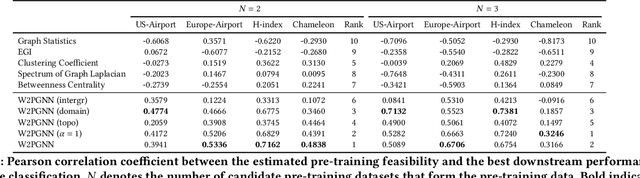
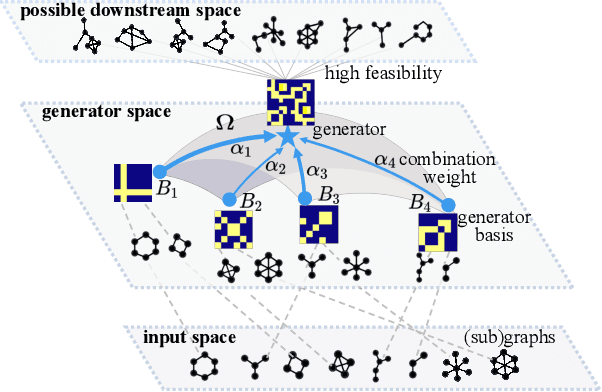
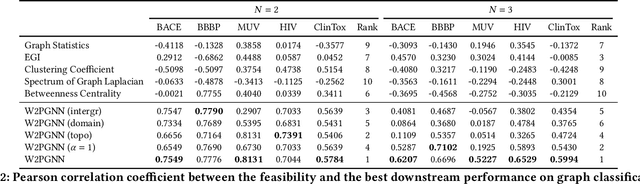
Recently, graph pre-training has attracted wide research attention, which aims to learn transferable knowledge from unlabeled graph data so as to improve downstream performance. Despite these recent attempts, the negative transfer is a major issue when applying graph pre-trained models to downstream tasks. Existing works made great efforts on the issue of what to pre-train and how to pre-train by designing a number of graph pre-training and fine-tuning strategies. However, there are indeed cases where no matter how advanced the strategy is, the "pre-train and fine-tune" paradigm still cannot achieve clear benefits. This paper introduces a generic framework W2PGNN to answer the crucial question of when to pre-train (i.e., in what situations could we take advantage of graph pre-training) before performing effortful pre-training or fine-tuning. We start from a new perspective to explore the complex generative mechanisms from the pre-training data to downstream data. In particular, W2PGNN first fits the pre-training data into graphon bases, each element of graphon basis (i.e., a graphon) identifies a fundamental transferable pattern shared by a collection of pre-training graphs. All convex combinations of graphon bases give rise to a generator space, from which graphs generated form the solution space for those downstream data that can benefit from pre-training. In this manner, the feasibility of pre-training can be quantified as the generation probability of the downstream data from any generator in the generator space. W2PGNN provides three broad applications, including providing the application scope of graph pre-trained models, quantifying the feasibility of performing pre-training, and helping select pre-training data to enhance downstream performance. We give a theoretically sound solution for the first application and extensive empirical justifications for the latter two applications.