 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Closed-Loop Robotic Data Generation via Semantic Planning and Autonomous Causal Environment Reset
Mar 12, 2026The acquisition of large-scale physical interaction data, a critical prerequisite for modern robot learning, is severely bottlenecked by the prohibitive cost and scalability limits of human-in-the-loop collection paradigms. To break this barrier, we introduce Robust Autonomous Data Acquisition for Robotics (RADAR), a fully autonomous, closed-loop data generation engine that completely removes human intervention from the collection cycle. RADAR elegantly divides the cognitive load into a four-module pipeline. Anchored by 2-5 3D human demonstrations as geometric priors, a Vision-Language Model first orchestrates scene-relevant task generation via precise semantic object grounding and skill retrieval. Next, a Graph Neural Network policy translates these subtasks into physical actions via in-context imitation learning. Following execution, the VLM performs automated success evaluation using a structured Visual Question Answering pipeline. Finally, to shatter the bottleneck of manual resets, a Finite State Machine orchestrates an autonomous environment reset and asymmetric data routing mechanism. Driven by simultaneous forward-reverse planning with a strict Last-In, First-Out causal sequence, the system seamlessly restores unstructured workspaces and robustly recovers from execution failures. This continuous brain-cerebellum synergy transforms data collection into a self-sustaining process. Extensive evaluations highlight RADAR's exceptional versatility. In simulation, our framework achieves up to 90% success rates on complex, long-horizon tasks, effortlessly solving challenges where traditional baselines plummet to near-zero performance. In real-world deployments, the system reliably executes diverse, contact-rich skills (e.g., deformable object manipulation) via few-shot adaptation without domain-specific fine-tuning, providing a highly scalable paradigm for robotic data acquisition.
Concat-ID: Towards Universal Identity-Preserving Video Synthesis
Mar 18, 2025We present Concat-ID, a unified framework for identity-preserving video generation. Concat-ID employs Variational Autoencoders to extract image features, which are concatenated with video latents along the sequence dimension, leveraging solely 3D self-attention mechanisms without the need for additional modules. A novel cross-video pairing strategy and a multi-stage training regimen are introduced to balance identity consistency and facial editability while enhancing video naturalness. Extensive experiments demonstrate Concat-ID's superiority over existing methods in both single and multi-identity generation, as well as its seamless scalability to multi-subject scenarios, including virtual try-on and background-controllable generation. Concat-ID establishes a new benchmark for identity-preserving video synthesis, providing a versatile and scalable solution for a wide range of applications.
PoseCrafter: One-Shot Personalized Video Synthesis Following Flexible Poses
May 23, 2024



In this paper, we introduce PoseCrafter, a one-shot method for personalized video generation following the control of flexible poses. Built upon Stable Diffusion and ControlNet, we carefully design an inference process to produce high-quality videos without the corresponding ground-truth frames. First, we select an appropriate reference frame from the training video and invert it to initialize all latent variables for generation. Then, we insert the corresponding training pose into the target pose sequences to enhance faithfulness through a trained temporal attention module. Furthermore, to alleviate the face and hand degradation resulting from discrepancies between poses of training videos and inference poses, we implement simple latent editing through an affine transformation matrix involving facial and hand landmarks. Extensive experiments on several datasets demonstrate that PoseCrafter achieves superior results to baselines pre-trained on a vast collection of videos under 8 commonly used metrics. Besides, PoseCrafter can follow poses from different individuals or artificial edits and simultaneously retain the human identity in an open-domain training video.
Diffusion Models and Semi-Supervised Learners Benefit Mutually with Few Labels
Feb 21, 2023
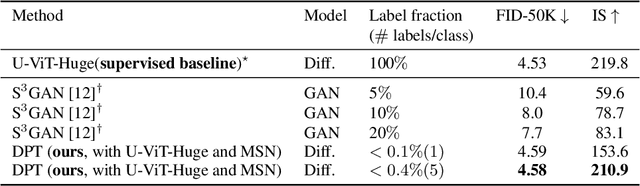
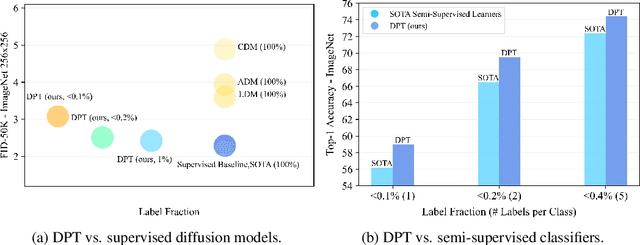
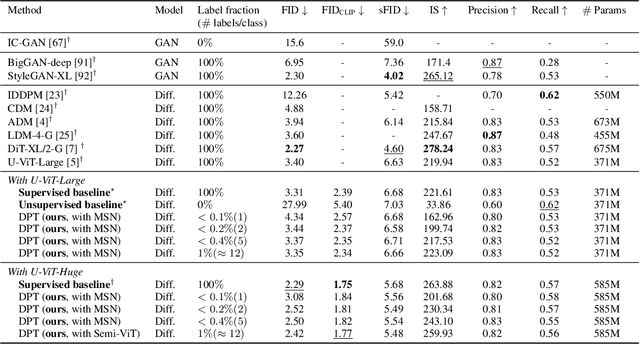
We propose a three-stage training strategy called dual pseudo training (DPT) for conditional image generation and classification in semi-supervised learning. First, a classifier is trained on partially labeled data and predicts pseudo labels for all data. Second, a conditional generative model is trained on all data with pseudo labels and generates pseudo images given labels. Finally, the classifier is trained on real data augmented by pseudo images with labels. We demonstrate large-scale diffusion models and semi-supervised learners benefit mutually with a few labels via DPT. In particular, on the ImageNet 256x256 generation benchmark, DPT can generate realistic, diverse, and semantically correct images with very few labels. With two (i.e., < 0.2%) and five (i.e., < 0.4%) labels per class, DPT achieves an FID of 3.44 and 3.37 respectively, outperforming strong diffusion models with full labels, such as IDDPM, CDM, ADM, and LDM. Besides, DPT outperforms competitive semi-supervised baselines substantially on ImageNet classification benchmarks with one, two, and five labels per class, achieving state-of-the-art top-1 accuracies of 59.0 (+2.8), 69.5 (+3.0), and 73.6 (+1.2) respectively.
Spatial-Temporal Transformer for Video Snapshot Compressive Imaging
Sep 08, 2022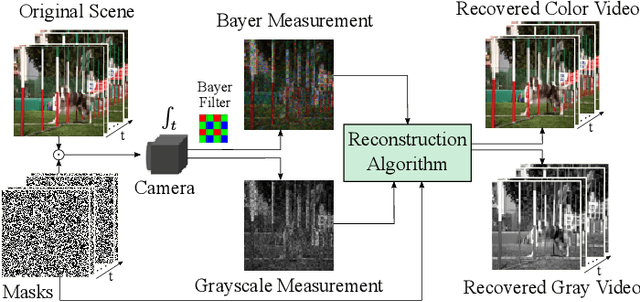
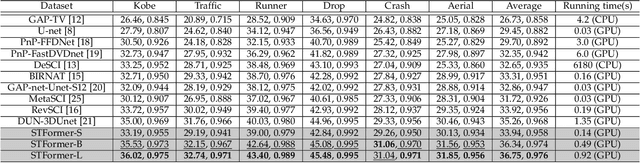
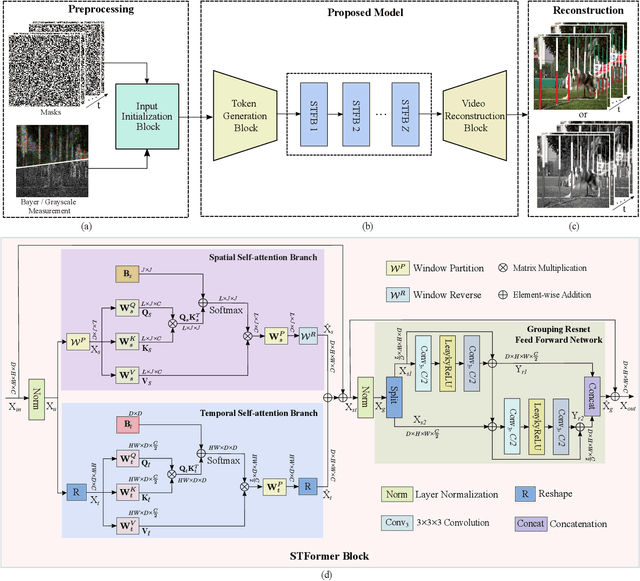
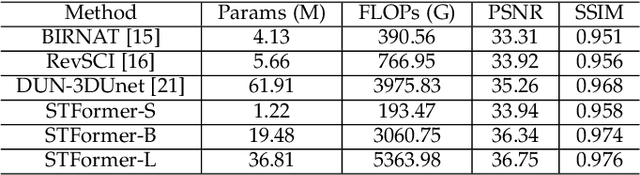
Video snapshot compressive imaging (SCI) captures multiple sequential video frames by a single measurement using the idea of computational imaging. The underlying principle is to modulate high-speed frames through different masks and these modulated frames are summed to a single measurement captured by a low-speed 2D sensor (dubbed optical encoder); following this, algorithms are employed to reconstruct the desired high-speed frames (dubbed software decoder) if needed. In this paper, we consider the reconstruction algorithm in video SCI, i.e., recovering a series of video frames from a compressed measurement. Specifically, we propose a Spatial-Temporal transFormer (STFormer) to exploit the correlation in both spatial and temporal domains. STFormer network is composed of a token generation block, a video reconstruction block, and these two blocks are connected by a series of STFormer blocks. Each STFormer block consists of a spatial self-attention branch, a temporal self-attention branch and the outputs of these two branches are integrated by a fusion network. Extensive results on both simulated and real data demonstrate the state-of-the-art performance of STFormer. The code and models are publicly available at https://github.com/ucaswangls/STFormer.git
Deep Generative Modeling on Limited Data with Regularization by Nontransferable Pre-trained Models
Aug 30, 2022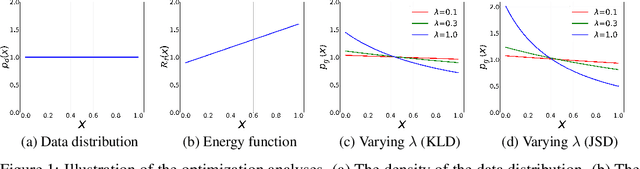
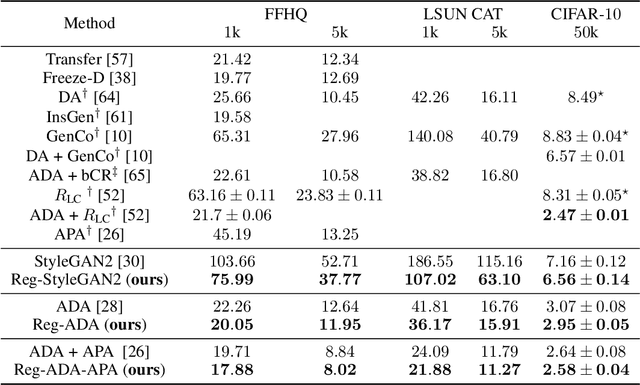
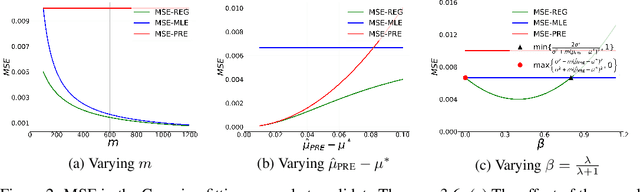

Deep generative models (DGMs) are data-eager. Essentially, it is because learning a complex model on limited data suffers from a large variance and easily overfits. Inspired by the \emph{bias-variance dilemma}, we propose \emph{regularized deep generative model} (Reg-DGM), which leverages a nontransferable pre-trained model to reduce the variance of generative modeling with limited data. Formally, Reg-DGM optimizes a weighted sum of a certain divergence between the data distribution and the DGM and the expectation of an energy function defined by the pre-trained model w.r.t. the DGM. Theoretically, we characterize the existence and uniqueness of the global minimum of Reg-DGM in the nonparametric setting and rigorously prove the statistical benefits of Reg-DGM w.r.t. the mean squared error and the expected risk in a simple yet representative Gaussian-fitting example. Empirically, it is quite flexible to specify the DGM and the pre-trained model in Reg-DGM. In particular, with a ResNet-18 classifier pre-trained on ImageNet and a data-dependent energy function, Reg-DGM consistently improves the generation performance of strong DGMs including StyleGAN2 and ADA on several benchmarks with limited data and achieves competitive results to the state-of-the-art methods.
Spectral Compressive Imaging Reconstruction Using Convolution and Spectral Contextual Transformer
Jan 15, 2022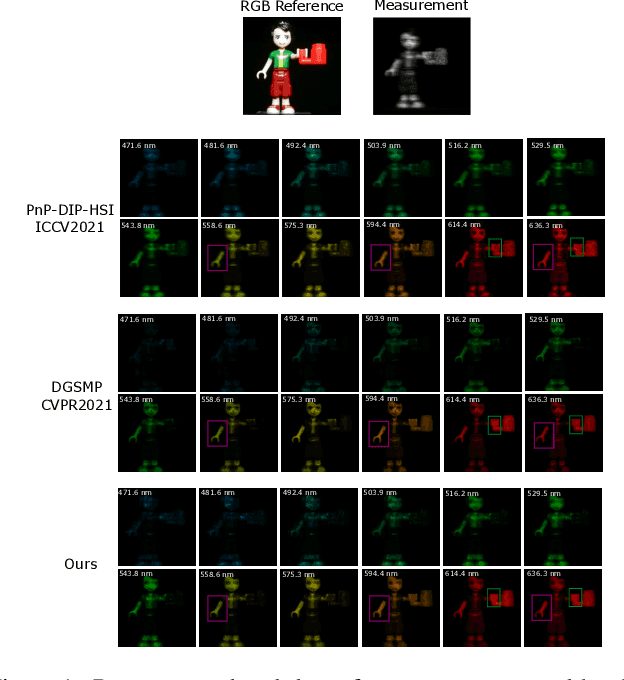
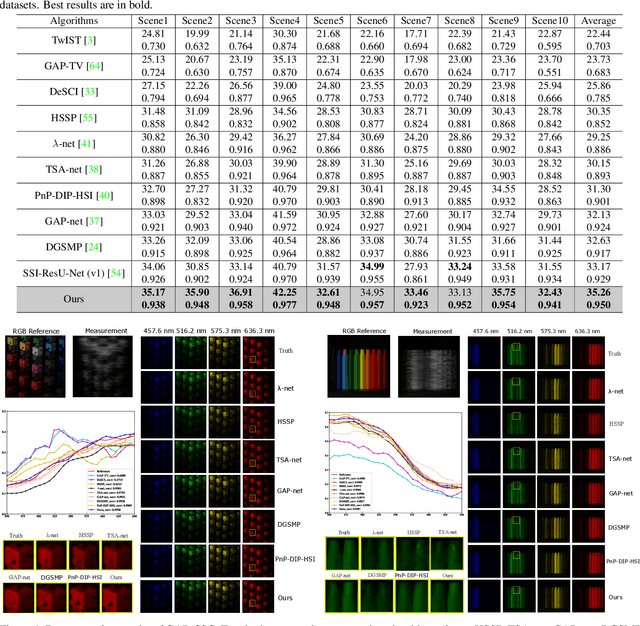
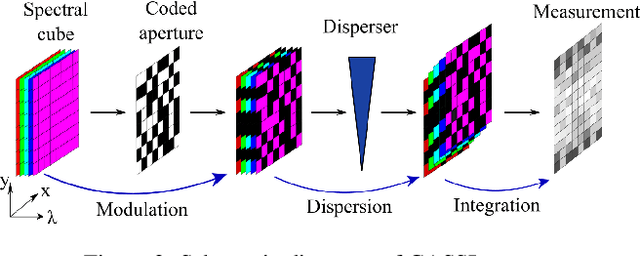
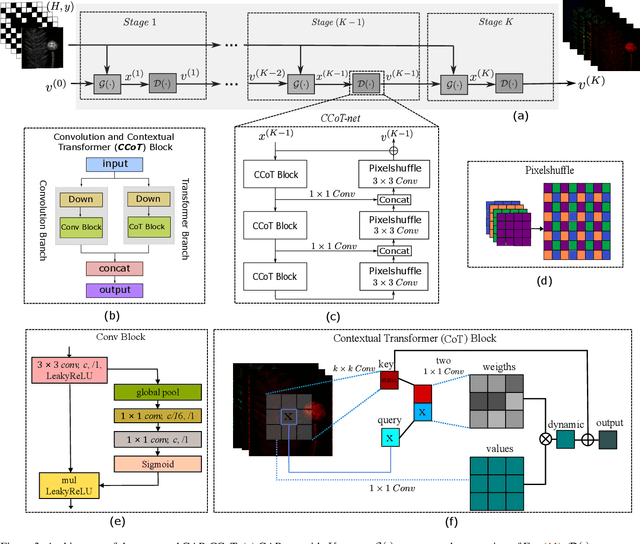
Spectral compressive imaging (SCI) is able to encode the high-dimensional hyperspectral image to a 2D measurement, and then uses algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and the state-of-the-art (SOTA) reconstruction methods generally face the problem of long reconstruction time and/or poor detail recovery. In this paper, we propose a novel hybrid network module, namely CSCoT (Convolution and Spectral Contextual Transformer) block, which can acquire the local perception of convolution and the global perception of transformer simultaneously, and is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CSCoT block into deep unfolding framework based on the generalized alternating projection algorithm, and further propose the GAP-CSCoT network. Finally, we apply the GAP-CSCoT algorithm to SCI reconstruction. Through the experiments of extensive synthetic and real data, our proposed model achieves higher reconstruction quality ($>$2dB in PSNR on simulated benchmark datasets) and shorter running time than existing SOTA algorithms by a large margin. The code and models will be released to the public.