 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoReflect: Conversational Evaluation via Co-Evolutionary Simulation and Reflective Rubric Refinement
Jan 18, 2026Evaluating conversational systems in multi-turn settings remains a fundamental challenge. Conventional pipelines typically rely on manually defined rubrics and fixed conversational context$-$a static approach that limits coverage and fails to capture the diverse, emergent behaviors of dialogue models. To address this, we introduce CoReflect (Conversational Evaluation via Co-Evolutionary Simulation and Reflective Rubric Refinement), which unifies dialogue simulation and evaluation into an adaptive, iterative process. CoReflect employs a conversation planner that generates structured templates to guide a user simulator through diverse, goal-directed dialogues. Subsequently, a reflective analyzer processes these dialogues to identify systematic behavioral patterns and automatically refine the evaluation rubrics. Crucially, the insights from the conversation analysis are fed back into the planner to update conversation templates for subsequent iterations. This co-evolution loop ensures that the complexity of test cases and the diagnostic precision of rubrics improve in tandem. By minimizing human intervention, CoReflect provides a scalable and self-refining methodology that allows evaluation protocols to adapt alongside the rapidly advancing capabilities of dialogue models.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
LinkedOut: Linking World Knowledge Representation Out of Video LLM for Next-Generation Video Recommendation
Dec 18, 2025Video Large Language Models (VLLMs) unlock world-knowledge-aware video understanding through pretraining on internet-scale data and have already shown promise on tasks such as movie analysis and video question answering. However, deploying VLLMs for downstream tasks such as video recommendation remains challenging, since real systems require multi-video inputs, lightweight backbones, low-latency sequential inference, and rapid response. In practice, (1) decode-only generation yields high latency for sequential inference, (2) typical interfaces do not support multi-video inputs, and (3) constraining outputs to language discards fine-grained visual details that matter for downstream vision tasks. We argue that these limitations stem from the absence of a representation that preserves pixel-level detail while leveraging world knowledge. We present LinkedOut, a representation that extracts VLLM world knowledge directly from video to enable fast inference, supports multi-video histories, and removes the language bottleneck. LinkedOut extracts semantically grounded, knowledge-aware tokens from raw frames using VLLMs, guided by promptable queries and optional auxiliary modalities. We introduce a cross-layer knowledge fusion MoE that selects the appropriate level of abstraction from the rich VLLM features, enabling personalized, interpretable, and low-latency recommendation. To our knowledge, LinkedOut is the first VLLM-based video recommendation method that operates on raw frames without handcrafted labels, achieving state-of-the-art results on standard benchmarks. Interpretability studies and ablations confirm the benefits of layer diversity and layer-wise fusion, pointing to a practical path that fully leverages VLLM world-knowledge priors and visual reasoning for downstream vision tasks such as recommendation.
Saga: Capturing Multi-granularity Semantics from Massive Unlabelled IMU Data for User Perception
Apr 16, 2025Inertial measurement units (IMUs), have been prevalently used in a wide range of mobile perception applications such as activity recognition and user authentication, where a large amount of labelled data are normally required to train a satisfactory model. However, it is difficult to label micro-activities in massive IMU data due to the hardness of understanding raw IMU data and the lack of ground truth. In this paper, we propose a novel fine-grained user perception approach, called Saga, which only needs a small amount of labelled IMU data to achieve stunning user perception accuracy. The core idea of Saga is to first pre-train a backbone feature extraction model, utilizing the rich semantic information of different levels embedded in the massive unlabelled IMU data. Meanwhile, for a specific downstream user perception application, Bayesian Optimization is employed to determine the optimal weights for pre-training tasks involving different semantic levels. We implement Saga on five typical mobile phones and evaluate Saga on three typical tasks on three IMU datasets. Results show that when only using about 100 training samples per class, Saga can achieve over 90% accuracy of the full-fledged model trained on over ten thousands training samples with no additional system overhead.
A Zero-Shot Generalization Framework for LLM-Driven Cross-Domain Sequential Recommendation
Jan 31, 2025



Zero-shot cross-domain sequential recommendation (ZCDSR) enables predictions in unseen domains without the need for additional training or fine-tuning, making it particularly valuable in data-sparse environments where traditional models struggle. Recent advancements in large language models (LLMs) have greatly improved ZCDSR by leveraging rich pretrained representations to facilitate cross-domain knowledge transfer. However, a key challenge persists: domain semantic bias, which arises from variations in vocabulary and content focus across domains. This misalignment leads to inconsistencies in item embeddings and hinders generalization. To address this issue, we propose a novel framework designed to enhance LLM-based ZCDSR by improving cross-domain alignment at both the item and sequential levels. At the item level, we introduce a generalization loss that promotes inter-domain compactness by aligning embeddings of similar items across domains while maintaining intra-domain diversity to preserve unique item characteristics. This prevents embeddings from becoming overly generic while ensuring effective transferability. At the sequential level, we develop a method for transferring user behavioral patterns by clustering user sequences in the source domain and applying attention-based aggregation for target domain inference. This dynamic adaptation of user embeddings allows effective zero-shot recommendations without requiring target-domain interactions. Comprehensive experiments across multiple datasets and domains demonstrate that our framework significantly improves sequential recommendation performance in the ZCDSR setting. By mitigating domain bias and enhancing the transferability of sequential patterns, our method provides a scalable and robust approach for achieving more effective zero-shot recommendations across domains.
Prism: Mining Task-aware Domains in Non-i.i.d. IMU Data for Flexible User Perception
Jan 03, 2025



A wide range of user perception applications leverage inertial measurement unit (IMU) data for online prediction. However, restricted by the non-i.i.d. nature of IMU data collected from mobile devices, most systems work well only in a controlled setting (e.g., for a specific user in particular postures), limiting application scenarios. To achieve uncontrolled online prediction on mobile devices, referred to as the flexible user perception (FUP) problem, is attractive but hard. In this paper, we propose a novel scheme, called Prism, which can obtain high FUP accuracy on mobile devices. The core of Prism is to discover task-aware domains embedded in IMU dataset, and to train a domain-aware model on each identified domain. To this end, we design an expectation-maximization (EM) algorithm to estimate latent domains with respect to the specific downstream perception task. Finally, the best-fit model can be automatically selected for use by comparing the test sample and all identified domains in the feature space. We implement Prism on various mobile devices and conduct extensive experiments. Results demonstrate that Prism can achieve the best FUP performance with a low latency.
Deep RAW Image Super-Resolution. A NTIRE 2024 Challenge Survey
Apr 24, 2024
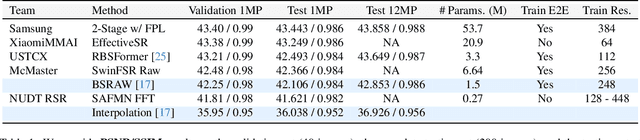
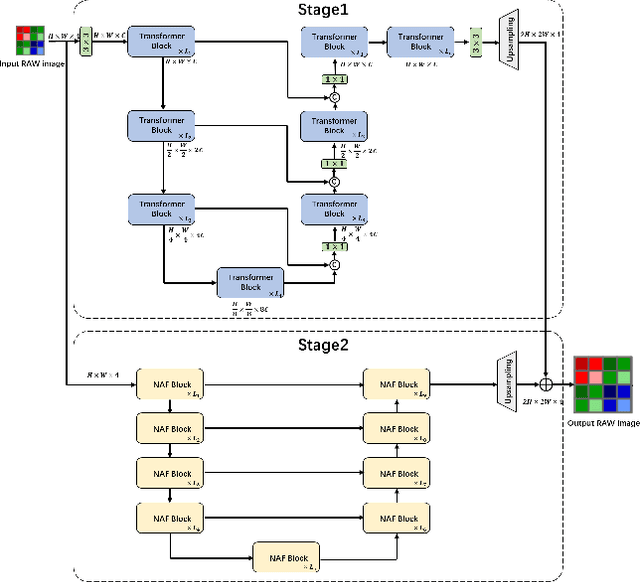
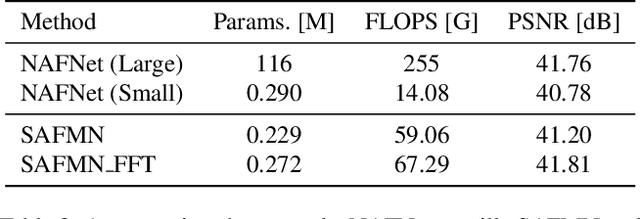
This paper reviews the NTIRE 2024 RAW Image Super-Resolution Challenge, highlighting the proposed solutions and results. New methods for RAW Super-Resolution could be essential in modern Image Signal Processing (ISP) pipelines, however, this problem is not as explored as in the RGB domain. Th goal of this challenge is to upscale RAW Bayer images by 2x, considering unknown degradations such as noise and blur. In the challenge, a total of 230 participants registered, and 45 submitted results during thee challenge period. The performance of the top-5 submissions is reviewed and provided here as a gauge for the current state-of-the-art in RAW Image Super-Resolution.
Wide-Field, High-Resolution Reconstruction in Computational Multi-Aperture Miniscope Using a Fourier Neural Network
Mar 11, 2024Traditional fluorescence microscopy is constrained by inherent trade-offs among resolution, field-of-view, and system complexity. To navigate these challenges, we introduce a simple and low-cost computational multi-aperture miniature microscope, utilizing a microlens array for single-shot wide-field, high-resolution imaging. Addressing the challenges posed by extensive view multiplexing and non-local, shift-variant aberrations in this device, we present SV-FourierNet, a novel multi-channel Fourier neural network. SV-FourierNet facilitates high-resolution image reconstruction across the entire imaging field through its learned global receptive field. We establish a close relationship between the physical spatially-varying point-spread functions and the network's learned effective receptive field. This ensures that SV-FourierNet has effectively encapsulated the spatially-varying aberrations in our system, and learned a physically meaningful function for image reconstruction. Training of SV-FourierNet is conducted entirely on a physics-based simulator. We showcase wide-field, high-resolution video reconstructions on colonies of freely moving C. elegans and imaging of a mouse brain section. Our computational multi-aperture miniature microscope, augmented with SV-FourierNet, represents a major advancement in computational microscopy and may find broad applications in biomedical research and other fields requiring compact microscopy solutions.
CodeScope: An Execution-based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Nov 14, 2023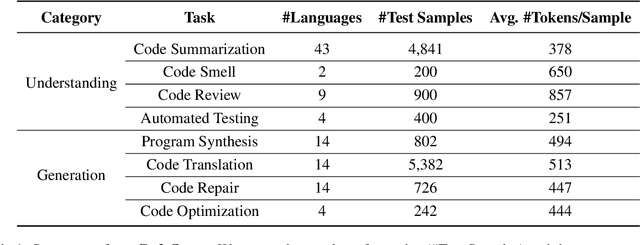
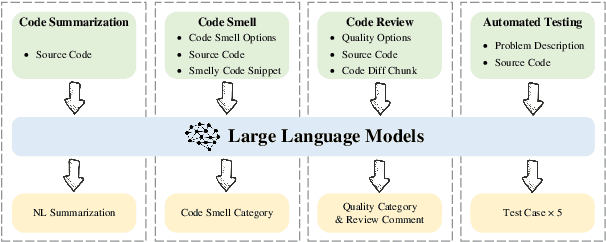

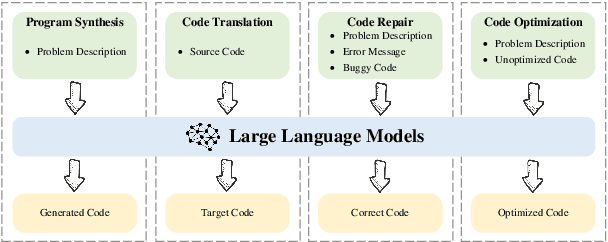
Large Language Models (LLMs) have demonstrated remarkable performance on coding related tasks, particularly on assisting humans in programming and facilitating programming automation. However, existing benchmarks for evaluating the code understanding and generation capacities of LLMs suffer from severe limitations. First, most benchmarks are deficient as they focus on a narrow range of popular programming languages and specific tasks, whereas the real-world software development scenarios show dire need to implement systems with multilingual programming environments to satisfy diverse requirements. Practical programming practices also strongly expect multi-task settings for testing coding capabilities of LLMs comprehensively and robustly. Second, most benchmarks also fail to consider the actual executability and the consistency of execution results of the generated code. To bridge these gaps between existing benchmarks and expectations from practical applications, we introduce CodeScope, an execution-based, multilingual, multi-task, multi-dimensional evaluation benchmark for comprehensively gauging LLM capabilities on coding tasks. CodeScope covers 43 programming languages and 8 coding tasks. It evaluates the coding performance of LLMs from three dimensions (perspectives): difficulty, efficiency, and length. To facilitate execution-based evaluations of code generation, we develop MultiCodeEngine, an automated code execution engine that supports 14 programming languages. Finally, we systematically evaluate and analyze 8 mainstream LLMs on CodeScope tasks and demonstrate the superior breadth and challenges of CodeScope for evaluating LLMs on code understanding and generation tasks compared to other benchmarks. The CodeScope benchmark and datasets are publicly available at https://github.com/WeixiangYAN/CodeScope.
CodeTransOcean: A Comprehensive Multilingual Benchmark for Code Translation
Oct 08, 2023



Recent code translation techniques exploit neural machine translation models to translate source code from one programming language to another to satisfy production compatibility or to improve efficiency of codebase maintenance. Most existing code translation datasets only focus on a single pair of popular programming languages. To advance research on code translation and meet diverse requirements of real-world applications, we construct CodeTransOcean, a large-scale comprehensive benchmark that supports the largest variety of languages for code translation. CodeTransOcean consists of three novel multilingual datasets, namely, MultilingualTrans supporting translations between multiple popular programming languages, NicheTrans for translating between niche programming languages and popular ones, and LLMTrans for evaluating compilability of translated code by large language models (LLMs). CodeTransOcean also includes a novel cross-framework dataset, DLTrans, for translating deep learning code across different frameworks. We develop multilingual modeling approaches for code translation and demonstrate their great potential in improving the translation quality of both low-resource and high-resource language pairs and boosting the training efficiency. We also propose a novel evaluation metric Debugging Success Rate@K for program-level code translation. Last but not least, we evaluate LLM ChatGPT on our datasets and investigate its potential for fuzzy compilation predictions. We build baselines for CodeTransOcean and analyze challenges of code translation for guiding future research.