 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowGuard: Towards Lightweight In-Generation Safety Detection for Diffusion Models via Linear Latent Decoding
Apr 09, 2026Diffusion-based image generation models have advanced rapidly but pose a safety risk due to their potential to generate Not-Safe-For-Work (NSFW) content. Existing NSFW detection methods mainly operate either before or after image generation. Pre-generation methods rely on text prompts and struggle with the gap between prompt safety and image safety. Post-generation methods apply classifiers to final outputs, but they are poorly suited to intermediate noisy images. To address this, we introduce FlowGuard, a cross-model in-generation detection framework that inspects intermediate denoising steps. This is particularly challenging in latent diffusion, where early-stage noise obscures visual signals. FlowGuard employs a novel linear approximation for latent decoding and leverages a curriculum learning approach to stabilize training. By detecting unsafe content early, FlowGuard reduces unnecessary diffusion steps to cut computational costs. Our cross-model benchmark spanning nine diffusion-based backbones shows the effectiveness of FlowGuard for in-generation NSFW detection in both in-distribution and out-of-distribution settings, outperforming existing methods by over 30% in F1 score while delivering transformative efficiency gains, including slashing peak GPU memory demand by over 97% and projection time from 8.1 seconds to 0.2 seconds compared to standard VAE decoding.
CAPER: Constrained and Procedural Reasoning for Robotic Scientific Experiments
Feb 10, 2026Robotic assistance in scientific laboratories requires procedurally correct long-horizon manipulation, reliable execution under limited supervision, and robustness in low-demonstration regimes. Such conditions greatly challenge end-to-end vision-language-action (VLA) models, whose assumptions of recoverable errors and data-driven policy learning often break down in protocol-sensitive experiments. We propose CAPER, a framework for Constrained And ProcEdural Reasoning for robotic scientific experiments, which explicitly restricts where learning and reasoning occur in the planning and control pipeline. Rather than strengthening end-to-end policies, CAPER enforces a responsibility-separated structure: task-level reasoning generates procedurally valid action sequences under explicit constraints, mid-level multimodal grounding realizes subtasks without delegating spatial decision-making to large language models, and low-level control adapts to physical uncertainty via reinforcement learning with minimal demonstrations. By encoding procedural commitments through interpretable intermediate representations, CAPER prevents execution-time violations of experimental logic, improving controllability, robustness, and data efficiency. Experiments on a scientific workflow benchmark and a public long-horizon manipulation dataset demonstrate consistent improvements in success rate and procedural correctness, particularly in low-data and long-horizon settings.
Differentiate-and-Inject: Enhancing VLAs via Functional Differentiation Induced by In-Parameter Structural Reasoning
Feb 07, 2026As robots are expected to perform increasingly diverse tasks, they must understand not only low-level actions but also the higher-level structure that determines how a task should unfold. Existing vision-language-action (VLA) models struggle with this form of task-level reasoning. They either depend on prompt-based in-context decomposition, which is unstable and sensitive to linguistic variations, or end-to-end long-horizon training, which requires large-scale demonstrations and entangles task-level reasoning with low-level control. We present in-parameter structured task reasoning (iSTAR), a framework for enhancing VLA models via functional differentiation induced by in-parameter structural reasoning. Instead of treating VLAs as monolithic policies, iSTAR embeds task-level semantic structure directly into model parameters, enabling differentiated task-level inference without external planners or handcrafted prompt inputs. This injected structure takes the form of implicit dynamic scene-graph knowledge that captures object relations, subtask semantics, and task-level dependencies in parameter space. Across diverse manipulation benchmarks, iSTAR achieves more reliable task decompositions and higher success rates than both in-context and end-to-end VLA baselines, demonstrating the effectiveness of parameter-space structural reasoning for functional differentiation and improved generalization across task variations.
Detecting Mislabeled and Corrupted Data via Pointwise Mutual Information
Aug 11, 2025Deep neural networks can memorize corrupted labels, making data quality critical for model performance, yet real-world datasets are frequently compromised by both label noise and input noise. This paper proposes a mutual information-based framework for data selection under hybrid noise scenarios that quantifies statistical dependencies between inputs and labels. We compute each sample's pointwise contribution to the overall mutual information and find that lower contributions indicate noisy or mislabeled instances. Empirical validation on MNIST with different synthetic noise settings demonstrates that the method effectively filters low-quality samples. Under label corruption, training on high-MI samples improves classification accuracy by up to 15\% compared to random sampling. Furthermore, the method exhibits robustness to benign input modifications, preserving semantically valid data while filtering truly corrupted samples.
How to Achieve Higher Accuracy with Less Training Points?
Apr 18, 2025In the era of large-scale model training, the extensive use of available datasets has resulted in significant computational inefficiencies. To tackle this issue, we explore methods for identifying informative subsets of training data that can achieve comparable or even superior model performance. We propose a technique based on influence functions to determine which training samples should be included in the training set. We conducted empirical evaluations of our method on binary classification tasks utilizing logistic regression models. Our approach demonstrates performance comparable to that of training on the entire dataset while using only 10% of the data. Furthermore, we found that our method achieved even higher accuracy when trained with just 60% of the data.
Empowering Global Voices: A Data-Efficient, Phoneme-Tone Adaptive Approach to High-Fidelity Speech Synthesis
Apr 10, 2025Text-to-speech (TTS) technology has achieved impressive results for widely spoken languages, yet many under-resourced languages remain challenged by limited data and linguistic complexities. In this paper, we present a novel methodology that integrates a data-optimized framework with an advanced acoustic model to build high-quality TTS systems for low-resource scenarios. We demonstrate the effectiveness of our approach using Thai as an illustrative case, where intricate phonetic rules and sparse resources are effectively addressed. Our method enables zero-shot voice cloning and improved performance across diverse client applications, ranging from finance to healthcare, education, and law. Extensive evaluations - both subjective and objective - confirm that our model meets state-of-the-art standards, offering a scalable solution for TTS production in data-limited settings, with significant implications for broader industry adoption and multilingual accessibility.
RED: Robust Environmental Design
Nov 26, 2024The classification of road signs by autonomous systems, especially those reliant on visual inputs, is highly susceptible to adversarial attacks. Traditional approaches to mitigating such vulnerabilities have focused on enhancing the robustness of classification models. In contrast, this paper adopts a fundamentally different strategy aimed at increasing robustness through the redesign of road signs themselves. We propose an attacker-agnostic learning scheme to automatically design road signs that are robust to a wide array of patch-based attacks. Empirical tests conducted in both digital and physical environments demonstrate that our approach significantly reduces vulnerability to patch attacks, outperforming existing techniques.
Auto-ICL: In-Context Learning without Human Supervision
Nov 15, 2023
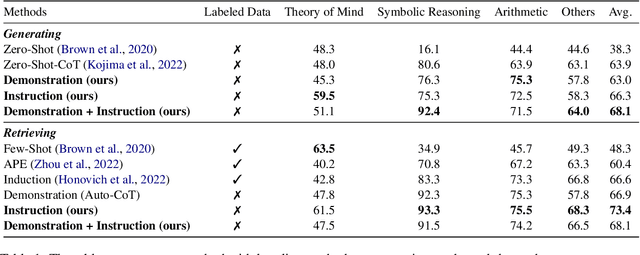


In the era of Large Language Models (LLMs), human-computer interaction has evolved towards natural language, offering unprecedented flexibility. Despite this, LLMs are heavily reliant on well-structured prompts to function efficiently within the realm of In-Context Learning. Vanilla In-Context Learning relies on human-provided contexts, such as labeled examples, explicit instructions, or other guiding mechanisms that shape the model's outputs. To address this challenge, our study presents a universal framework named Automatic In-Context Learning. Upon receiving a user's request, we ask the model to independently generate examples, including labels, instructions, or reasoning pathways. The model then leverages this self-produced context to tackle the given problem. Our approach is universally adaptable and can be implemented in any setting where vanilla In-Context Learning is applicable. We demonstrate that our method yields strong performance across a range of tasks, standing up well when compared to existing methods.
Relabel Minimal Training Subset to Flip a Prediction
May 22, 2023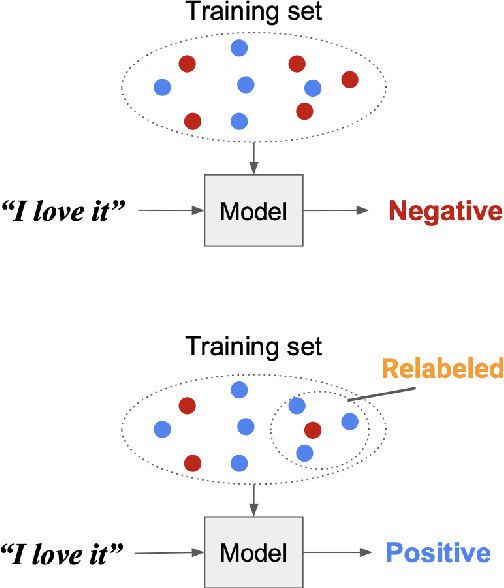

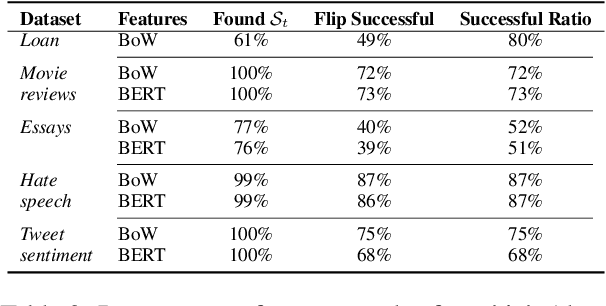
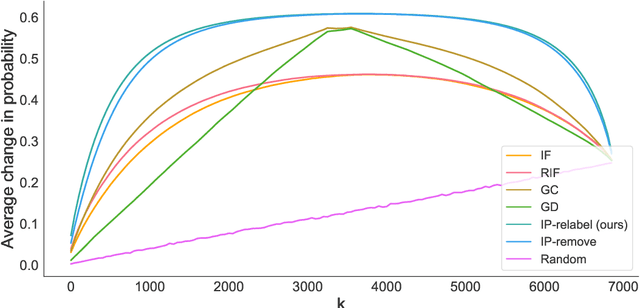
Yang et al. (2023) discovered that removing a mere 1% of training points can often lead to the flipping of a prediction. Given the prevalence of noisy data in machine learning models, we pose the question: can we also result in the flipping of a test prediction by relabeling a small subset of the training data before the model is trained? In this paper, utilizing the extended influence function, we propose an efficient procedure for identifying and relabeling such a subset, demonstrating consistent success. This mechanism serves multiple purposes: (1) providing a complementary approach to challenge model predictions by recovering potentially mislabeled training points; (2) evaluating model resilience, as our research uncovers a significant relationship between the subset's size and the ratio of noisy data in the training set; and (3) offering insights into bias within the training set. To the best of our knowledge, this work represents the first investigation into the problem of identifying and relabeling the minimal training subset required to flip a given prediction.
How Many and Which Training Points Would Need to be Removed to Flip this Prediction?
Feb 09, 2023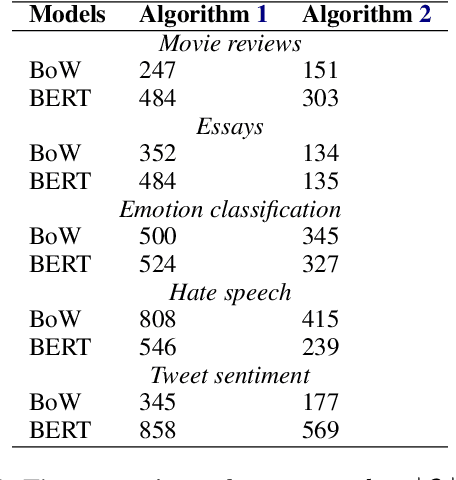
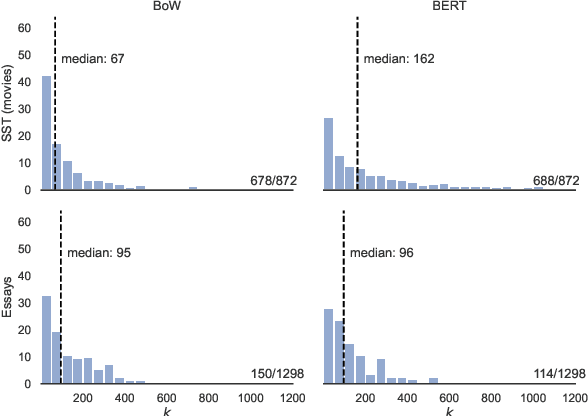

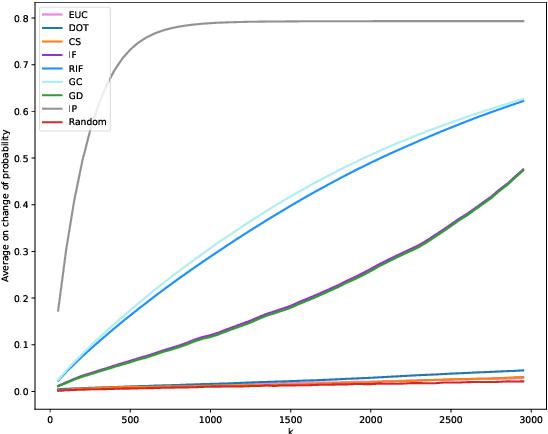
We consider the problem of identifying a minimal subset of training data $\mathcal{S}_t$ such that if the instances comprising $\mathcal{S}_t$ had been removed prior to training, the categorization of a given test point $x_t$ would have been different. Identifying such a set may be of interest for a few reasons. First, the cardinality of $\mathcal{S}_t$ provides a measure of robustness (if $|\mathcal{S}_t|$ is small for $x_t$, we might be less confident in the corresponding prediction), which we show is correlated with but complementary to predicted probabilities. Second, interrogation of $\mathcal{S}_t$ may provide a novel mechanism for contesting a particular model prediction: If one can make the case that the points in $\mathcal{S}_t$ are wrongly labeled or irrelevant, this may argue for overturning the associated prediction. Identifying $\mathcal{S}_t$ via brute-force is intractable. We propose comparatively fast approximation methods to find $\mathcal{S}_t$ based on influence functions, and find that -- for simple convex text classification models -- these approaches can often successfully identify relatively small sets of training examples which, if removed, would flip the prediction.