 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARDoc: A Memory-Aware Refinement Agent Framework for Multimodal Long Document QA
Jun 04, 2026Iterative retrieval-reasoning agents have recently shown promise for multimodal long-document question answering. However, most existing systems maintain a single growing context that mixes retrieval traces, observations, and intermediate reasoning. As interactions accumulate, key evidence becomes scattered and diluted, making multi-hop reasoning noisy. We propose MARDoc, a Memory-Aware Refinement Agent framework that decouples long-document QA into three specialized agents: an Explorer for multi-granularity multimodal retrieval, a Refiner for distilling interaction traces into structured evidence and reasoning memories, and a Reflector for checking evidence sufficiency and providing targeted feedback. Across iterations, the agents rely on a dynamically updated structured memory rather than a full accumulated interaction history. This design reduces context noise while preserving answer-critical facts and their logical dependencies. Experiments on MMLongBench-Doc and DocBench show that MARDoc achieves strong results, outperforming same-backbone baselines and demonstrating the effectiveness of structured memory for agentic document QA.
Benchmark Leakage Trap: Can We Trust LLM-based Recommendation?
Feb 14, 2026The expanding integration of Large Language Models (LLMs) into recommender systems poses critical challenges to evaluation reliability. This paper identifies and investigates a previously overlooked issue: benchmark data leakage in LLM-based recommendation. This phenomenon occurs when LLMs are exposed to and potentially memorize benchmark datasets during pre-training or fine-tuning, leading to artificially inflated performance metrics that fail to reflect true model performance. To validate this phenomenon, we simulate diverse data leakage scenarios by conducting continued pre-training of foundation models on strategically blended corpora, which include user-item interactions from both in-domain and out-of-domain sources. Our experiments reveal a dual-effect of data leakage: when the leaked data is domain-relevant, it induces substantial but spurious performance gains, misleadingly exaggerating the model's capability. In contrast, domain-irrelevant leakage typically degrades recommendation accuracy, highlighting the complex and contingent nature of this contamination. Our findings reveal that data leakage acts as a critical, previously unaccounted-for factor in LLM-based recommendation, which could impact the true model performance. We release our code at https://github.com/yusba1/LLMRec-Data-Leakage.
ULMRec: User-centric Large Language Model for Sequential Recommendation
Dec 07, 2024Recent advances in Large Language Models (LLMs) have demonstrated promising performance in sequential recommendation tasks, leveraging their superior language understanding capabilities. However, existing LLM-based recommendation approaches predominantly focus on modeling item-level co-occurrence patterns while failing to adequately capture user-level personalized preferences. This is problematic since even users who display similar behavioral patterns (e.g., clicking or purchasing similar items) may have fundamentally different underlying interests. To alleviate this problem, in this paper, we propose ULMRec, a framework that effectively integrates user personalized preferences into LLMs for sequential recommendation. Considering there has the semantic gap between item IDs and LLMs, we replace item IDs with their corresponding titles in user historical behaviors, enabling the model to capture the item semantics. For integrating the user personalized preference, we design two key components: (1) user indexing: a personalized user indexing mechanism that leverages vector quantization on user reviews and user IDs to generate meaningful and unique user representations, and (2) alignment tuning: an alignment-based tuning stage that employs comprehensive preference alignment tasks to enhance the model's capability in capturing personalized information. Through this design, ULMRec achieves deep integration of language semantics with user personalized preferences, facilitating effective adaptation to recommendation. Extensive experiments on two public datasets demonstrate that ULMRec significantly outperforms existing methods, validating the effectiveness of our approach.
SRAP-Agent: Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent
Oct 18, 2024



Public scarce resource allocation plays a crucial role in economics as it directly influences the efficiency and equity in society. Traditional studies including theoretical model-based, empirical study-based and simulation-based methods encounter limitations due to the idealized assumption of complete information and individual rationality, as well as constraints posed by limited available data. In this work, we propose an innovative framework, SRAP-Agent (Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent), which integrates Large Language Models (LLMs) into economic simulations, aiming to bridge the gap between theoretical models and real-world dynamics. Using public housing allocation scenarios as a case study, we conduct extensive policy simulation experiments to verify the feasibility and effectiveness of the SRAP-Agent and employ the Policy Optimization Algorithm with certain optimization objectives. The source code can be found in https://github.com/jijiarui-cather/SRAPAgent_Framework
Advancing Large Language Model Attribution through Self-Improving
Oct 17, 2024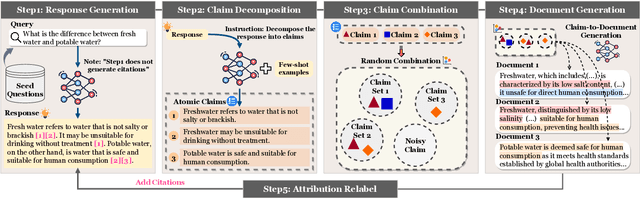
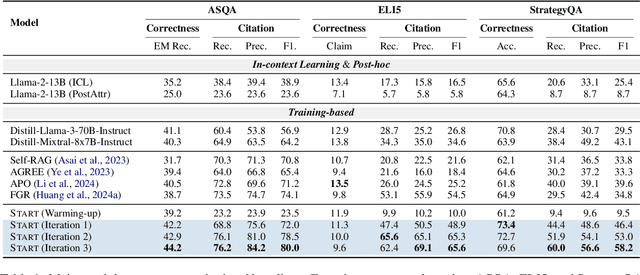
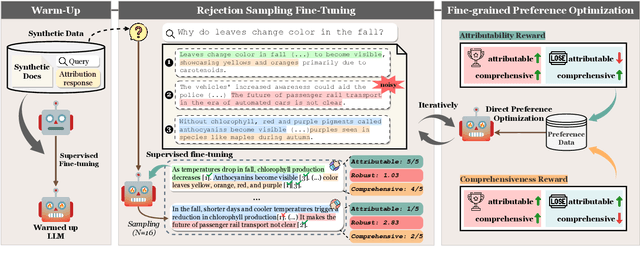
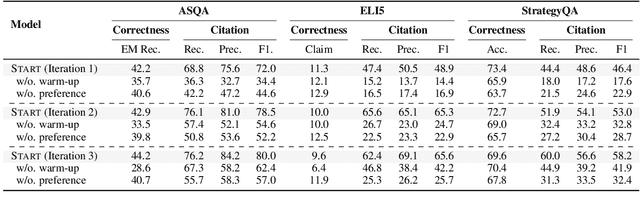
Teaching large language models (LLMs) to generate text with citations to evidence sources can mitigate hallucinations and enhance verifiability in information-seeking systems. However, improving this capability requires high-quality attribution data, which is costly and labor-intensive. Inspired by recent advances in self-improvement that enhance LLMs without manual annotation, we present START, a Self-Taught AttRibuTion framework for iteratively improving the attribution capability of LLMs. First, to prevent models from stagnating due to initially insufficient supervision signals, START leverages the model to self-construct synthetic training data for warming up. To further self-improve the model's attribution ability, START iteratively utilizes fine-grained preference supervision signals constructed from its sampled responses to encourage robust, comprehensive, and attributable generation. Experiments on three open-domain question-answering datasets, covering long-form QA and multi-step reasoning, demonstrate significant performance gains of 25.13% on average without relying on human annotations and more advanced models. Further analysis reveals that START excels in aggregating information across multiple sources.
GlobeSumm: A Challenging Benchmark Towards Unifying Multi-lingual, Cross-lingual and Multi-document News Summarization
Oct 05, 2024



News summarization in today's global scene can be daunting with its flood of multilingual content and varied viewpoints from different sources. However, current studies often neglect such real-world scenarios as they tend to focus solely on either single-language or single-document tasks. To bridge this gap, we aim to unify Multi-lingual, Cross-lingual and Multi-document Summarization into a novel task, i.e., MCMS, which encapsulates the real-world requirements all-in-one. Nevertheless, the lack of a benchmark inhibits researchers from adequately studying this invaluable problem. To tackle this, we have meticulously constructed the GLOBESUMM dataset by first collecting a wealth of multilingual news reports and restructuring them into event-centric format. Additionally, we introduce the method of protocol-guided prompting for high-quality and cost-effective reference annotation. In MCMS, we also highlight the challenge of conflicts between news reports, in addition to the issues of redundancies and omissions, further enhancing the complexity of GLOBESUMM. Through extensive experimental analysis, we validate the quality of our dataset and elucidate the inherent challenges of the task. We firmly believe that GLOBESUMM, given its challenging nature, will greatly contribute to the multilingual communities and the evaluation of LLMs.
Review-LLM: Harnessing Large Language Models for Personalized Review Generation
Jul 10, 2024
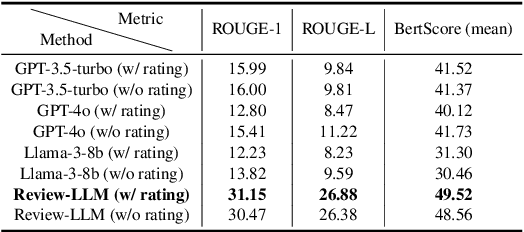
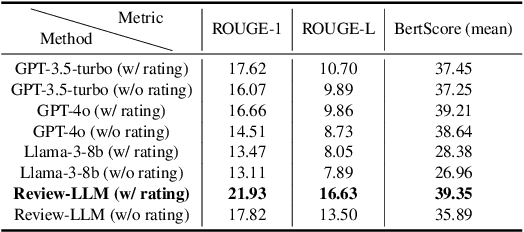
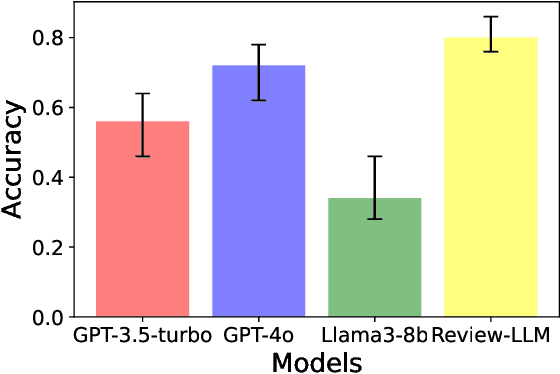
Product review generation is an important task in recommender systems, which could provide explanation and persuasiveness for the recommendation. Recently, Large Language Models (LLMs, e.g., ChatGPT) have shown superior text modeling and generating ability, which could be applied in review generation. However, directly applying the LLMs for generating reviews might be troubled by the ``polite'' phenomenon of the LLMs and could not generate personalized reviews (e.g., negative reviews). In this paper, we propose Review-LLM that customizes LLMs for personalized review generation. Firstly, we construct the prompt input by aggregating user historical behaviors, which include corresponding item titles and reviews. This enables the LLMs to capture user interest features and review writing style. Secondly, we incorporate ratings as indicators of satisfaction into the prompt, which could further improve the model's understanding of user preferences and the sentiment tendency control of generated reviews. Finally, we feed the prompt text into LLMs, and use Supervised Fine-Tuning (SFT) to make the model generate personalized reviews for the given user and target item. Experimental results on the real-world dataset show that our fine-tuned model could achieve better review generation performance than existing close-source LLMs.
Bucket Pre-training is All You Need
Jul 10, 2024


Large language models (LLMs) have demonstrated exceptional performance across various natural language processing tasks. However, the conventional fixed-length data composition strategy for pretraining, which involves concatenating and splitting documents, can introduce noise and limit the model's ability to capture long-range dependencies. To address this, we first introduce three metrics for evaluating data composition quality: padding ratio, truncation ratio, and concatenation ratio. We further propose a multi-bucket data composition method that moves beyond the fixed-length paradigm, offering a more flexible and efficient approach to pretraining. Extensive experiments demonstrate that our proposed method could significantly improving both the efficiency and efficacy of LLMs pretraining. Our approach not only reduces noise and preserves context but also accelerates training, making it a promising solution for LLMs pretraining.
Meaningful Learning: Advancing Abstract Reasoning in Large Language Models via Generic Fact Guidance
Mar 14, 2024



Large language models (LLMs) have developed impressive performance and strong explainability across various reasoning scenarios, marking a significant stride towards mimicking human-like intelligence. Despite this, when tasked with simple questions supported by a generic fact, LLMs often fail to provide consistent and precise answers, indicating a deficiency in abstract reasoning abilities. This has sparked a vigorous debate about whether LLMs are genuinely reasoning or merely memorizing. In light of this, we design a preliminary study to quantify and delve into the abstract reasoning abilities of existing LLMs. Our findings reveal a substantial discrepancy between their general reasoning and abstract reasoning performances. To relieve this problem, we tailor an abstract reasoning dataset (AbsR) together with a meaningful learning paradigm to teach LLMs how to leverage generic facts for reasoning purposes. The results show that our approach not only boosts the general reasoning performance of LLMs but also makes considerable strides towards their capacity for abstract reasoning, moving beyond simple memorization or imitation to a more nuanced understanding and application of generic facts.
PEPT: Expert Finding Meets Personalized Pre-training
Dec 19, 2023



Finding appropriate experts is essential in Community Question Answering (CQA) platforms as it enables the effective routing of questions to potential users who can provide relevant answers. The key is to personalized learning expert representations based on their historical answered questions, and accurately matching them with target questions. There have been some preliminary works exploring the usability of PLMs in expert finding, such as pre-training expert or question representations. However, these models usually learn pure text representations of experts from histories, disregarding personalized and fine-grained expert modeling. For alleviating this, we present a personalized pre-training and fine-tuning paradigm, which could effectively learn expert interest and expertise simultaneously. Specifically, in our pre-training framework, we integrate historical answered questions of one expert with one target question, and regard it as a candidate aware expert-level input unit. Then, we fuse expert IDs into the pre-training for guiding the model to model personalized expert representations, which can help capture the unique characteristics and expertise of each individual expert. Additionally, in our pre-training task, we design: 1) a question-level masked language model task to learn the relatedness between histories, enabling the modeling of question-level expert interest; 2) a vote-oriented task to capture question-level expert expertise by predicting the vote score the expert would receive. Through our pre-training framework and tasks, our approach could holistically learn expert representations including interests and expertise. Our method has been extensively evaluated on six real-world CQA datasets, and the experimental results consistently demonstrate the superiority of our approach over competitive baseline methods.