 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRAP-Agent: Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent
Oct 18, 2024



Public scarce resource allocation plays a crucial role in economics as it directly influences the efficiency and equity in society. Traditional studies including theoretical model-based, empirical study-based and simulation-based methods encounter limitations due to the idealized assumption of complete information and individual rationality, as well as constraints posed by limited available data. In this work, we propose an innovative framework, SRAP-Agent (Simulating and Optimizing Scarce Resource Allocation Policy with LLM-based Agent), which integrates Large Language Models (LLMs) into economic simulations, aiming to bridge the gap between theoretical models and real-world dynamics. Using public housing allocation scenarios as a case study, we conduct extensive policy simulation experiments to verify the feasibility and effectiveness of the SRAP-Agent and employ the Policy Optimization Algorithm with certain optimization objectives. The source code can be found in https://github.com/jijiarui-cather/SRAPAgent_Framework
LAMPER: LanguAge Model and Prompt EngineeRing for zero-shot time series classification
Mar 23, 2024



This study constructs the LanguAge Model with Prompt EngineeRing (LAMPER) framework, designed to systematically evaluate the adaptability of pre-trained language models (PLMs) in accommodating diverse prompts and their integration in zero-shot time series (TS) classification. We deploy LAMPER in experimental assessments using 128 univariate TS datasets sourced from the UCR archive. Our findings indicate that the feature representation capacity of LAMPER is influenced by the maximum input token threshold imposed by PLMs.
Cognitive resilience: Unraveling the proficiency of image-captioning models to interpret masked visual content
Mar 23, 2024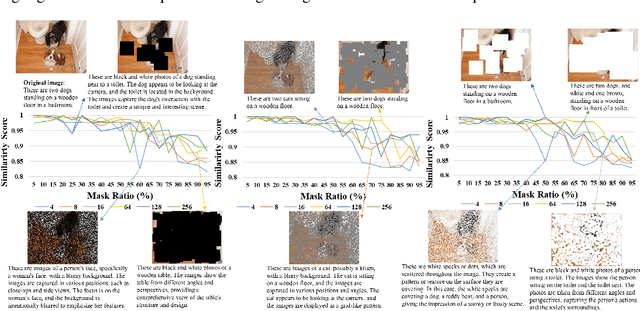
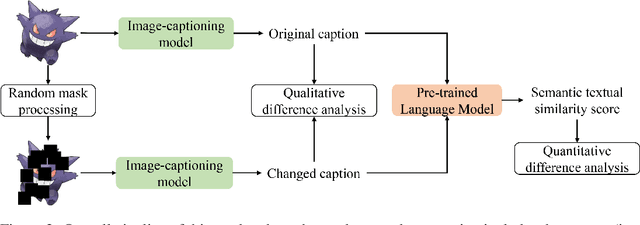

This study explores the ability of Image Captioning (IC) models to decode masked visual content sourced from diverse datasets. Our findings reveal the IC model's capability to generate captions from masked images, closely resembling the original content. Notably, even in the presence of masks, the model adeptly crafts descriptive textual information that goes beyond what is observable in the original image-generated captions. While the decoding performance of the IC model experiences a decline with an increase in the masked region's area, the model still performs well when important regions of the image are not masked at high coverage.
GAME: Generalized deep learning model towards multimodal data integration for early screening of adolescent mental disorders
Sep 18, 2023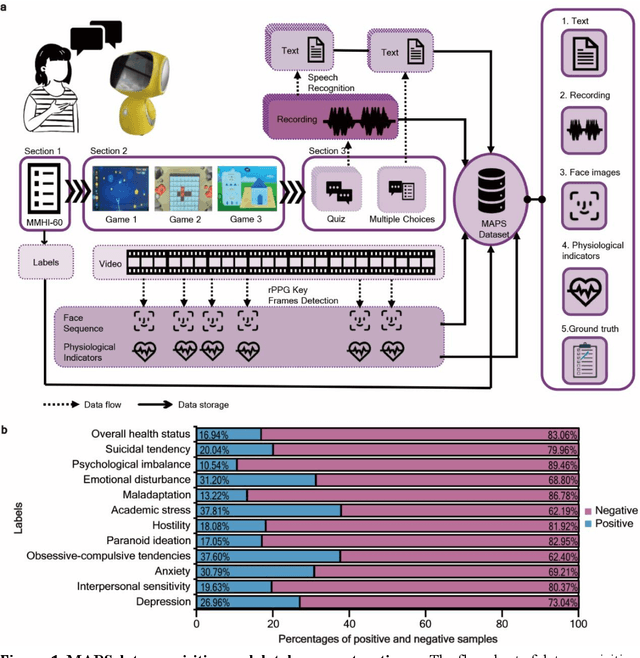


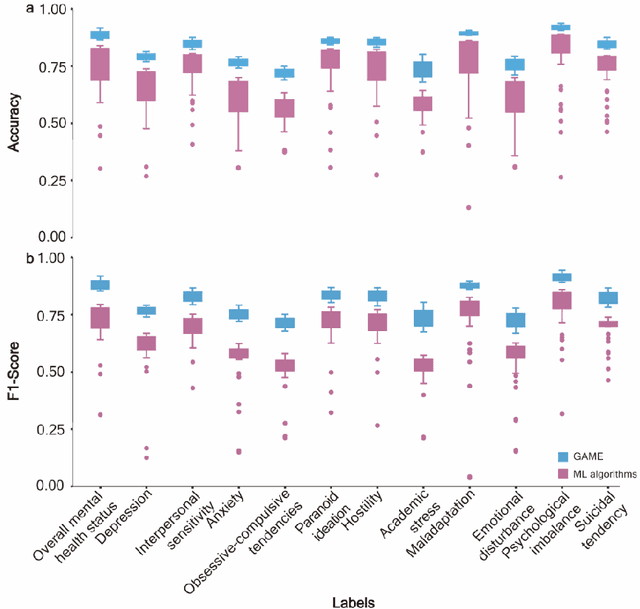
The timely identification of mental disorders in adolescents is a global public health challenge.Single factor is difficult to detect the abnormality due to its complex and subtle nature. Additionally, the generalized multimodal Computer-Aided Screening (CAS) systems with interactive robots for adolescent mental disorders are not available. Here, we design an android application with mini-games and chat recording deployed in a portable robot to screen 3,783 middle school students and construct the multimodal screening dataset, including facial images, physiological signs, voice recordings, and textual transcripts.We develop a model called GAME (Generalized Model with Attention and Multimodal EmbraceNet) with novel attention mechanism that integrates cross-modal features into the model. GAME evaluates adolescent mental conditions with high accuracy (73.34%-92.77%) and F1-Score (71.32%-91.06%).We find each modality contributes dynamically to the mental disorders screening and comorbidities among various mental disorders, indicating the feasibility of explainable model. This study provides a system capable of acquiring multimodal information and constructs a generalized multimodal integration algorithm with novel attention mechanisms for the early screening of adolescent mental disorders.
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023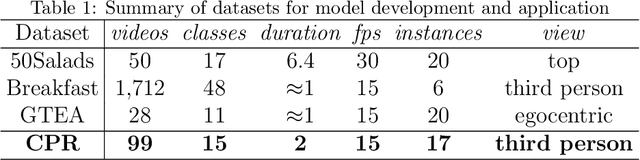
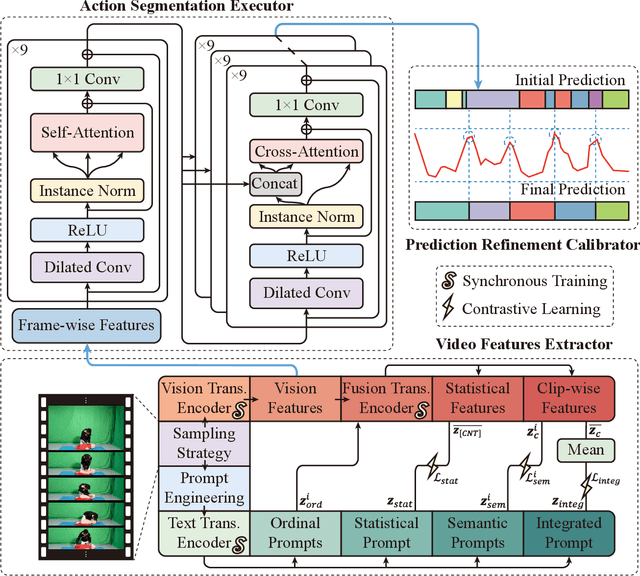
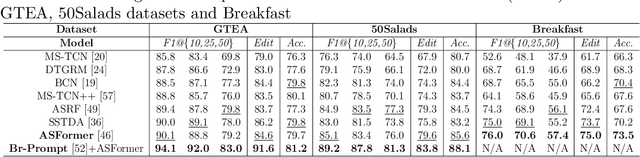

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.