 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Modeling on Limited Data with Regularization by Nontransferable Pre-trained Models
Paper and Code
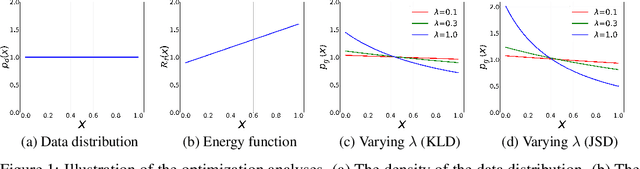
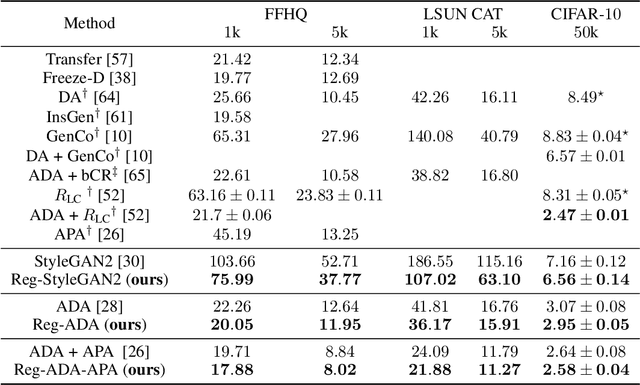
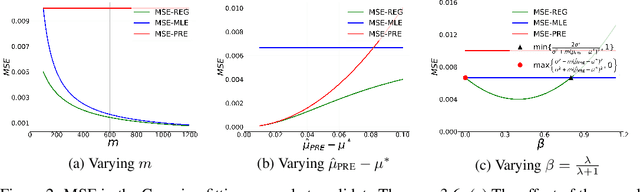

Deep generative models (DGMs) are data-eager. Essentially, it is because learning a complex model on limited data suffers from a large variance and easily overfits. Inspired by the \emph{bias-variance dilemma}, we propose \emph{regularized deep generative model} (Reg-DGM), which leverages a nontransferable pre-trained model to reduce the variance of generative modeling with limited data. Formally, Reg-DGM optimizes a weighted sum of a certain divergence between the data distribution and the DGM and the expectation of an energy function defined by the pre-trained model w.r.t. the DGM. Theoretically, we characterize the existence and uniqueness of the global minimum of Reg-DGM in the nonparametric setting and rigorously prove the statistical benefits of Reg-DGM w.r.t. the mean squared error and the expected risk in a simple yet representative Gaussian-fitting example. Empirically, it is quite flexible to specify the DGM and the pre-trained model in Reg-DGM. In particular, with a ResNet-18 classifier pre-trained on ImageNet and a data-dependent energy function, Reg-DGM consistently improves the generation performance of strong DGMs including StyleGAN2 and ADA on several benchmarks with limited data and achieves competitive results to the state-of-the-art methods.