 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval
Mar 26, 2024The increasing prevalence of video clips has sparked growing interest in text-video retrieval. Recent advances focus on establishing a joint embedding space for text and video, relying on consistent embedding representations to compute similarity. However, the text content in existing datasets is generally short and concise, making it hard to fully describe the redundant semantics of a video. Correspondingly, a single text embedding may be less expressive to capture the video embedding and empower the retrieval. In this study, we propose a new stochastic text modeling method T-MASS, i.e., text is modeled as a stochastic embedding, to enrich text embedding with a flexible and resilient semantic range, yielding a text mass. To be specific, we introduce a similarity-aware radius module to adapt the scale of the text mass upon the given text-video pairs. Plus, we design and develop a support text regularization to further control the text mass during the training. The inference pipeline is also tailored to fully exploit the text mass for accurate retrieval. Empirical evidence suggests that T-MASS not only effectively attracts relevant text-video pairs while distancing irrelevant ones, but also enables the determination of precise text embeddings for relevant pairs. Our experimental results show a substantial improvement of T-MASS over baseline (3% to 6.3% by R@1). Also, T-MASS achieves state-of-the-art performance on five benchmark datasets, including MSRVTT, LSMDC, DiDeMo, VATEX, and Charades.
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Mar 17, 2024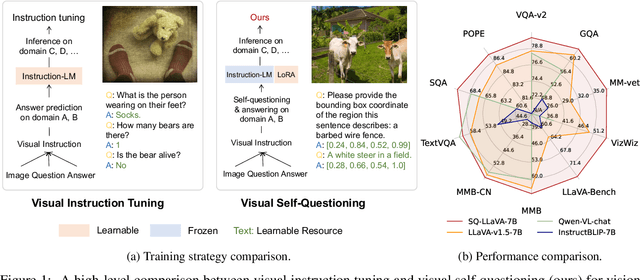
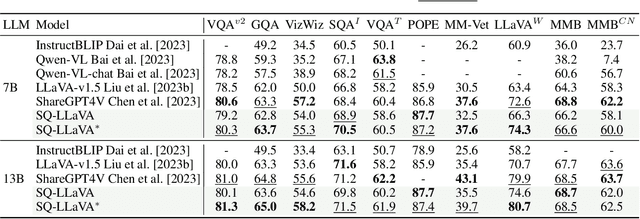
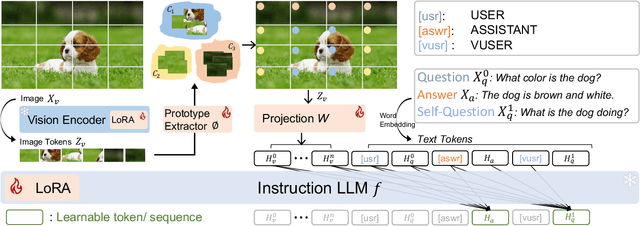
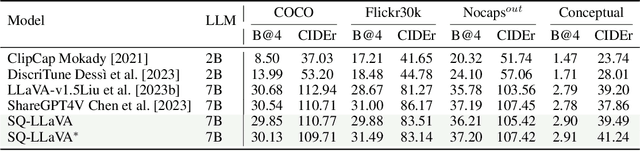
Recent advancements in the vision-language model have shown notable generalization in vision-language tasks after visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which are costly to obtain. However, the image contains rich contextual information that has been largely under-explored. This paper first attempts to harness this overlooked context within visual instruction data, training the model to self-supervised `learning' how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a consistent performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.
Cooperative Hardware-Prompt Learning for Snapshot Compressive Imaging
Jun 01, 2023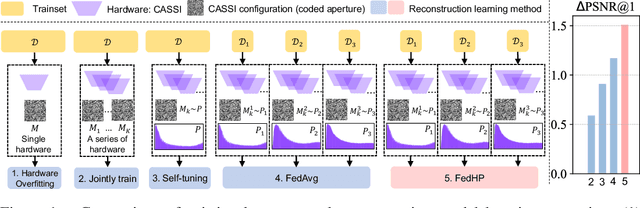
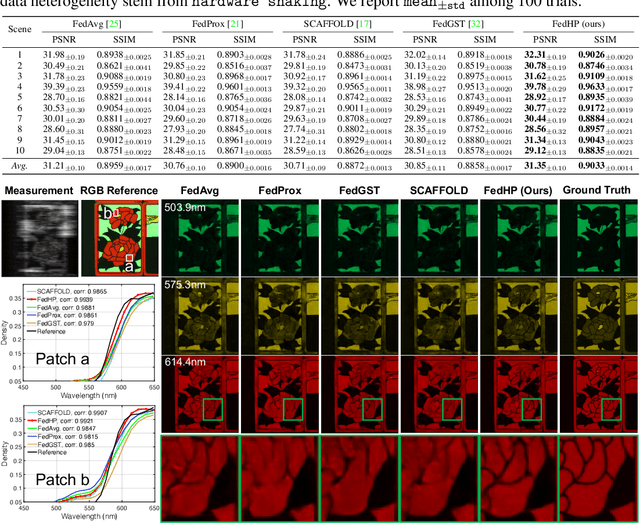
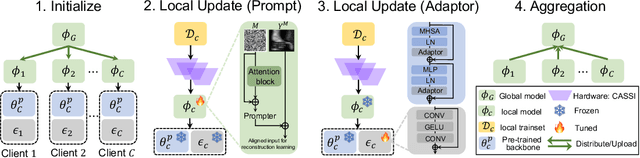
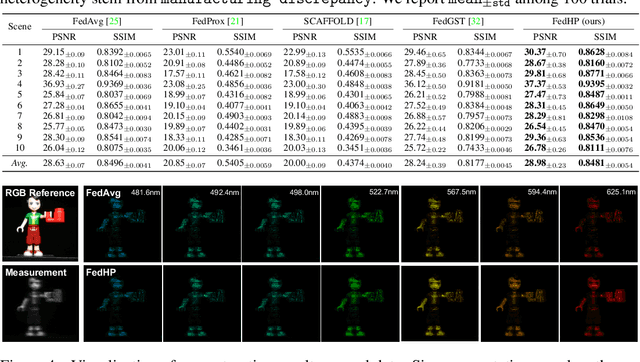
Snapshot compressive imaging emerges as a promising technology for acquiring real-world hyperspectral signals. It uses an optical encoder and compressively produces the 2D measurement, followed by which the 3D hyperspectral data can be retrieved via training a deep reconstruction network. Existing reconstruction models are trained with a single hardware instance, whose performance is vulnerable to hardware perturbation or replacement, demonstrating an overfitting issue to the physical configuration. This defect limits the deployment of pre-trained models since they would suffer from large performance degradation when are assembled to unseen hardware. To better facilitate the reconstruction model with new hardware, previous efforts resort to centralized training by collecting multi-hardware and data, which is impractical when dealing with proprietary assets among institutions. In light of this, federated learning (FL) has become a feasible solution to enable cross-hardware cooperation without breaking privacy. However, the naive FedAvg is subject to client drift upon data heterogeneity owning to the hardware inconsistency. In this work, we tackle this challenge by marrying prompt tuning with FL to snapshot compressive imaging for the first time and propose an federated hardware-prompt learning (FedHP) method. Rather than mitigating the client drift by rectifying the gradients, which only takes effect on the learning manifold but fails to touch the heterogeneity rooted in the input data space, the proposed FedHP globally learns a hardware-conditioned prompter to align the data distribution, which serves as an indicator of the data inconsistency stemming from different pre-defined coded apertures. Extensive experiments demonstrate that the proposed method well coordinates the pre-trained model to indeterminate hardware configurations.
Iterative Soft Shrinkage Learning for Efficient Image Super-Resolution
Mar 16, 2023The field of image super-resolution (SR) has witnessed extensive neural network designs from CNN to transformer architectures. However, prevailing SR models suffer from prohibitive memory footprint and intensive computations, which limits further deployment on computational-constrained platforms. In this work, we investigate the potential of network pruning for super-resolution to take advantage of off-the-shelf network designs and reduce the underlying computational overhead. Two main challenges remain in applying pruning methods for SR. First, the widely-used filter pruning technique reflects limited granularity and restricted adaptability to diverse network structures. Second, existing pruning methods generally operate upon a pre-trained network for the sparse structure determination, failing to get rid of dense model training in the traditional SR paradigm. To address these challenges, we adopt unstructured pruning with sparse models directly trained from scratch. Specifically, we propose a novel Iterative Soft Shrinkage-Percentage (ISS-P) method by optimizing the sparse structure of a randomly initialized network at each iteration and tweaking unimportant weights with a small amount proportional to the magnitude scale on-the-fly. We observe that the proposed ISS-P could dynamically learn sparse structures adapting to the optimization process and preserve the sparse model's trainability by yielding a more regularized gradient throughput. Experiments on benchmark datasets demonstrate the effectiveness of the proposed ISS-P compared with state-of-the-art methods over diverse network architectures.
S^2-Transformer for Mask-Aware Hyperspectral Image Reconstruction
Sep 24, 2022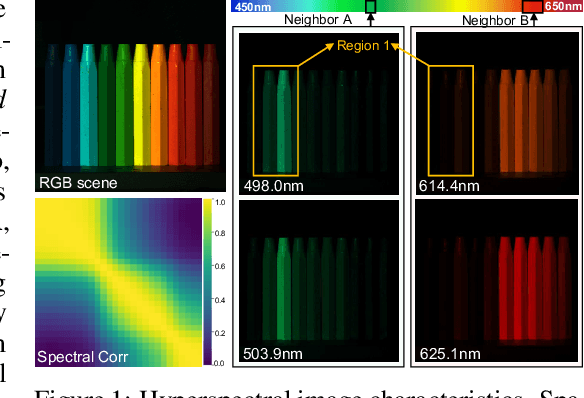
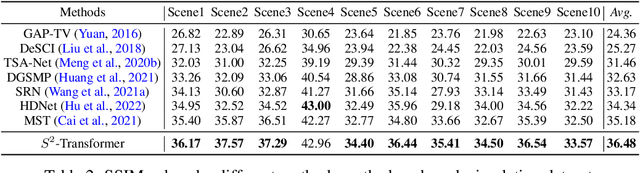
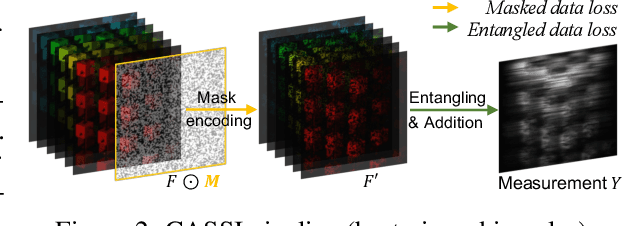
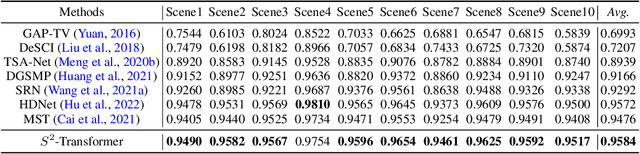
The technology of hyperspectral imaging (HSI) records the visual information upon long-range-distributed spectral wavelengths. A representative hyperspectral image acquisition procedure conducts a 3D-to-2D encoding by the coded aperture snapshot spectral imager (CASSI), and requires a software decoder for the 3D signal reconstruction. Based on this encoding procedure, two major challenges stand in the way of a high-fidelity reconstruction: (i) To obtain 2D measurements, CASSI dislocates multiple channels by disperser-titling and squeezes them onto the same spatial region, yielding an entangled data loss. (ii) The physical coded aperture (mask) will lead to a masked data loss by selectively blocking the pixel-wise light exposure. To tackle these challenges, we propose a spatial-spectral (S2-) transformer architecture with a mask-aware learning strategy. Firstly, we simultaneously leverage spatial and spectral attention modelings to disentangle the blended information in the 2D measurement along both two dimensions. A series of Transformer structures across spatial & spectral clues are systematically designed, which considers the information inter-dependency between the two-fold cues. Secondly, the masked pixels will induce higher prediction difficulty and should be treated differently from unmasked ones. Thereby, we adaptively prioritize the loss penalty attributing to the mask structure by inferring the difficulty-level upon the mask-aware prediction. Our proposed method not only sets a new state-of-the-art quantitatively, but also yields a better perceptual quality upon structured areas.
Calibrated Hyperspectral Image Reconstruction via Graph-based Self-Tuning Network
Jan 04, 2022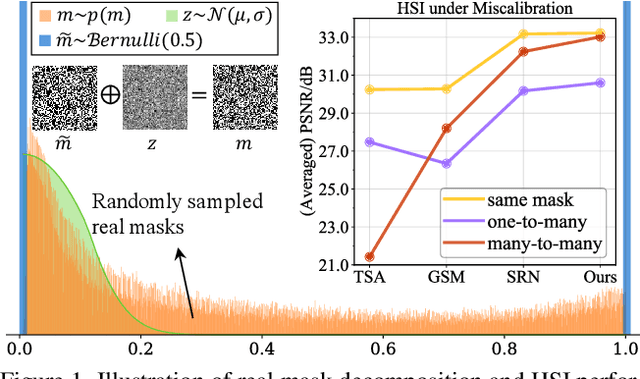
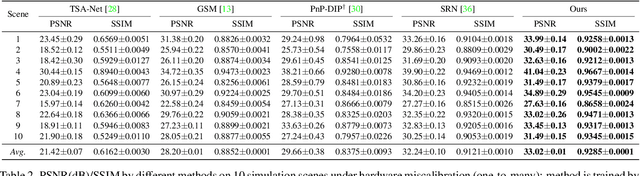
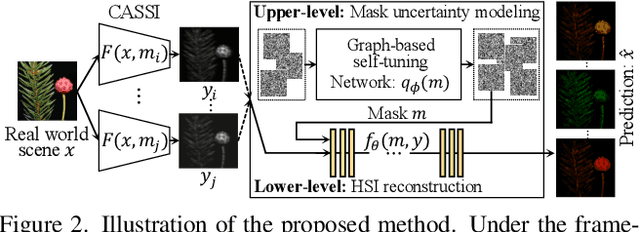
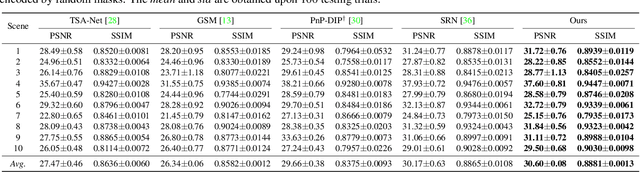
Recently, hyperspectral imaging (HSI) has attracted increasing research attention, especially for the ones based on a coded aperture snapshot spectral imaging (CASSI) system. Existing deep HSI reconstruction models are generally trained on paired data to retrieve original signals upon 2D compressed measurements given by a particular optical hardware mask in CASSI, during which the mask largely impacts the reconstruction performance and could work as a "model hyperparameter" governing on data augmentations. This mask-specific training style will lead to a hardware miscalibration issue, which sets up barriers to deploying deep HSI models among different hardware and noisy environments. To address this challenge, we introduce mask uncertainty for HSI with a complete variational Bayesian learning treatment and explicitly model it through a mask decomposition inspired by real hardware. Specifically, we propose a novel Graph-based Self-Tuning (GST) network to reason uncertainties adapting to varying spatial structures of masks among different hardware. Moreover, we develop a bilevel optimization framework to balance HSI reconstruction and uncertainty estimation, accounting for the hyperparameter property of masks. Extensive experimental results and model discussions validate the effectiveness (over 33/30 dB) of the proposed GST method under two miscalibration scenarios and demonstrate a highly competitive performance compared with the state-of-the-art well-calibrated methods. Our code and pre-trained model are available at https://github.com/Jiamian-Wang/mask_uncertainty_spectral_SCI
A New Backbone for Hyperspectral Image Reconstruction
Sep 09, 2021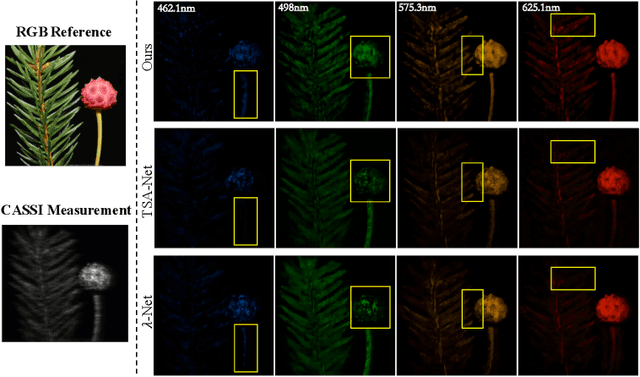
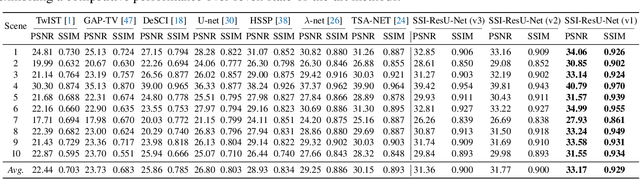
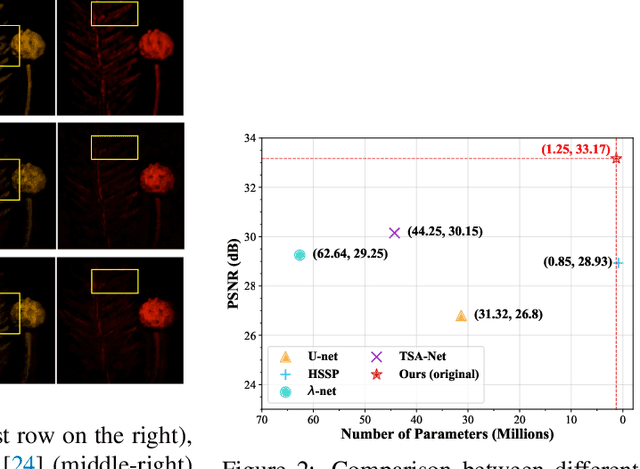
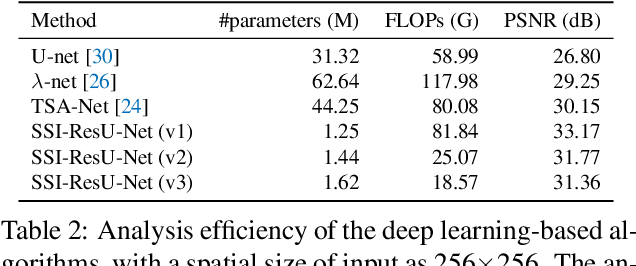
The study of 3D hyperspectral image (HSI) reconstruction refers to the inverse process of snapshot compressive imaging, during which the optical system, e.g., the coded aperture snapshot spectral imaging (CASSI) system, captures the 3D spatial-spectral signal and encodes it to a 2D measurement. While numerous sophisticated neural networks have been elaborated for end-to-end reconstruction, trade-offs still need to be made among performance, efficiency (training and inference time), and feasibility (the ability of restoring high resolution HSI on limited GPU memory). This raises a challenge to design a new baseline to conjointly meet the above requirements. In this paper, we fill in this blank by proposing a Spatial/Spectral Invariant Residual U-Net, namely SSI-ResU-Net. It differentiates with U-Net in three folds--1) scale/spectral-invariant learning, 2) nested residual learning, and 3) computational efficiency. Benefiting from these three modules, the proposed SSI-ResU-Net outperforms the current state-of-the-art method TSA-Net by over 3 dB in PSNR and 0.036 in SSIM while only using 2.82% trainable parameters. To the greatest extent, SSI-ResU-Net achieves competing performance with over 77.3% reduction in terms of floating-point operations (FLOPs), which for the first time, makes high-resolution HSI reconstruction feasible under practical application scenarios. Code and pre-trained models are made available at https://github.com/Jiamian-Wang/HSI_baseline.