 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Achieve Higher Accuracy with Less Training Points?
Apr 18, 2025In the era of large-scale model training, the extensive use of available datasets has resulted in significant computational inefficiencies. To tackle this issue, we explore methods for identifying informative subsets of training data that can achieve comparable or even superior model performance. We propose a technique based on influence functions to determine which training samples should be included in the training set. We conducted empirical evaluations of our method on binary classification tasks utilizing logistic regression models. Our approach demonstrates performance comparable to that of training on the entire dataset while using only 10% of the data. Furthermore, we found that our method achieved even higher accuracy when trained with just 60% of the data.
InfoGaussian: Structure-Aware Dynamic Gaussians through Lightweight Information Shaping
Jun 09, 20243D Gaussians, as a low-level scene representation, typically involve thousands to millions of Gaussians. This makes it difficult to control the scene in ways that reflect the underlying dynamic structure, where the number of independent entities is typically much smaller. In particular, it can be challenging to animate and move objects in the scene, which requires coordination among many Gaussians. To address this issue, we develop a mutual information shaping technique that enforces movement resonance between correlated Gaussians in a motion network. Such correlations can be learned from putative 2D object masks in different views. By approximating the mutual information with the Jacobians of the motions, our method ensures consistent movements of the Gaussians composing different objects under various perturbations. In particular, we develop an efficient contrastive training pipeline with lightweight optimization to shape the motion network, avoiding the need for re-shaping throughout the motion sequence. Notably, our training only touches a small fraction of all Gaussians in the scene yet attains the desired compositional behavior according to the underlying dynamic structure. The proposed technique is evaluated on challenging scenes and demonstrates significant performance improvement in promoting consistent movements and 3D object segmentation while inducing low computation and memory requirements.
When to Pre-Train Graph Neural Networks? An Answer from Data Generation Perspective!
Apr 03, 2023Recently, graph pre-training has attracted wide research attention, which aims to learn transferable knowledge from unlabeled graph data so as to improve downstream performance. Despite these recent attempts, the negative transfer is a major issue when applying graph pre-trained models to downstream tasks. Existing works made great efforts on the issue of what to pre-train and how to pre-train by designing a number of graph pre-training and fine-tuning strategies. However, there are indeed cases where no matter how advanced the strategy is, the "pre-train and fine-tune" paradigm still cannot achieve clear benefits. This paper introduces a generic framework W2PGNN to answer the crucial question of when to pre-train (i.e., in what situations could we take advantage of graph pre-training) before performing effortful pre-training or fine-tuning. We start from a new perspective to explore the complex generative mechanisms from the pre-training data to downstream data. In particular, W2PGNN first fits the pre-training data into graphon bases, each element of graphon basis (i.e., a graphon) identifies a fundamental transferable pattern shared by a collection of pre-training graphs. All convex combinations of graphon bases give rise to a generator space, from which graphs generated form the solution space for those downstream data that can benefit from pre-training. In this manner, the feasibility of pre-training can be quantified as the generation probability of the downstream data from any generator in the generator space. W2PGNN provides three broad applications, including providing the application scope of graph pre-trained models, quantifying the feasibility of performing pre-training, and helping select pre-training data to enhance downstream performance. We give a theoretically sound solution for the first application and extensive empirical justifications for the latter two applications.
Navigation as the Attacker Wishes? Towards Building Byzantine-Robust Embodied Agents under Federated Learning
Dec 02, 2022Federated embodied agent learning protects the data privacy of individual visual environments by keeping data locally at each client (the individual environment) during training. However, since the local data is inaccessible to the server under federated learning, attackers may easily poison the training data of the local client to build a backdoor in the agent without notice. Deploying such an agent raises the risk of potential harm to humans, as the attackers may easily navigate and control the agent as they wish via the backdoor. Towards Byzantine-robust federated embodied agent learning, in this paper, we study the attack and defense for the task of vision-and-language navigation (VLN), where the agent is required to follow natural language instructions to navigate indoor environments. First, we introduce a simple but effective attack strategy, Navigation as Wish (NAW), in which the malicious client manipulates local trajectory data to implant a backdoor into the global model. Results on two VLN datasets (R2R and RxR) show that NAW can easily navigate the deployed VLN agent regardless of the language instruction, without affecting its performance on normal test sets. Then, we propose a new Prompt-Based Aggregation (PBA) to defend against the NAW attack in federated VLN, which provides the server with a ''prompt'' of the vision-and-language alignment variance between the benign and malicious clients so that they can be distinguished during training. We validate the effectiveness of the PBA method on protecting the global model from the NAW attack, which outperforms other state-of-the-art defense methods by a large margin in the defense metrics on R2R and RxR.
Prompt Tuning for Graph Neural Networks
Sep 30, 2022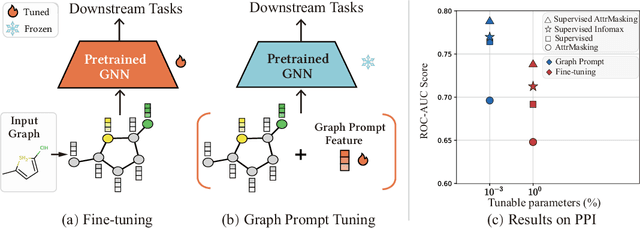

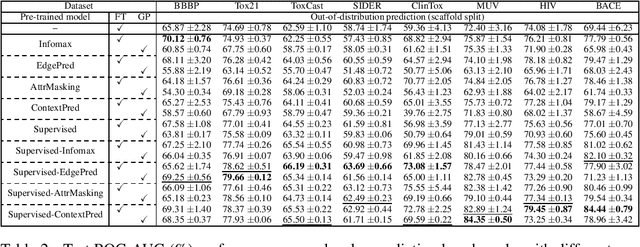
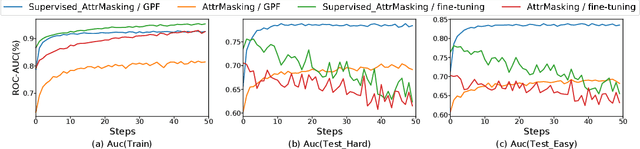
In recent years, prompt tuning has set off a research boom in the adaptation of pre-trained models. In this paper, we propose Graph Prompt as an efficient and effective alternative to full fine-tuning for adapting the pre-trianed GNN models to downstream tasks. To the best of our knowledge, we are the first to explore the effectiveness of prompt tuning on existing pre-trained GNN models. Specifically, without tuning the parameters of the pre-trained GNN model, we train a task-specific graph prompt that provides graph-level transformations on the downstream graphs during the adaptation stage. Then, we introduce a concrete implementation of the graph prompt, called GP-Feature (GPF), which adds learnable perturbations to the feature space of the downstream graph. GPF has a strong expressive ability that it can modify both the node features and the graph structure implicitly. Accordingly, we demonstrate that GPF can achieve the approximately equivalent effect of any graph-level transformations under most existing pre-trained GNN models. We validate the effectiveness of GPF on numerous pre-trained GNN models, and the experimental results show that with a small amount (about 0.1% of that for fine-tuning ) of tunable parameters, GPF can achieve comparable performances as fine-tuning, and even obtain significant performance gains in some cases.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020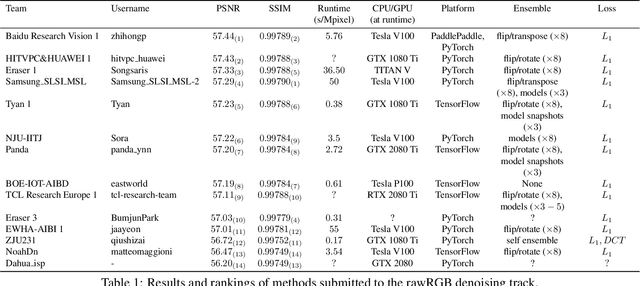
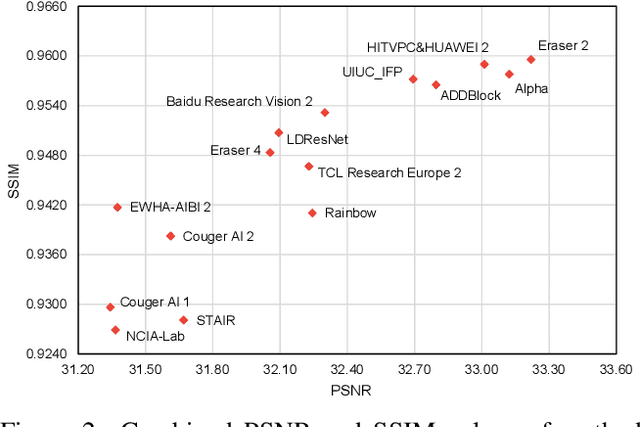
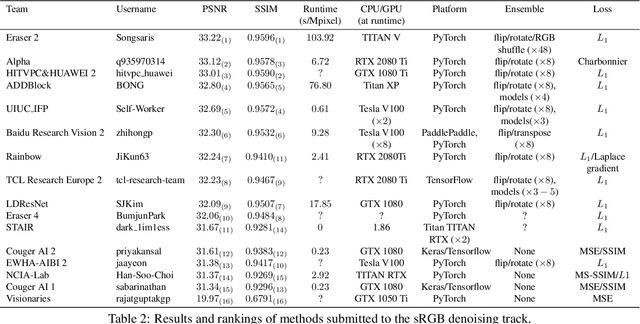
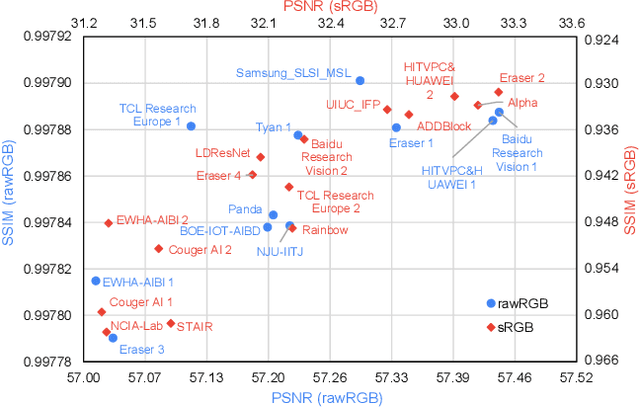
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.