 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifier Language Models: Unifying Sparse Finetuning and Adaptive Tokenization for Specialized Classification Tasks
Aug 12, 2025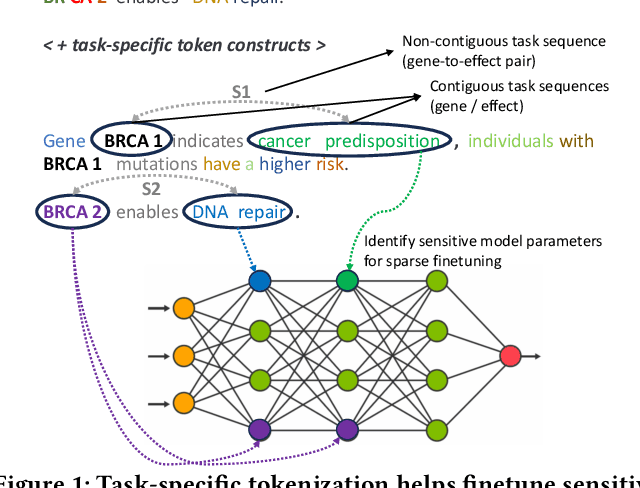



Semantic text classification requires the understanding of the contextual significance of specific tokens rather than surface-level patterns or keywords (as in rule-based or statistical text classification), making large language models (LLMs) well-suited for this task. However, semantic classification applications in industry, like customer intent detection or semantic role labeling, tend to be highly specialized. They require annotation by domain experts in contrast to general-purpose corpora for pretraining. Further, they typically require high inference throughputs which limits the model size from latency and cost perspectives. Thus, for a range of specialized classification tasks, the preferred solution is to develop customized classifiers by finetuning smaller language models (e.g., mini-encoders, small language models). In this work, we develop a token-driven sparse finetuning strategy to adapt small language models to specialized classification tasks. We identify and finetune a small sensitive subset of model parameters by leveraging task-specific token constructs in the finetuning dataset, while leaving most of the pretrained weights unchanged. Unlike adapter approaches such as low rank adaptation (LoRA), we do not introduce additional parameters to the model. Our approach identifies highly relevant semantic tokens (case study in the Appendix) and outperforms end-to-end finetuning, LoRA, layer selection, and prefix tuning on five diverse semantic classification tasks. We achieve greater stability and half the training costs vs. end-to-end finetuning.
Learning from Natural Language Explanations for Generalizable Entity Matching
Jun 13, 2024Entity matching is the task of linking records from different sources that refer to the same real-world entity. Past work has primarily treated entity linking as a standard supervised learning problem. However, supervised entity matching models often do not generalize well to new data, and collecting exhaustive labeled training data is often cost prohibitive. Further, recent efforts have adopted LLMs for this task in few/zero-shot settings, exploiting their general knowledge. But LLMs are prohibitively expensive for performing inference at scale for real-world entity matching tasks. As an efficient alternative, we re-cast entity matching as a conditional generation task as opposed to binary classification. This enables us to "distill" LLM reasoning into smaller entity matching models via natural language explanations. This approach achieves strong performance, especially on out-of-domain generalization tests (10.85% F-1) where standalone generative methods struggle. We perform ablations that highlight the importance of explanations, both for performance and model robustness.
CEV-LM: Controlled Edit Vector Language Model for Shaping Natural Language Generations
Feb 22, 2024



As large-scale language models become the standard for text generation, there is a greater need to tailor the generations to be more or less concise, targeted, and informative, depending on the audience/application. Existing control approaches primarily adjust the semantic (e.g., emotion, topics), structural (e.g., syntax tree, parts-of-speech), and lexical (e.g., keyword/phrase inclusion) properties of text, but are insufficient to accomplish complex objectives such as pacing which control the complexity and readability of the text. In this paper, we introduce CEV-LM - a lightweight, semi-autoregressive language model that utilizes constrained edit vectors to control three complementary metrics (speed, volume, and circuitousness) that quantify the shape of text (e.g., pacing of content). We study an extensive set of state-of-the-art CTG models and find that CEV-LM provides significantly more targeted and precise control of these three metrics while preserving semantic content, using less training data, and containing fewer parameters.
Pre-trained Neural Recommenders: A Transferable Zero-Shot Framework for Recommendation Systems
Sep 03, 2023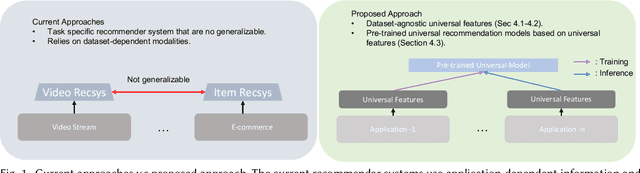
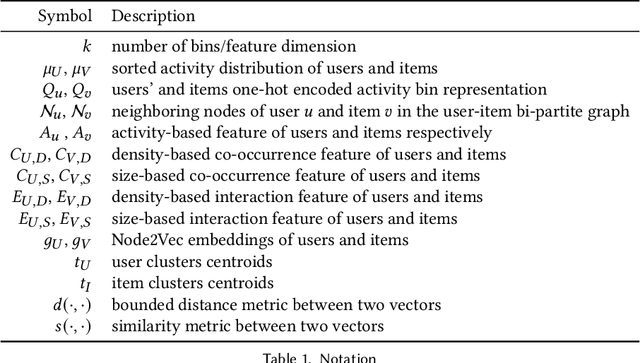
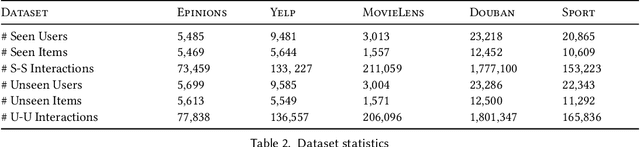
Modern neural collaborative filtering techniques are critical to the success of e-commerce, social media, and content-sharing platforms. However, despite technical advances -- for every new application domain, we need to train an NCF model from scratch. In contrast, pre-trained vision and language models are routinely applied to diverse applications directly (zero-shot) or with limited fine-tuning. Inspired by the impact of pre-trained models, we explore the possibility of pre-trained recommender models that support building recommender systems in new domains, with minimal or no retraining, without the use of any auxiliary user or item information. Zero-shot recommendation without auxiliary information is challenging because we cannot form associations between users and items across datasets when there are no overlapping users or items. Our fundamental insight is that the statistical characteristics of the user-item interaction matrix are universally available across different domains and datasets. Thus, we use the statistical characteristics of the user-item interaction matrix to identify dataset-independent representations for users and items. We show how to learn universal (i.e., supporting zero-shot adaptation without user or item auxiliary information) representations for nodes and edges from the bipartite user-item interaction graph. We learn representations by exploiting the statistical properties of the interaction data, including user and item marginals, and the size and density distributions of their clusters.
Audience-Centric Natural Language Generation via Style Infusion
Jan 24, 2023Adopting contextually appropriate, audience-tailored linguistic styles is critical to the success of user-centric language generation systems (e.g., chatbots, computer-aided writing, dialog systems). While existing approaches demonstrate textual style transfer with large volumes of parallel or non-parallel data, we argue that grounding style on audience-independent external factors is innately limiting for two reasons. First, it is difficult to collect large volumes of audience-specific stylistic data. Second, some stylistic objectives (e.g., persuasiveness, memorability, empathy) are hard to define without audience feedback. In this paper, we propose the novel task of style infusion - infusing the stylistic preferences of audiences in pretrained language generation models. Since humans are better at pairwise comparisons than direct scoring - i.e., is Sample-A more persuasive/polite/empathic than Sample-B - we leverage limited pairwise human judgments to bootstrap a style analysis model and augment our seed set of judgments. We then infuse the learned textual style in a GPT-2 based text generator while balancing fluency and style adoption. With quantitative and qualitative assessments, we show that our infusion approach can generate compelling stylized examples with generic text prompts. The code and data are accessible at https://github.com/CrowdDynamicsLab/StyleInfusion.
Beyond Localized Graph Neural Networks: An Attributed Motif Regularization Framework
Sep 11, 2020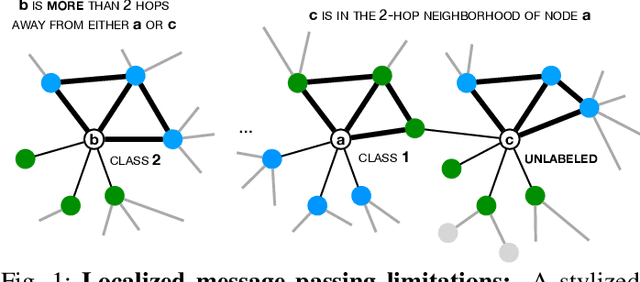
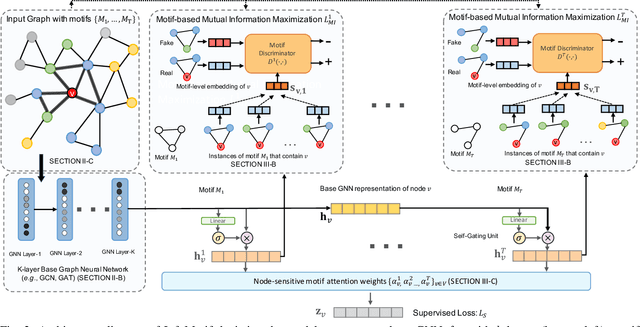
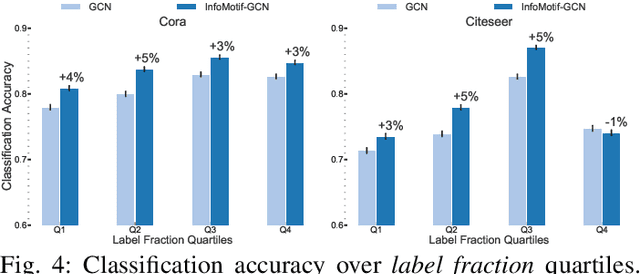
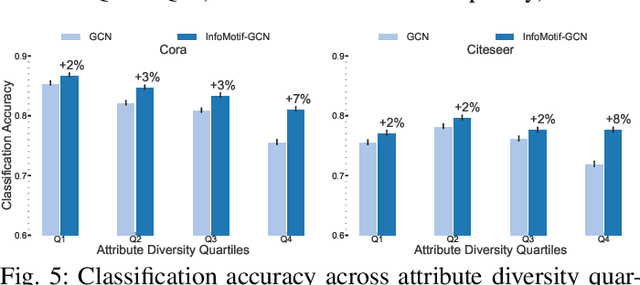
We present InfoMotif, a new semi-supervised, motif-regularized, learning framework over graphs. We overcome two key limitations of message passing in popular graph neural networks (GNNs): localization (a k-layer GNN cannot utilize features outside the k-hop neighborhood of the labeled training nodes) and over-smoothed (structurally indistinguishable) representations. We propose the concept of attributed structural roles of nodes based on their occurrence in different network motifs, independent of network proximity. Two nodes share attributed structural roles if they participate in topologically similar motif instances over co-varying sets of attributes. Further, InfoMotif achieves architecture independence by regularizing the node representations of arbitrary GNNs via mutual information maximization. Our training curriculum dynamically prioritizes multiple motifs in the learning process without relying on distributional assumptions in the underlying graph or the learning task. We integrate three state-of-the-art GNNs in our framework, to show significant gains (3-10% accuracy) across six diverse, real-world datasets. We see stronger gains for nodes with sparse training labels and diverse attributes in local neighborhood structures.
Transfer Learning via Contextual Invariants for One-to-Many Cross-Domain Recommendation
May 21, 2020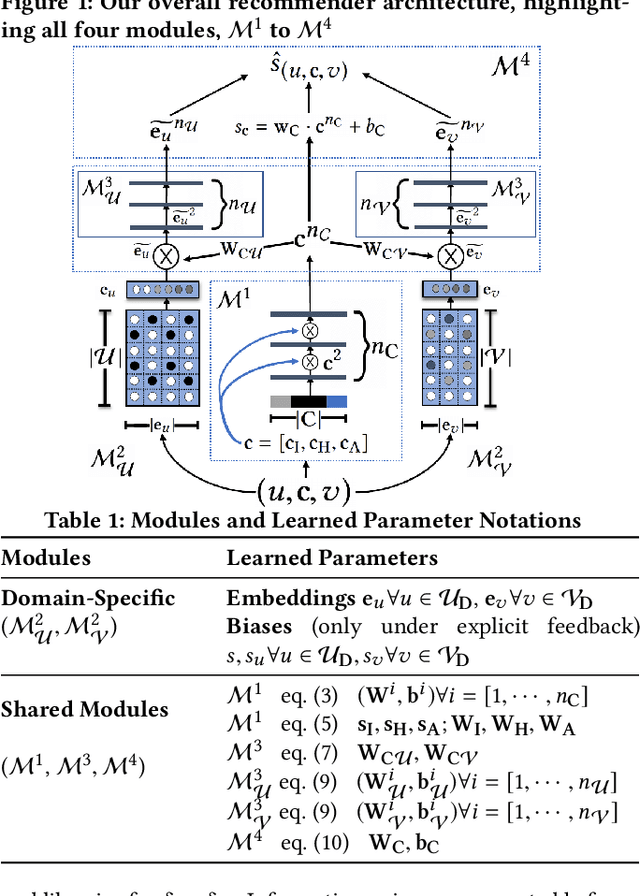

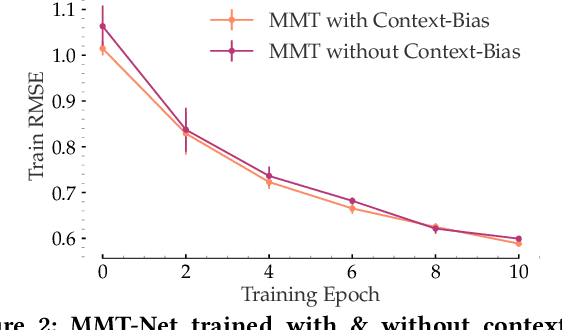
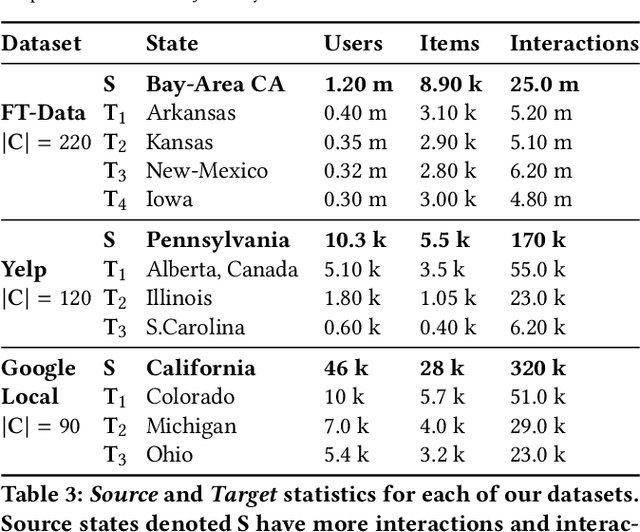
The rapid proliferation of new users and items on the social web has aggravated the gray-sheep user/long-tail item challenge in recommender systems. Historically, cross-domain co-clustering methods have successfully leveraged shared users and items across dense and sparse domains to improve inference quality. However, they rely on shared rating data and cannot scale to multiple sparse target domains (i.e., the one-to-many transfer setting). This, combined with the increasing adoption of neural recommender architectures, motivates us to develop scalable neural layer-transfer approaches for cross-domain learning. Our key intuition is to guide neural collaborative filtering with domain-invariant components shared across the dense and sparse domains, improving the user and item representations learned in the sparse domains. We leverage contextual invariances across domains to develop these shared modules, and demonstrate that with user-item interaction context, we can learn-to-learn informative representation spaces even with sparse interaction data. We show the effectiveness and scalability of our approach on two public datasets and a massive transaction dataset from Visa, a global payments technology company (19% Item Recall, 3x faster vs. training separate models for each domain). Our approach is applicable to both implicit and explicit feedback settings.
Inf-VAE: A Variational Autoencoder Framework to Integrate Homophily and Influence in Diffusion Prediction
Jan 01, 2020
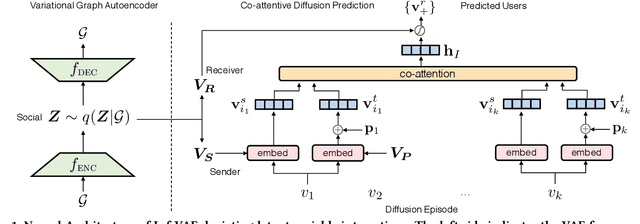
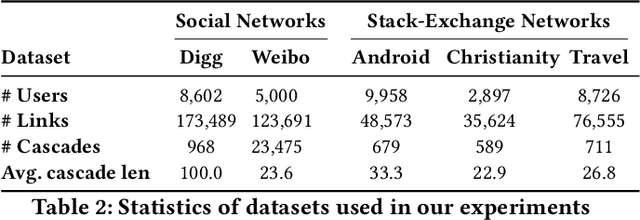
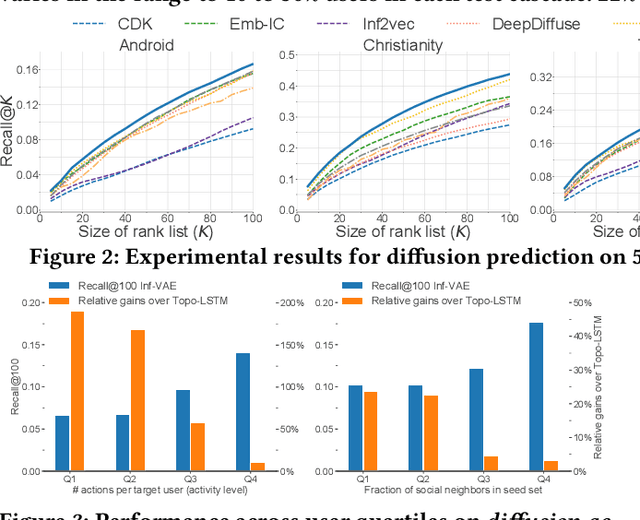
Recent years have witnessed tremendous interest in understanding and predicting information spread on social media platforms such as Twitter, Facebook, etc. Existing diffusion prediction methods primarily exploit the sequential order of influenced users by projecting diffusion cascades onto their local social neighborhoods. However, this fails to capture global social structures that do not explicitly manifest in any of the cascades, resulting in poor performance for inactive users with limited historical activities. In this paper, we present a novel variational autoencoder framework (Inf-VAE) to jointly embed homophily and influence through proximity-preserving social and position-encoded temporal latent variables. To model social homophily, Inf-VAE utilizes powerful graph neural network architectures to learn social variables that selectively exploit the social connections of users. Given a sequence of seed user activations, Inf-VAE uses a novel expressive co-attentive fusion network that jointly attends over their social and temporal variables to predict the set of all influenced users. Our experimental results on multiple real-world social network datasets, including Digg, Weibo, and Stack-Exchanges demonstrate significant gains (22% MAP@10) for Inf-VAE over state-of-the-art diffusion prediction models; we achieve massive gains for users with sparse activities, and users who lack direct social neighbors in seed sets.
An Induced Multi-Relational Framework for Answer Selection in Community Question Answer Platforms
Nov 16, 2019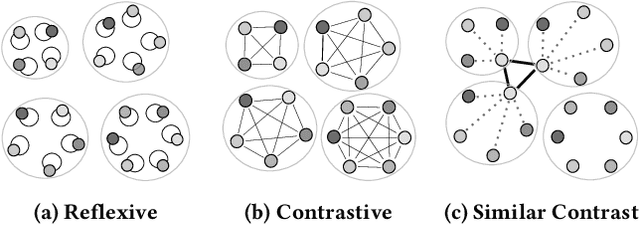

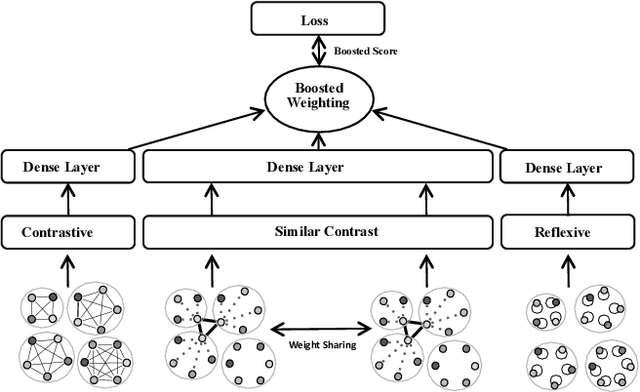
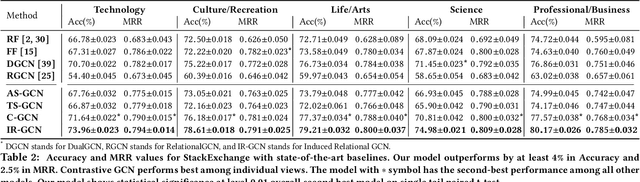
This paper addresses the question of identifying the best candidate answer to a question on Community Question Answer (CQA) forums. The problem is important because Individuals often visit CQA forums to seek answers to nuanced questions. We develop a novel induced relational graph convolutional network (IR-GCN) framework to address the question. We make three contributions. First, we introduce a modular framework that separates the construction of the graph with the label selection mechanism. We use equivalence relations to induce a graph comprising cliques and identify two label assignment mechanisms---label contrast, label sharing. Then, we show how to encode these assignment mechanisms in GCNs. Second, we show that encoding contrast creates discriminative magnification---enhancing the separation between nodes in the embedding space. Third, we show a surprising result---boosting techniques improve learning over familiar stacking, fusion, or aggregation approaches for neural architectures. We show strong results over the state-of-the-art neural baselines in extensive experiments on 50 StackExchange communities.
Improving Latent User Models in Online Social Media
Nov 30, 2017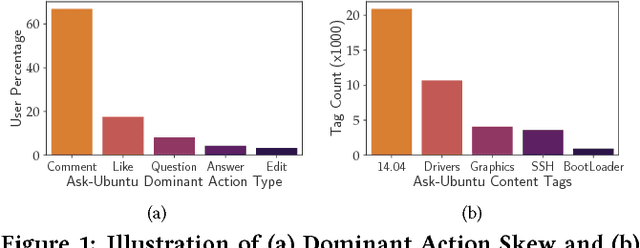
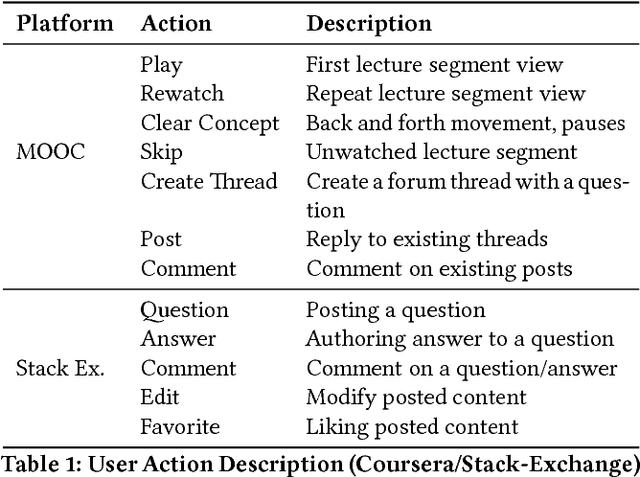
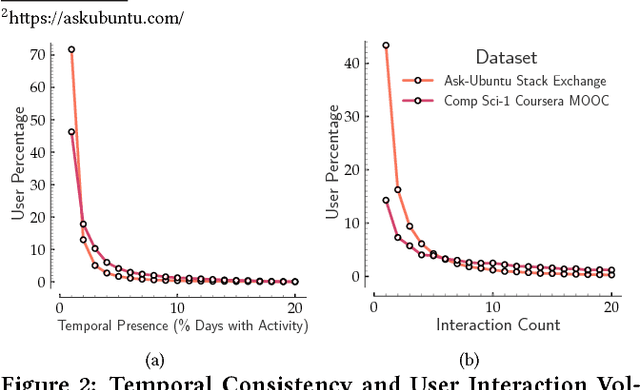
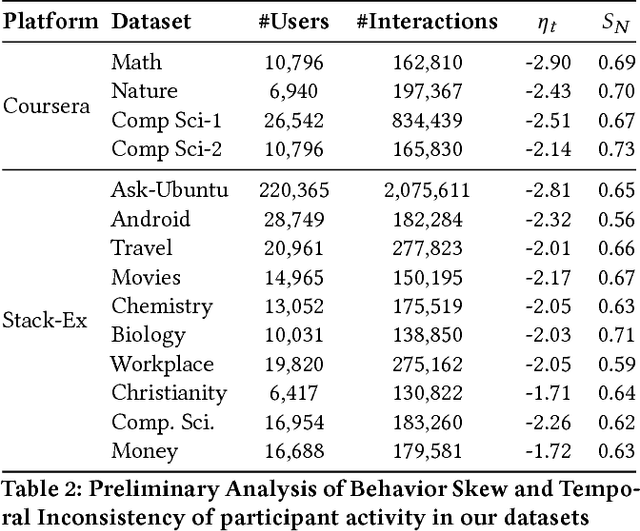
Modern social platforms are characterized by the presence of rich user-behavior data associated with the publication, sharing and consumption of textual content. Users interact with content and with each other in a complex and dynamic social environment while simultaneously evolving over time. In order to effectively characterize users and predict their future behavior in such a setting, it is necessary to overcome several challenges. Content heterogeneity and temporal inconsistency of behavior data result in severe sparsity at the user level. In this paper, we propose a novel mutual-enhancement framework to simultaneously partition and learn latent activity profiles of users. We propose a flexible user partitioning approach to effectively discover rare behaviors and tackle user-level sparsity. We extensively evaluate the proposed framework on massive datasets from real-world platforms including Q&A networks and interactive online courses (MOOCs). Our results indicate significant gains over state-of-the-art behavior models ( 15% avg ) in a varied range of tasks and our gains are further magnified for users with limited interaction data. The proposed algorithms are amenable to parallelization, scale linearly in the size of datasets, and provide flexibility to model diverse facets of user behavior.