 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Information Retrieval to Classify the Unstructured Data Content of Preferential Trade Agreements
Jan 23, 2024With the rapid proliferation of textual data, predicting long texts has emerged as a significant challenge in the domain of natural language processing. Traditional text prediction methods encounter substantial difficulties when grappling with long texts, primarily due to the presence of redundant and irrelevant information, which impedes the model's capacity to capture pivotal insights from the text. To address this issue, we introduce a novel approach to long-text classification and prediction. Initially, we employ embedding techniques to condense the long texts, aiming to diminish the redundancy therein. Subsequently,the Bidirectional Encoder Representations from Transformers (BERT) embedding method is utilized for text classification training. Experimental outcomes indicate that our method realizes considerable performance enhancements in classifying long texts of Preferential Trade Agreements. Furthermore, the condensation of text through embedding methods not only augments prediction accuracy but also substantially reduces computational complexity. Overall, this paper presents a strategy for long-text prediction, offering a valuable reference for researchers and engineers in the natural language processing sphere.
Block Modulating Video Compression: An Ultra Low Complexity Image Compression Encoder for Resource Limited Platforms
May 07, 2022
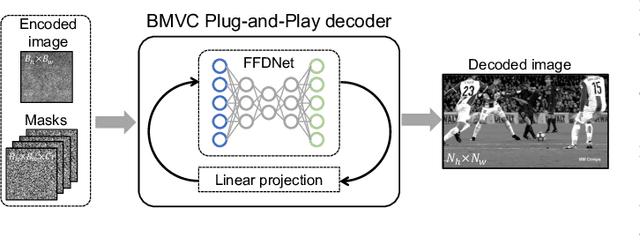
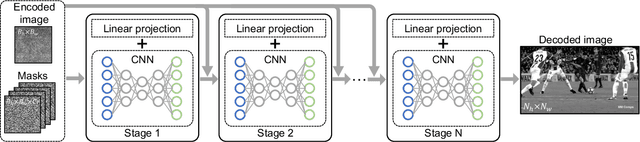

We consider the image and video compression on resource limited platforms. An ultra low-cost image encoder, named Block Modulating Video Compression (BMVC) with an encoding complexity ${\cal O}(1)$ is proposed to be implemented on mobile platforms with low consumption of power and computation resources. We also develop two types of BMVC decoders, implemented by deep neural networks. The first BMVC decoder is based on the Plug-and-Play (PnP) algorithm, which is flexible to different compression ratios. And the second decoder is a memory efficient end-to-end convolutional neural network, which aims for real-time decoding. Extensive results on the high definition images and videos demonstrate the superior performance of the proposed codec and the robustness against bit quantization.
Calibrated Hyperspectral Image Reconstruction via Graph-based Self-Tuning Network
Jan 04, 2022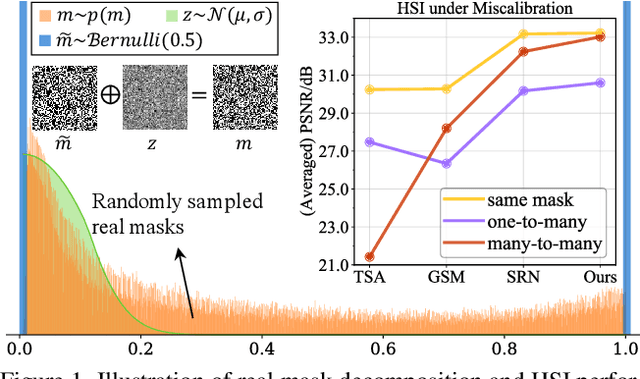
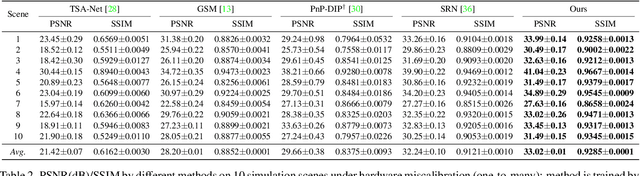
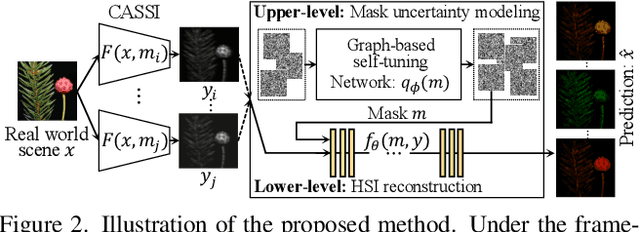
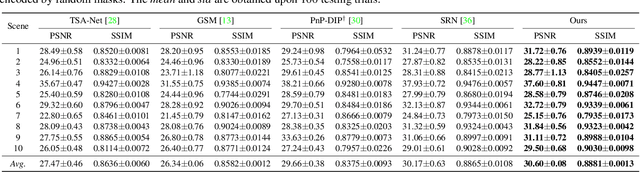
Recently, hyperspectral imaging (HSI) has attracted increasing research attention, especially for the ones based on a coded aperture snapshot spectral imaging (CASSI) system. Existing deep HSI reconstruction models are generally trained on paired data to retrieve original signals upon 2D compressed measurements given by a particular optical hardware mask in CASSI, during which the mask largely impacts the reconstruction performance and could work as a "model hyperparameter" governing on data augmentations. This mask-specific training style will lead to a hardware miscalibration issue, which sets up barriers to deploying deep HSI models among different hardware and noisy environments. To address this challenge, we introduce mask uncertainty for HSI with a complete variational Bayesian learning treatment and explicitly model it through a mask decomposition inspired by real hardware. Specifically, we propose a novel Graph-based Self-Tuning (GST) network to reason uncertainties adapting to varying spatial structures of masks among different hardware. Moreover, we develop a bilevel optimization framework to balance HSI reconstruction and uncertainty estimation, accounting for the hyperparameter property of masks. Extensive experimental results and model discussions validate the effectiveness (over 33/30 dB) of the proposed GST method under two miscalibration scenarios and demonstrate a highly competitive performance compared with the state-of-the-art well-calibrated methods. Our code and pre-trained model are available at https://github.com/Jiamian-Wang/mask_uncertainty_spectral_SCI
Self-supervised Neural Networks for Spectral Snapshot Compressive Imaging
Aug 28, 2021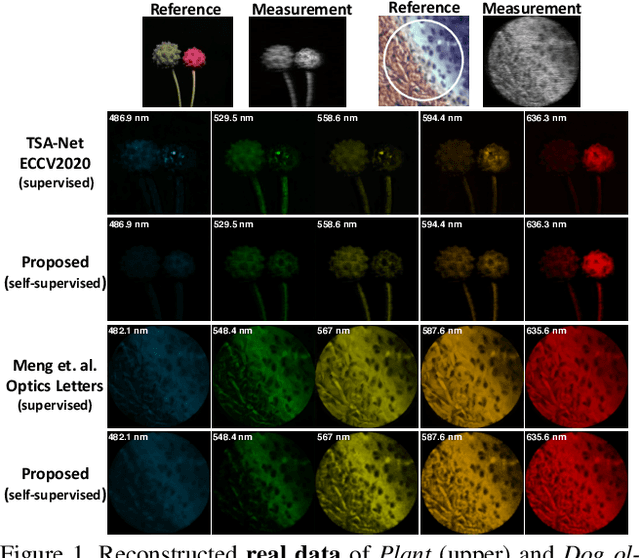
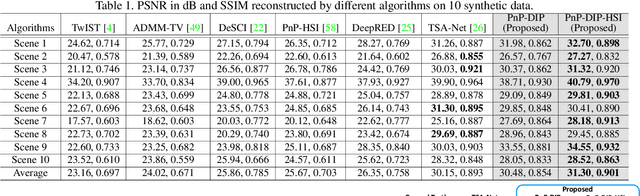
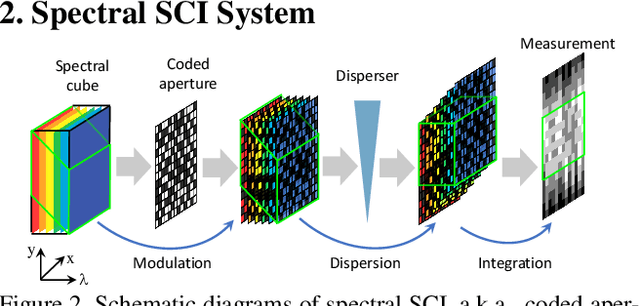

We consider using {\bf\em untrained neural networks} to solve the reconstruction problem of snapshot compressive imaging (SCI), which uses a two-dimensional (2D) detector to capture a high-dimensional (usually 3D) data-cube in a compressed manner. Various SCI systems have been built in recent years to capture data such as high-speed videos, hyperspectral images, and the state-of-the-art reconstruction is obtained by the deep neural networks. However, most of these networks are trained in an end-to-end manner by a large amount of corpus with sometimes simulated ground truth, measurement pairs. In this paper, inspired by the untrained neural networks such as deep image priors (DIP) and deep decoders, we develop a framework by integrating DIP into the plug-and-play regime, leading to a self-supervised network for spectral SCI reconstruction. Extensive synthetic and real data results show that the proposed algorithm without training is capable of achieving competitive results to the training based networks. Furthermore, by integrating the proposed method with a pre-trained deep denoising prior, we have achieved state-of-the-art results. {Our code is available at \url{https://github.com/mengziyi64/CASSI-Self-Supervised}.}