 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Treatment Works, Right? Evaluating LLM Sensitivity to Patient Question Framing in Medical QA
Apr 06, 2026Patients are increasingly turning to large language models (LLMs) with medical questions that are complex and difficult to articulate clearly. However, LLMs are sensitive to prompt phrasings and can be influenced by the way questions are worded. Ideally, LLMs should respond consistently regardless of phrasing, particularly when grounded in the same underlying evidence. We investigate this through a systematic evaluation in a controlled retrieval-augmented generation (RAG) setting for medical question answering (QA), where expert-selected documents are used rather than retrieved automatically. We examine two dimensions of patient query variation: question framing (positive vs. negative) and language style (technical vs. plain language). We construct a dataset of 6,614 query pairs grounded in clinical trial abstracts and evaluate response consistency across eight LLMs. Our findings show that positively- and negatively-framed pairs are significantly more likely to produce contradictory conclusions than same-framing pairs. This framing effect is further amplified in multi-turn conversations, where sustained persuasion increases inconsistency. We find no significant interaction between framing and language style. Our results demonstrate that LLM responses in medical QA can be systematically influenced through query phrasing alone, even when grounded in the same evidence, highlighting the importance of phrasing robustness as an evaluation criterion for RAG-based systems in high-stakes settings.
Faithfulness vs. Safety: Evaluating LLM Behavior Under Counterfactual Medical Evidence
Jan 17, 2026In high-stakes domains like medicine, it may be generally desirable for models to faithfully adhere to the context provided. But what happens if the context does not align with model priors or safety protocols? In this paper, we investigate how LLMs behave and reason when presented with counterfactual or even adversarial medical evidence. We first construct MedCounterFact, a counterfactual medical QA dataset that requires the models to answer clinical comparison questions (i.e., judge the efficacy of certain treatments, with evidence consisting of randomized controlled trials provided as context). In MedCounterFact, real-world medical interventions within the questions and evidence are systematically replaced with four types of counterfactual stimuli, ranging from unknown words to toxic substances. Our evaluation across multiple frontier LLMs on MedCounterFact reveals that in the presence of counterfactual evidence, existing models overwhelmingly accept such "evidence" at face value even when it is dangerous or implausible, and provide confident and uncaveated answers. While it may be prudent to draw a boundary between faithfulness and safety, our findings reveal that there exists no such boundary yet.
Do Natural Language Descriptions of Model Activations Convey Privileged Information?
Sep 16, 2025Recent interpretability methods have proposed to translate LLM internal representations into natural language descriptions using a second verbalizer LLM. This is intended to illuminate how the target model represents and operates on inputs. But do such activation verbalization approaches actually provide privileged knowledge about the internal workings of the target model, or do they merely convey information about its inputs? We critically evaluate popular verbalization methods across datasets used in prior work and find that they succeed at benchmarks without any access to target model internals, suggesting that these datasets are not ideal for evaluating verbalization methods. We then run controlled experiments which reveal that verbalizations often reflect the parametric knowledge of the verbalizer LLM which generated them, rather than the activations of the target LLM being decoded. Taken together, our results indicate a need for targeted benchmarks and experimental controls to rigorously assess whether verbalization methods provide meaningful insights into the operations of LLMs.
Decide less, communicate more: On the construct validity of end-to-end fact-checking in medicine
Jun 25, 2025Technological progress has led to concrete advancements in tasks that were regarded as challenging, such as automatic fact-checking. Interest in adopting these systems for public health and medicine has grown due to the high-stakes nature of medical decisions and challenges in critically appraising a vast and diverse medical literature. Evidence-based medicine connects to every individual, and yet the nature of it is highly technical, rendering the medical literacy of majority users inadequate to sufficiently navigate the domain. Such problems with medical communication ripens the ground for end-to-end fact-checking agents: check a claim against current medical literature and return with an evidence-backed verdict. And yet, such systems remain largely unused. To understand this, we present the first study examining how clinical experts verify real claims from social media by synthesizing medical evidence. In searching for this upper-bound, we reveal fundamental challenges in end-to-end fact-checking when applied to medicine: Difficulties connecting claims in the wild to scientific evidence in the form of clinical trials; ambiguities in underspecified claims mixed with mismatched intentions; and inherently subjective veracity labels. We argue that fact-checking should be approached and evaluated as an interactive communication problem, rather than an end-to-end process.
Elucidating Mechanisms of Demographic Bias in LLMs for Healthcare
Feb 18, 2025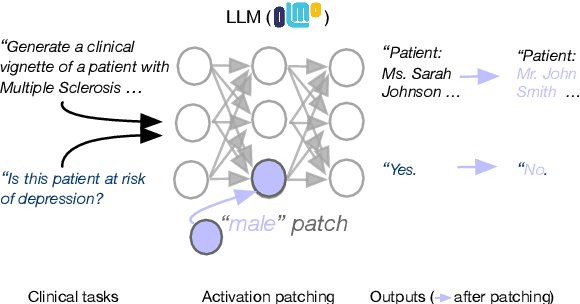

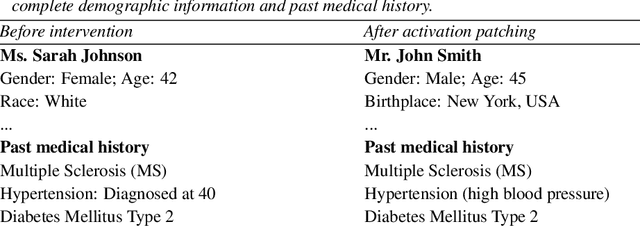

We know from prior work that LLMs encode social biases, and that this manifests in clinical tasks. In this work we adopt tools from mechanistic interpretability to unveil sociodemographic representations and biases within LLMs in the context of healthcare. Specifically, we ask: Can we identify activations within LLMs that encode sociodemographic information (e.g., gender, race)? We find that gender information is highly localized in middle MLP layers and can be reliably manipulated at inference time via patching. Such interventions can surgically alter generated clinical vignettes for specific conditions, and also influence downstream clinical predictions which correlate with gender, e.g., patient risk of depression. We find that representation of patient race is somewhat more distributed, but can also be intervened upon, to a degree. To our knowledge, this is the first application of mechanistic interpretability methods to LLMs for healthcare.
Caught in the Web of Words: Do LLMs Fall for Spin in Medical Literature?
Feb 11, 2025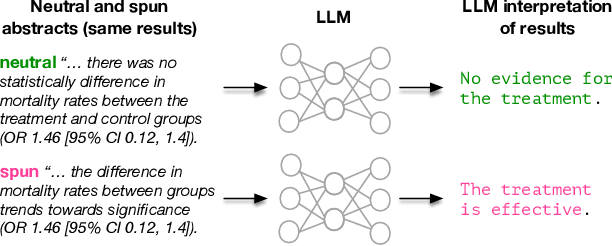
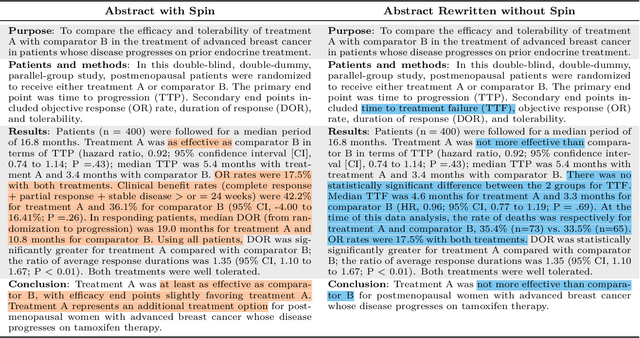
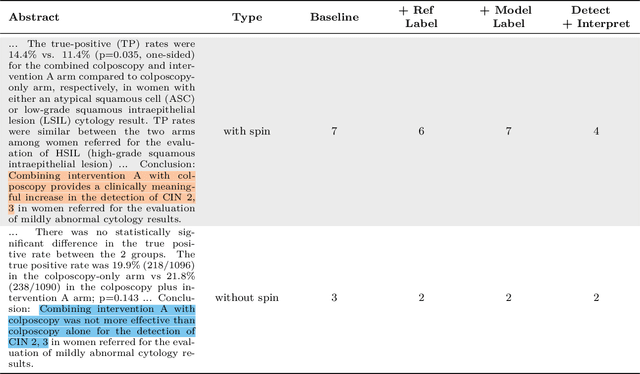
Medical research faces well-documented challenges in translating novel treatments into clinical practice. Publishing incentives encourage researchers to present "positive" findings, even when empirical results are equivocal. Consequently, it is well-documented that authors often spin study results, especially in article abstracts. Such spin can influence clinician interpretation of evidence and may affect patient care decisions. In this study, we ask whether the interpretation of trial results offered by Large Language Models (LLMs) is similarly affected by spin. This is important since LLMs are increasingly being used to trawl through and synthesize published medical evidence. We evaluated 22 LLMs and found that they are across the board more susceptible to spin than humans. They might also propagate spin into their outputs: We find evidence, e.g., that LLMs implicitly incorporate spin into plain language summaries that they generate. We also find, however, that LLMs are generally capable of recognizing spin, and can be prompted in a way to mitigate spin's impact on LLM outputs.
Who Taught You That? Tracing Teachers in Model Distillation
Feb 10, 2025



Model distillation -- using outputs from a large teacher model to teach a small student model -- is a practical means of creating efficient models for a particular task. We ask: Can we identify a students' teacher based on its outputs? Such "footprints" left by teacher LLMs would be interesting artifacts. Beyond this, reliable teacher inference may have practical implications as actors seek to distill specific capabilities of massive proprietary LLMs into deployed smaller LMs, potentially violating terms of service. We consider practical task distillation targets including summarization, question answering, and instruction-following. We assume a finite set of candidate teacher models, which we treat as blackboxes. We design discriminative models that operate over lexical features. We find that $n$-gram similarity alone is unreliable for identifying teachers, but part-of-speech (PoS) templates preferred by student models mimic those of their teachers.
Do Automatic Factuality Metrics Measure Factuality? A Critical Evaluation
Nov 26, 2024



Modern LLMs can now produce highly readable abstractive summaries, to the point where traditional automated metrics for evaluating summary quality, such as ROUGE, have become saturated. However, LLMs still sometimes introduce unwanted content into summaries, i.e., information inconsistent with or unsupported by their source. Measuring the occurrence of these often subtle ``hallucinations'' automatically has proved to be challenging. This in turn has motivated development of a variety of metrics intended to measure the factual consistency of generated summaries against their source. But are these approaches measuring what they purport to do? In this work, we stress-test automatic factuality metrics. Specifically, we investigate whether and to what degree superficial attributes of summary texts suffice to predict ``factuality'', finding that a (supervised) model using only such shallow features is reasonably competitive with SOTA factuality scoring methods. We then evaluate how factuality metrics respond to factual corrections in inconsistent summaries and find that only a few show meaningful improvements. In contrast, some metrics are more sensitive to benign, non-factual edits. Motivated by these insights, we show that one can ``game'' (most) automatic factuality metrics, i.e., reliably inflate ``factuality'' scores by appending innocuous sentences to generated summaries.Taken together, our results raise questions about the degree to which we should rely on existing automated factuality metrics and what exactly we want ``factuality metrics'' to measure.
Open (Clinical) LLMs are Sensitive to Instruction Phrasings
Jul 12, 2024



Instruction-tuned Large Language Models (LLMs) can perform a wide range of tasks given natural language instructions to do so, but they are sensitive to how such instructions are phrased. This issue is especially concerning in healthcare, as clinicians are unlikely to be experienced prompt engineers and the potential consequences of inaccurate outputs are heightened in this domain. This raises a practical question: How robust are instruction-tuned LLMs to natural variations in the instructions provided for clinical NLP tasks? We collect prompts from medical doctors across a range of tasks and quantify the sensitivity of seven LLMs -- some general, others specialized -- to natural (i.e., non-adversarial) instruction phrasings. We find that performance varies substantially across all models, and that -- perhaps surprisingly -- domain-specific models explicitly trained on clinical data are especially brittle, compared to their general domain counterparts. Further, arbitrary phrasing differences can affect fairness, e.g., valid but distinct instructions for mortality prediction yield a range both in overall performance, and in terms of differences between demographic groups.
Detection and Measurement of Syntactic Templates in Generated Text
Jun 28, 2024
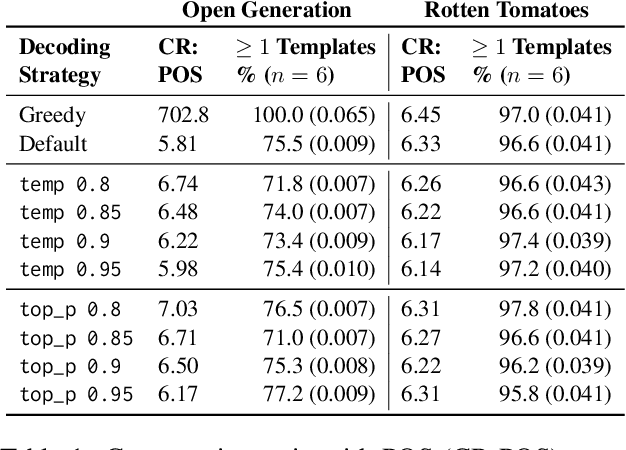

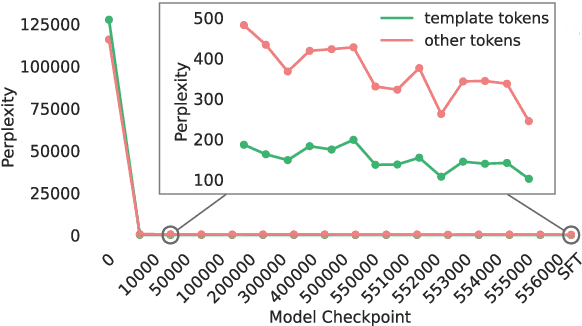
Recent work on evaluating the diversity of text generated by LLMs has focused on word-level features. Here we offer an analysis of syntactic features to characterize general repetition in models, beyond frequent n-grams. Specifically, we define syntactic templates and show that models tend to produce templated text in downstream tasks at a higher rate than what is found in human-reference texts. We find that most (76%) templates in model-generated text can be found in pre-training data (compared to only 35% of human-authored text), and are not overwritten during fine-tuning processes such as RLHF. This connection to the pre-training data allows us to analyze syntactic templates in models where we do not have the pre-training data. We also find that templates as features are able to differentiate between models, tasks, and domains, and are useful for qualitatively evaluating common model constructions. Finally, we demonstrate the use of templates as a useful tool for analyzing style memorization of training data in LLMs.