 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide-Field, High-Resolution Reconstruction in Computational Multi-Aperture Miniscope Using a Fourier Neural Network
Mar 11, 2024Traditional fluorescence microscopy is constrained by inherent trade-offs among resolution, field-of-view, and system complexity. To navigate these challenges, we introduce a simple and low-cost computational multi-aperture miniature microscope, utilizing a microlens array for single-shot wide-field, high-resolution imaging. Addressing the challenges posed by extensive view multiplexing and non-local, shift-variant aberrations in this device, we present SV-FourierNet, a novel multi-channel Fourier neural network. SV-FourierNet facilitates high-resolution image reconstruction across the entire imaging field through its learned global receptive field. We establish a close relationship between the physical spatially-varying point-spread functions and the network's learned effective receptive field. This ensures that SV-FourierNet has effectively encapsulated the spatially-varying aberrations in our system, and learned a physically meaningful function for image reconstruction. Training of SV-FourierNet is conducted entirely on a physics-based simulator. We showcase wide-field, high-resolution video reconstructions on colonies of freely moving C. elegans and imaging of a mouse brain section. Our computational multi-aperture miniature microscope, augmented with SV-FourierNet, represents a major advancement in computational microscopy and may find broad applications in biomedical research and other fields requiring compact microscopy solutions.
Robust single-shot 3D fluorescence imaging in scattering media with a simulator-trained neural network
Mar 22, 2023



Imaging through scattering is a pervasive and difficult problem in many biological applications. The high background and the exponentially attenuated target signals due to scattering fundamentally limits the imaging depth of fluorescence microscopy. Light-field systems are favorable for high-speed volumetric imaging, but the 2D-to-3D reconstruction is fundamentally ill-posed and scattering exacerbates the condition of the inverse problem. Here, we develop a scattering simulator that models low-contrast target signals buried in heterogeneous strong background. We then train a deep neural network solely on synthetic data to descatter and reconstruct a 3D volume from a single-shot light-field measurement with low signal-to-background ratio (SBR). We apply this network to our previously developed Computational Miniature Mesoscope and demonstrate the robustness of our deep learning algorithm on a 75 micron thick fixed mouse brain section and on bulk scattering phantoms with different scattering conditions. The network can robustly reconstruct emitters in 3D with a 2D measurement of SBR as low as 1.05 and as deep as a scattering length. We analyze fundamental tradeoffs based on network design factors and out-of-distribution data that affect the deep learning model's generalizability to real experimental data. Broadly, we believe that our simulator-based deep learning approach can be applied to a wide range of imaging through scattering techniques where experimental paired training data is lacking.
Block Modulating Video Compression: An Ultra Low Complexity Image Compression Encoder for Resource Limited Platforms
May 07, 2022
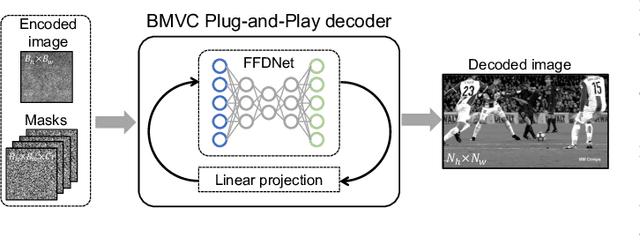
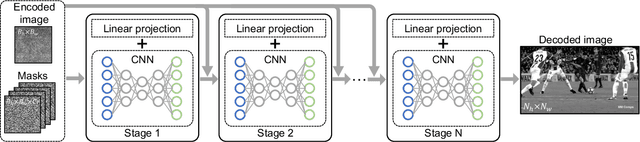

We consider the image and video compression on resource limited platforms. An ultra low-cost image encoder, named Block Modulating Video Compression (BMVC) with an encoding complexity ${\cal O}(1)$ is proposed to be implemented on mobile platforms with low consumption of power and computation resources. We also develop two types of BMVC decoders, implemented by deep neural networks. The first BMVC decoder is based on the Plug-and-Play (PnP) algorithm, which is flexible to different compression ratios. And the second decoder is a memory efficient end-to-end convolutional neural network, which aims for real-time decoding. Extensive results on the high definition images and videos demonstrate the superior performance of the proposed codec and the robustness against bit quantization.
Computational Miniature Mesoscope V2: A deep learning-augmented miniaturized microscope for single-shot 3D high-resolution fluorescence imaging
Apr 30, 2022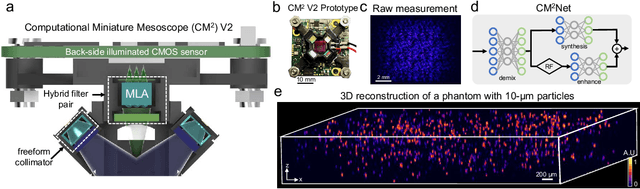
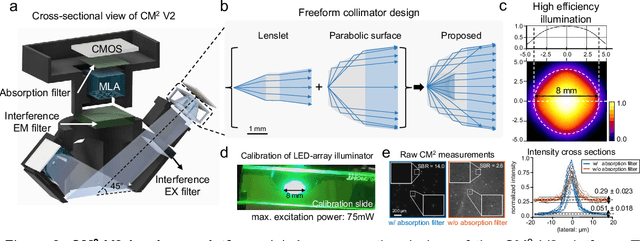
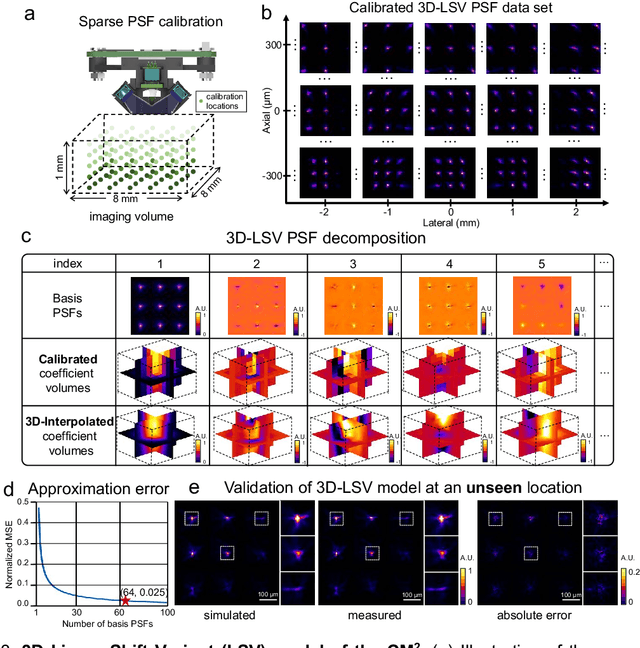
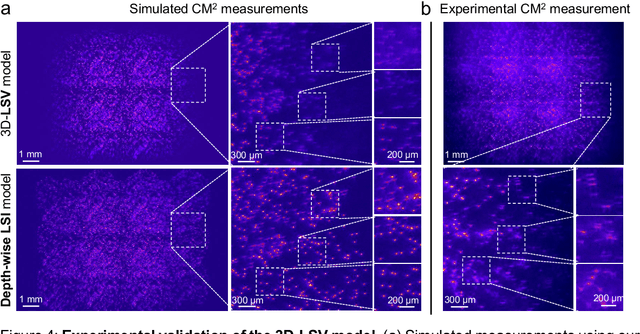
Computational Miniature Mesoscope (CM2) is a recently developed computational imaging system that enables single-shot 3D imaging across a wide field-of-view (FOV) using a compact optical platform. In this work, we present CM2 V2 - an advanced CM2 system that integrates novel hardware improvements and a new deep learning reconstruction algorithm. The platform features a 3D-printed freeform LED collimator that achieves ~80$\%$ excitation efficiency - a ~3x improvement over our V1 design, and a hybrid emission filter design that improves the measurement contrast by >5x. The new computational pipeline includes an accurate and computationally efficient 3D linear shift-variant (LSV) forward model and a novel multi-module CM2Net deep learning model. As compared to the model-based deconvolution in our V1 system, CM2Net achieves ~8x better axial localization and ~1400x faster reconstruction speed. In addition, CM2Net consistently achieves high detection performance and superior axial localization across a wide FOV at a variety of conditions. Trained entirely on our 3D-LSV simulator generated training data set, CM2Net generalizes well to real experiments. We experimentally demonstrate that CM2Net achieves accurate 3D reconstruction of fluorescent emitters across a ~7-mm FOV and 800-$\mu$m depth, and provides ~7-$\mu$m lateral and ~25-$\mu$m axial resolution. We anticipate that this simple and low-cost computational miniature imaging system will be impactful to many large-scale 3D fluorescence imaging applications.
Deep learning approach to Fourier ptychographic microscopy
Jul 30, 2018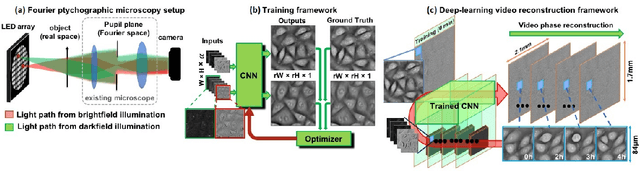
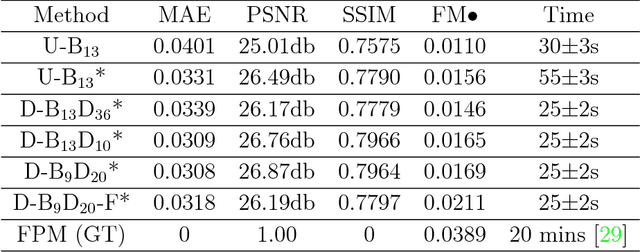
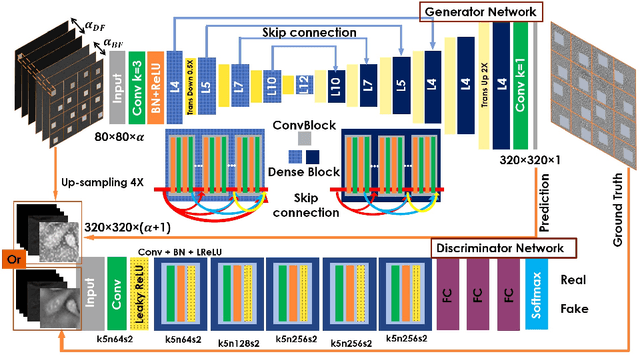
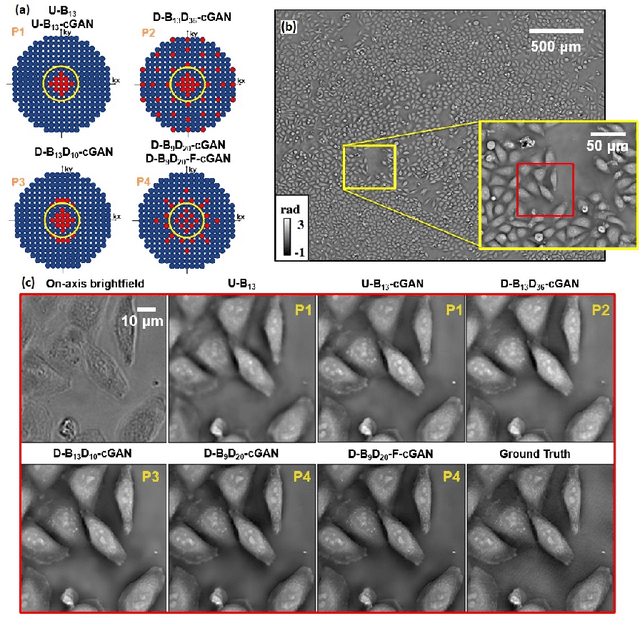
Convolutional neural networks (CNNs) have gained tremendous success in solving complex inverse problems. The aim of this work is to develop a novel CNN framework to reconstruct video sequence of dynamic live cells captured using a computational microscopy technique, Fourier ptychographic microscopy (FPM). The unique feature of the FPM is its capability to reconstruct images with both wide field-of-view (FOV) and high resolution, i.e. a large space-bandwidth-product (SBP), by taking a series of low resolution intensity images. For live cell imaging, a single FPM frame contains thousands of cell samples with different morphological features. Our idea is to fully exploit the statistical information provided by this large spatial ensemble so as to make predictions in a sequential measurement, without using any additional temporal dataset. Specifically, we show that it is possible to reconstruct high-SBP dynamic cell videos by a CNN trained only on the first FPM dataset captured at the beginning of a time-series experiment. Our CNN approach reconstructs a 12800X10800 pixels phase image using only ~25 seconds, a 50X speedup compared to the model-based FPM algorithm. In addition, the CNN further reduces the required number of images in each time frame by ~6X. Overall, this significantly improves the imaging throughput by reducing both the acquisition and computational times. The proposed CNN is based on the conditional generative adversarial network (cGAN) framework. Additionally, we also exploit transfer learning so that our pre-trained CNN can be further optimized to image other cell types. Our technique demonstrates a promising deep learning approach to continuously monitor large live-cell populations over an extended time and gather useful spatial and temporal information with sub-cellular resolution.
Hyperspectral Light Field Stereo Matching
Sep 04, 2017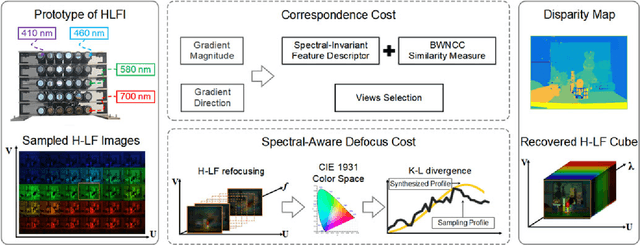
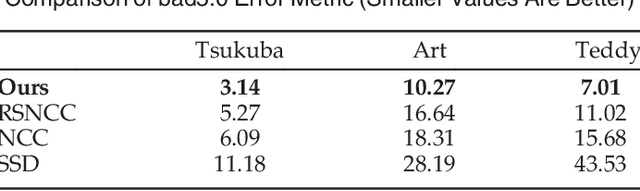
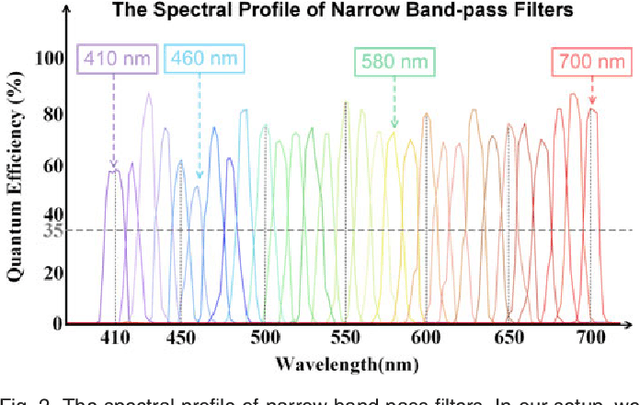
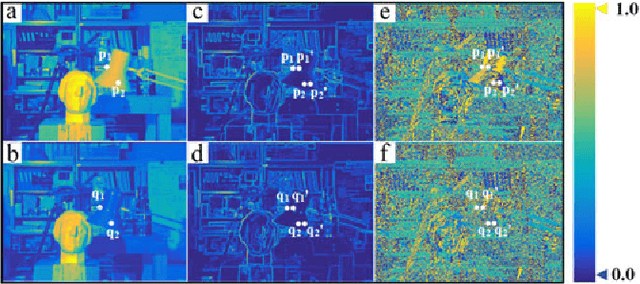
In this paper, we describe how scene depth can be extracted using a hyperspectral light field capture (H-LF) system. Our H-LF system consists of a 5 x 6 array of cameras, with each camera sampling a different narrow band in the visible spectrum. There are two parts to extracting scene depth. The first part is our novel cross-spectral pairwise matching technique, which involves a new spectral-invariant feature descriptor and its companion matching metric we call bidirectional weighted normalized cross correlation (BWNCC). The second part, namely, H-LF stereo matching, uses a combination of spectral-dependent correspondence and defocus cues that rely on BWNCC. These two new cost terms are integrated into a Markov Random Field (MRF) for disparity estimation. Experiments on synthetic and real H-LF data show that our approach can produce high-quality disparity maps. We also show that these results can be used to produce the complete plenoptic cube in addition to synthesizing all-focus and defocused color images under different sensor spectral responses.