 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-guided Hierarchical Harmonization Network for Efficient Image Dehazing
Mar 03, 2025Image dehazing is a crucial task that involves the enhancement of degraded images to recover their sharpness and textures. While vision Transformers have exhibited impressive results in diverse dehazing tasks, their quadratic complexity and lack of dehazing priors pose significant drawbacks for real-world applications. In this paper, guided by triple priors, Bright Channel Prior (BCP), Dark Channel Prior (DCP), and Histogram Equalization (HE), we propose a \textit{P}rior-\textit{g}uided Hierarchical \textit{H}armonization Network (PGH$^2$Net) for image dehazing. PGH$^2$Net is built upon the UNet-like architecture with an efficient encoder and decoder, consisting of two module types: (1) Prior aggregation module that injects B/DCP and selects diverse contexts with gating attention. (2) Feature harmonization modules that subtract low-frequency components from spatial and channel aspects and learn more informative feature distributions to equalize the feature maps.
Detail Matters: Mamba-Inspired Joint Unfolding Network for Snapshot Spectral Compressive Imaging
Jan 02, 2025



In the coded aperture snapshot spectral imaging system, Deep Unfolding Networks (DUNs) have made impressive progress in recovering 3D hyperspectral images (HSIs) from a single 2D measurement. However, the inherent nonlinear and ill-posed characteristics of HSI reconstruction still pose challenges to existing methods in terms of accuracy and stability. To address this issue, we propose a Mamba-inspired Joint Unfolding Network (MiJUN), which integrates physics-embedded DUNs with learning-based HSI imaging. Firstly, leveraging the concept of trapezoid discretization to expand the representation space of unfolding networks, we introduce an accelerated unfolding network scheme. This approach can be interpreted as a generalized accelerated half-quadratic splitting with a second-order differential equation, which reduces the reliance on initial optimization stages and addresses challenges related to long-range interactions. Crucially, within the Mamba framework, we restructure the Mamba-inspired global-to-local attention mechanism by incorporating a selective state space model and an attention mechanism. This effectively reinterprets Mamba as a variant of the Transformer} architecture, improving its adaptability and efficiency. Furthermore, we refine the scanning strategy with Mamba by integrating the tensor mode-$k$ unfolding into the Mamba network. This approach emphasizes the low-rank properties of tensors along various modes, while conveniently facilitating 12 scanning directions. Numerical and visual comparisons on both simulation and real datasets demonstrate the superiority of our proposed MiJUN, and achieving overwhelming detail representation.
Latent Diffusion Prior Enhanced Deep Unfolding for Spectral Image Reconstruction
Nov 24, 2023Snapshot compressive spectral imaging reconstruction aims to reconstruct three-dimensional spatial-spectral images from a single-shot two-dimensional compressed measurement. Existing state-of-the-art methods are mostly based on deep unfolding structures but have intrinsic performance bottlenecks: $i$) the ill-posed problem of dealing with heavily degraded measurement, and $ii$) the regression loss-based reconstruction models being prone to recover images with few details. In this paper, we introduce a generative model, namely the latent diffusion model (LDM), to generate degradation-free prior to enhance the regression-based deep unfolding method. Furthermore, to overcome the large computational cost challenge in LDM, we propose a lightweight model to generate knowledge priors in deep unfolding denoiser, and integrate these priors to guide the reconstruction process for compensating high-quality spectral signal details. Numeric and visual comparisons on synthetic and real-world datasets illustrate the superiority of our proposed method in both reconstruction quality and computational efficiency. Code will be released.
Cooperative Hardware-Prompt Learning for Snapshot Compressive Imaging
Jun 01, 2023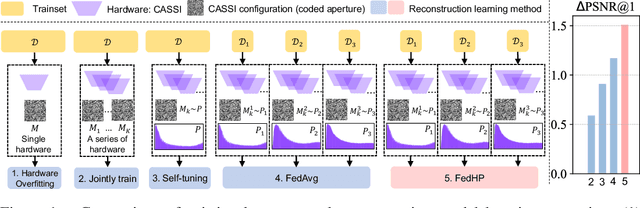
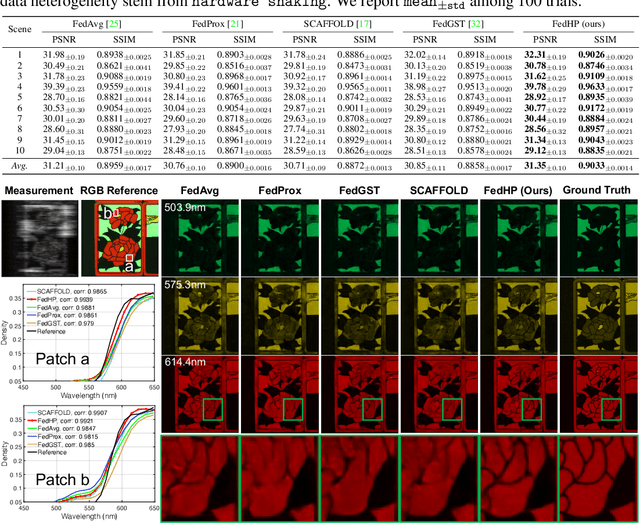
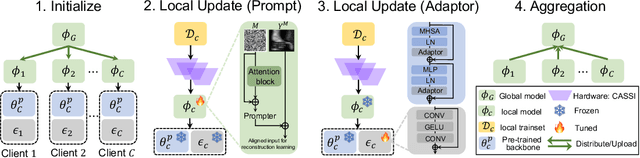
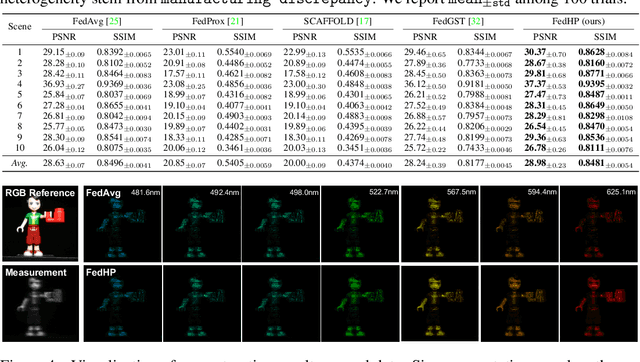
Snapshot compressive imaging emerges as a promising technology for acquiring real-world hyperspectral signals. It uses an optical encoder and compressively produces the 2D measurement, followed by which the 3D hyperspectral data can be retrieved via training a deep reconstruction network. Existing reconstruction models are trained with a single hardware instance, whose performance is vulnerable to hardware perturbation or replacement, demonstrating an overfitting issue to the physical configuration. This defect limits the deployment of pre-trained models since they would suffer from large performance degradation when are assembled to unseen hardware. To better facilitate the reconstruction model with new hardware, previous efforts resort to centralized training by collecting multi-hardware and data, which is impractical when dealing with proprietary assets among institutions. In light of this, federated learning (FL) has become a feasible solution to enable cross-hardware cooperation without breaking privacy. However, the naive FedAvg is subject to client drift upon data heterogeneity owning to the hardware inconsistency. In this work, we tackle this challenge by marrying prompt tuning with FL to snapshot compressive imaging for the first time and propose an federated hardware-prompt learning (FedHP) method. Rather than mitigating the client drift by rectifying the gradients, which only takes effect on the learning manifold but fails to touch the heterogeneity rooted in the input data space, the proposed FedHP globally learns a hardware-conditioned prompter to align the data distribution, which serves as an indicator of the data inconsistency stemming from different pre-defined coded apertures. Extensive experiments demonstrate that the proposed method well coordinates the pre-trained model to indeterminate hardware configurations.
Adaptive Deep PnP Algorithm for Video Snapshot Compressive Imaging
Jan 28, 2022
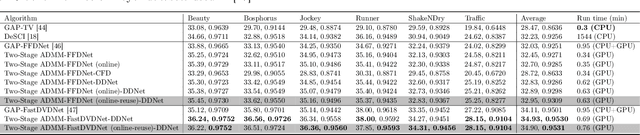


Video Snapshot compressive imaging (SCI) is a promising technique to capture high-speed videos, which transforms the imaging speed from the detector to mask modulating and only needs a single measurement to capture multiple frames. The algorithm to reconstruct high-speed frames from the measurement plays a vital role in SCI. In this paper, we consider the promising reconstruction algorithm framework, namely plug-and-play (PnP), which is flexible to the encoding process comparing with other deep learning networks. One drawback of existing PnP algorithms is that they use a pre-trained denoising network as a plugged prior while the training data of the network might be different from the task in real applications. Towards this end, in this work, we propose the online PnP algorithm which can adaptively update the network's parameters within the PnP iteration; this makes the denoising network more applicable to the desired data in the SCI reconstruction. Furthermore, for color video imaging, RGB frames need to be recovered from Bayer pattern or named demosaicing in the camera pipeline. To address this challenge, we design a two-stage reconstruction framework to optimize these two coupled ill-posed problems and introduce a deep demosaicing prior specifically for video demosaicing which does not have much past works instead of using single image demosaicing networks. Extensive results on both simulation and real datasets verify the superiority of our adaptive deep PnP algorithm.
Spectral Compressive Imaging Reconstruction Using Convolution and Spectral Contextual Transformer
Jan 15, 2022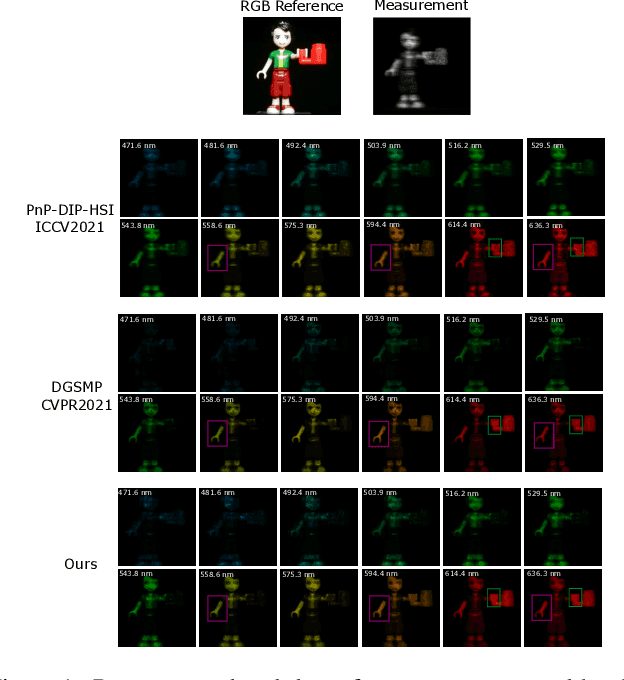
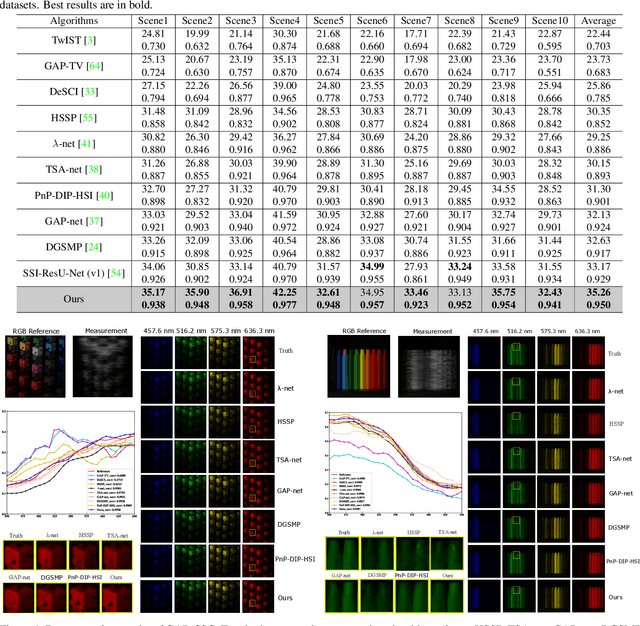
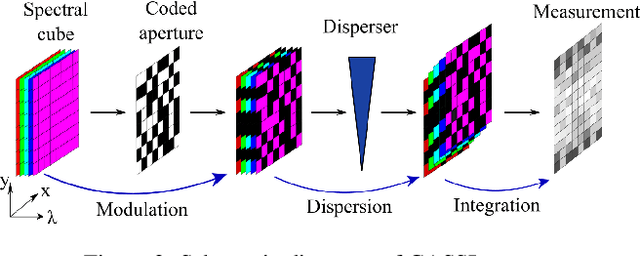
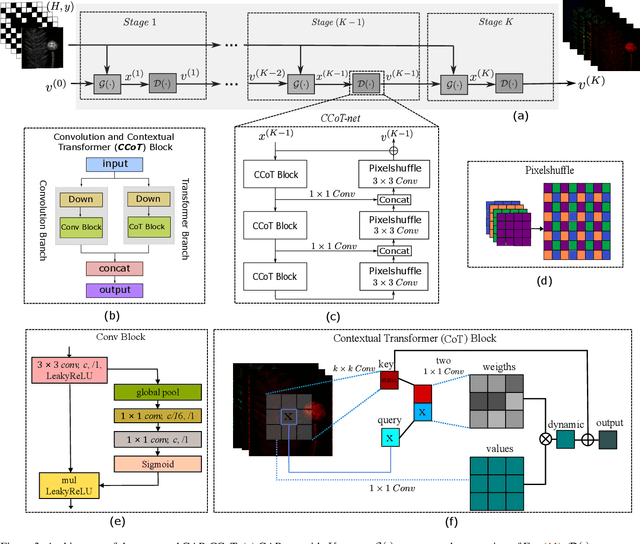
Spectral compressive imaging (SCI) is able to encode the high-dimensional hyperspectral image to a 2D measurement, and then uses algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and the state-of-the-art (SOTA) reconstruction methods generally face the problem of long reconstruction time and/or poor detail recovery. In this paper, we propose a novel hybrid network module, namely CSCoT (Convolution and Spectral Contextual Transformer) block, which can acquire the local perception of convolution and the global perception of transformer simultaneously, and is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CSCoT block into deep unfolding framework based on the generalized alternating projection algorithm, and further propose the GAP-CSCoT network. Finally, we apply the GAP-CSCoT algorithm to SCI reconstruction. Through the experiments of extensive synthetic and real data, our proposed model achieves higher reconstruction quality ($>$2dB in PSNR on simulated benchmark datasets) and shorter running time than existing SOTA algorithms by a large margin. The code and models will be released to the public.