 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructCore: Structure-Aware Image-Level Scoring for Training-Free Unsupervised Anomaly Detection
Feb 19, 2026Max pooling is the de facto standard for converting anomaly score maps into image-level decisions in memory-bank-based unsupervised anomaly detection (UAD). However, because it relies on a single extreme response, it discards most information about how anomaly evidence is distributed and structured across the image, often causing normal and anomalous scores to overlap. We propose StructCore, a training-free, structure-aware image-level scoring method that goes beyond max pooling. Given an anomaly score map, StructCore computes a low-dimensional structural descriptor phi(S) that captures distributional and spatial characteristics, and refines image-level scoring via a diagonal Mahalanobis calibration estimated from train-good samples, without modifying pixel-level localization. StructCore achieves image-level AUROC scores of 99.6% on MVTec AD and 98.4% on VisA, demonstrating robust image-level anomaly detection by exploiting structural signatures missed by max pooling.
Mapping the maturation of TCM as an adjuvant to radiotherapy
Jan 17, 2026The integration of complementary medicine into oncology represents a paradigm shift that has seen to increasing adoption of Traditional Chinese Medicine (TCM) as an adjuvant to radiotherapy. About twenty-five years since the formal institutionalization of integrated oncology, it is opportune to synthesize the trajectory of evidence for TCM as an adjuvant to radiotherapy. Here we conduct a large-scale analysis of 69,745 publications (2000 - 2025), emerging a cyclical evolution defined by coordinated expansion and contraction in publication output, international collaboration, and funding commitments that mirrors a define-ideate-test pattern. Using a theme modeling workflow designed to determine a stable thematic structure of the field, we identify five dominant thematic axes - cancer types, supportive care, clinical endpoints, mechanisms, and methodology - that signal a focus on patient well-being, scientific rigor and mechanistic exploration. Cross-theme integration of TCM is patient-centered and systems-oriented. Together with the emergent cycles of evolution, the thematic structure demonstrates progressive specialization and potential defragmentation of the field or saturation of existing research agenda. The analysis points to a field that has matured its current research agenda and is likely at the cusp of something new. Additionally, the field exhibits positive reporting of findings that is homogeneous across publication types, thematic areas, and the cycles of evolution suggesting a system-wide positive reporting bias agnostic to structural drivers.
GCR: Geometry-Consistent Routing for Task-Agnostic Continual Anomaly Detection
Jan 08, 2026Feature-based anomaly detection is widely adopted in industrial inspection due to the strong representational power of large pre-trained vision encoders. While most existing methods focus on improving within-category anomaly scoring, practical deployments increasingly require task-agnostic operation under continual category expansion, where the category identity is unknown at test time. In this setting, overall performance is often dominated by expert selection, namely routing an input to an appropriate normality model before any head-specific scoring is applied. However, routing rules that compare head-specific anomaly scores across independently constructed heads are unreliable in practice, as score distributions can differ substantially across categories in scale and tail behavior. We propose GCR, a lightweight mixture-of-experts framework for stabilizing task-agnostic continual anomaly detection through geometry-consistent routing. GCR routes each test image directly in a shared frozen patch-embedding space by minimizing an accumulated nearest-prototype distance to category-specific prototype banks, and then computes anomaly maps only within the routed expert using a standard prototype-based scoring rule. By separating cross-head decision making from within-head anomaly scoring, GCR avoids cross-head score comparability issues without requiring end-to-end representation learning. Experiments on MVTec AD and VisA show that geometry-consistent routing substantially improves routing stability and mitigates continual performance collapse, achieving near-zero forgetting while maintaining competitive detection and localization performance. These results indicate that many failures previously attributed to representation forgetting can instead be explained by decision-rule instability in cross-head routing. Code is available at https://github.com/jw-chae/GCR
On Text Simplification Metrics and General-Purpose LLMs for Accessible Health Information, and A Potential Architectural Advantage of The Instruction-Tuned LLM class
Nov 07, 2025


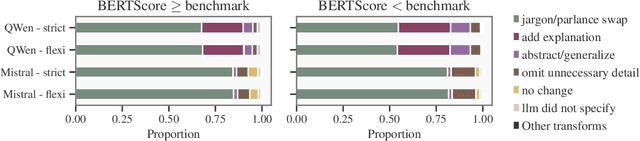
The increasing health-seeking behavior and digital consumption of biomedical information by the general public necessitate scalable solutions for automatically adapting complex scientific and technical documents into plain language. Automatic text simplification solutions, including advanced large language models, however, continue to face challenges in reliably arbitrating the tension between optimizing readability performance and ensuring preservation of discourse fidelity. This report empirically assesses the performance of two major classes of general-purpose LLMs, demonstrating their linguistic capabilities and foundational readiness for the task compared to a human benchmark. Using a comparative analysis of the instruction-tuned Mistral 24B and the reasoning-augmented QWen2.5 32B, we identify a potential architectural advantage in the instruction-tuned LLM. Mistral exhibits a tempered lexical simplification strategy that enhances readability across a suite of metrics and the simplification-specific formula SARI (mean 42.46), while preserving human-level discourse with a BERTScore of 0.91. QWen also attains enhanced readability performance, but its operational strategy shows a disconnect in balancing between readability and accuracy, reaching a statistically significantly lower BERTScore of 0.89. Additionally, a comprehensive correlation analysis of 21 metrics spanning readability, discourse fidelity, content safety, and underlying distributional measures for mechanistic insights, confirms strong functional redundancies among five readability indices. This empirical evidence tracks baseline performance of the evolving LLMs for the task of text simplification, identifies the instruction-tuned Mistral 24B for simplification, provides necessary heuristics for metric selection, and points to lexical support as a primary domain-adaptation issue for simplification.
Dual-Modality Computational Ophthalmic Imaging with Deep Learning and Coaxial Optical Design
Apr 13, 2025The growing burden of myopia and retinal diseases necessitates more accessible and efficient eye screening solutions. This study presents a compact, dual-function optical device that integrates fundus photography and refractive error detection into a unified platform. The system features a coaxial optical design using dichroic mirrors to separate wavelength-dependent imaging paths, enabling simultaneous alignment of fundus and refraction modules. A Dense-U-Net-based algorithm with customized loss functions is employed for accurate pupil segmentation, facilitating automated alignment and focusing. Experimental evaluations demonstrate the system's capability to achieve high-precision pupil localization (EDE = 2.8 px, mIoU = 0.931) and reliable refractive estimation with a mean absolute error below 5%. Despite limitations due to commercial lens components, the proposed framework offers a promising solution for rapid, intelligent, and scalable ophthalmic screening, particularly suitable for community health settings.
DBF-UNet: A Two-Stage Framework for Carotid Artery Segmentation with Pseudo-Label Generation
Apr 01, 2025



Medical image analysis faces significant challenges due to limited annotation data, particularly in three-dimensional carotid artery segmentation tasks, where existing datasets exhibit spatially discontinuous slice annotations with only a small portion of expert-labeled slices in complete 3D volumetric data. To address this challenge, we propose a two-stage segmentation framework. First, we construct continuous vessel centerlines by interpolating between annotated slice centroids and propagate labels along these centerlines to generate interpolated annotations for unlabeled slices. The slices with expert annotations are used for fine-tuning SAM-Med2D, while the interpolated labels on unlabeled slices serve as prompts to guide segmentation during inference. In the second stage, we propose a novel Dense Bidirectional Feature Fusion UNet (DBF-UNet). This lightweight architecture achieves precise segmentation of complete 3D vascular structures. The network incorporates bidirectional feature fusion in the encoder and integrates multi-scale feature aggregation with dense connectivity for effective feature reuse. Experimental validation on public datasets demonstrates that our proposed method effectively addresses the sparse annotation challenge in carotid artery segmentation while achieving superior performance compared to existing approaches. The source code is available at https://github.com/Haoxuanli-Thu/DBF-UNet.
HCMA-UNet: A Hybrid CNN-Mamba UNet with Inter-Slice Self-Attention for Efficient Breast Cancer Segmentation
Jan 01, 2025



Breast cancer lesion segmentation in DCE-MRI remains challenging due to heterogeneous tumor morphology and indistinct boundaries. To address these challenges, this study proposes a novel hybrid segmentation network, HCMA-UNet, for lesion segmentation of breast cancer. Our network consists of a lightweight CNN backbone and a Multi-view Inter-Slice Self-Attention Mamba (MISM) module. The MISM module integrates Visual State Space Block (VSSB) and Inter-Slice Self-Attention (ISSA) mechanism, effectively reducing parameters through Asymmetric Split Channel (ASC) strategy to achieve efficient tri-directional feature extraction. Our lightweight model achieves superior performance with 2.87M parameters and 126.44 GFLOPs. A Feature-guided Region-aware loss function (FRLoss) is proposed to enhance segmentation accuracy. Extensive experiments on one private and two public DCE-MRI breast cancer datasets demonstrate that our approach achieves state-of-the-art performance while maintaining computational efficiency. FRLoss also exhibits good cross-architecture generalization capabilities. The source code and dataset is available on this link.
SJTU:Spatial judgments in multimodal models towards unified segmentation through coordinate detection
Dec 03, 2024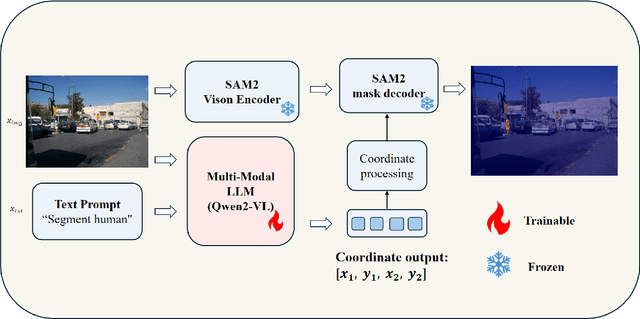
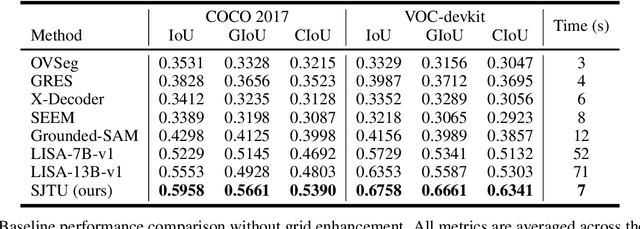
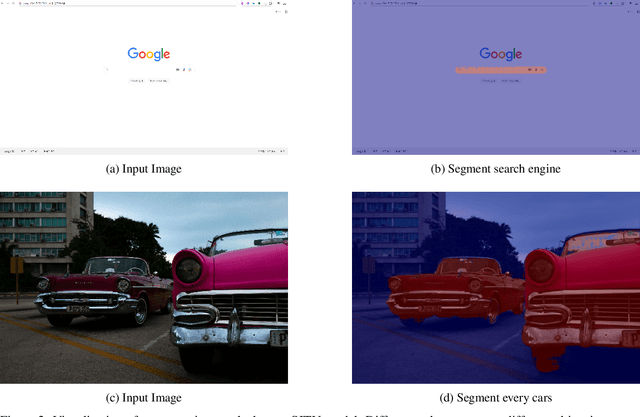
Despite advances in vision-language understanding, implementing image segmentation within multimodal architectures remains a fundamental challenge in modern artificial intelligence systems. Existing vision-language models, which primarily rely on backbone architectures or CLIP-based embedding learning, demonstrate inherent limitations in fine-grained spatial localization and operational capabilities. This paper introduces SJTU: Spatial Judgments in multimodal models - Towards Unified segmentation through coordinate detection, a novel framework that leverages spatial coordinate understanding to bridge vision-language interaction and precise segmentation, enabling accurate target identification through natural language instructions. The framework proposes a novel approach for integrating segmentation techniques with vision-language models based on multimodal spatial inference. By leveraging normalized coordinate detection for bounding boxes and translating it into actionable segmentation outputs, we explore the possibility of integrating multimodal spatial and language representations. Based on the proposed technical approach, the framework demonstrates superior performance on various benchmark datasets as well as accurate object segmentation. Results on the COCO 2017 dataset for general object detection and Pascal VOC datasets for semantic segmentation demonstrate the generalization capabilities of the framework.
Grid-augmented vision: A simple yet effective approach for enhanced spatial understanding in multi-modal agents
Dec 03, 2024
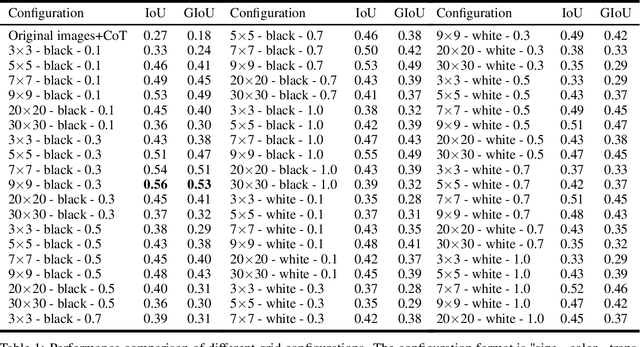

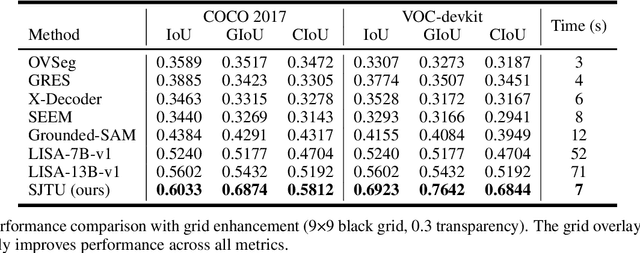
Recent advances in multimodal models have demonstrated impressive capabilities in object recognition and scene understanding. However, these models often struggle with precise spatial localization - a critical capability for real-world applications. Inspired by how humans use grid-based references like chess boards and maps, we propose introducing explicit visual position encoding through a simple grid overlay approach. By adding a 9x9 black grid pattern onto input images, our method provides visual spatial guidance analogous to how positional encoding works in transformers, but in an explicit, visual form. Experiments on the COCO 2017 dataset demonstrate that our grid-based approach achieves significant improvements in localization accuracy, with a 107.4% increase in IoU (from 0.27 to 0.56) and a 194.4% improvement in GIoU (from 0.18 to 0.53) compared to baseline performance. Through attention visualization analysis, we show how this visual position encoding helps models better ground spatial relationships. Our method's simplicity and effectiveness make it particularly valuable for applications requiring accurate spatial reasoning, such as robotic manipulation, medical imaging, and autonomous navigation.
COVID-19: post infection implications in different age groups, mechanism, diagnosis, effective prevention, treatment, and recommendations
Jun 02, 2024



SARS-CoV-2, the highly contagious pathogen responsible for the COVID-19 pandemic, has persistent effects that begin four weeks after initial infection and last for an undetermined duration. These chronic effects are more harmful than acute ones. This review explores the long-term impact of the virus on various human organs, including the pulmonary, cardiovascular, neurological, reproductive, gastrointestinal, musculoskeletal, endocrine, and lymphoid systems, particularly in older adults. Regarding diagnosis, RT-PCR is the gold standard for detecting COVID-19, though it requires specialized equipment, skilled personnel, and considerable time to produce results. To address these limitations, artificial intelligence in imaging and microfluidics technologies offers promising alternatives for diagnosing COVID-19 efficiently. Pharmacological and non-pharmacological strategies are effective in mitigating the persistent impacts of COVID-19. These strategies enhance immunity in post-COVID-19 patients by reducing cytokine release syndrome, improving T cell response, and increasing the circulation of activated natural killer and CD8 T cells in blood and tissues. This, in turn, alleviates symptoms such as fever, nausea, fatigue, muscle weakness, and pain. Vaccines, including inactivated viral, live attenuated viral, protein subunit, viral vectored, mRNA, DNA, and nanoparticle vaccines, significantly reduce the adverse long-term effects of the virus. However, no vaccine has been reported to provide lifetime protection against COVID-19. Consequently, protective measures such as physical distancing, mask usage, and hand hygiene remain essential strategies. This review offers a comprehensive understanding of the persistent effects of COVID-19 on individuals of varying ages, along with insights into diagnosis, treatment, vaccination, and future preventative measures against the spread of SARS-CoV-2.