 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructCore: Structure-Aware Image-Level Scoring for Training-Free Unsupervised Anomaly Detection
Feb 19, 2026Max pooling is the de facto standard for converting anomaly score maps into image-level decisions in memory-bank-based unsupervised anomaly detection (UAD). However, because it relies on a single extreme response, it discards most information about how anomaly evidence is distributed and structured across the image, often causing normal and anomalous scores to overlap. We propose StructCore, a training-free, structure-aware image-level scoring method that goes beyond max pooling. Given an anomaly score map, StructCore computes a low-dimensional structural descriptor phi(S) that captures distributional and spatial characteristics, and refines image-level scoring via a diagonal Mahalanobis calibration estimated from train-good samples, without modifying pixel-level localization. StructCore achieves image-level AUROC scores of 99.6% on MVTec AD and 98.4% on VisA, demonstrating robust image-level anomaly detection by exploiting structural signatures missed by max pooling.
GCR: Geometry-Consistent Routing for Task-Agnostic Continual Anomaly Detection
Jan 08, 2026Feature-based anomaly detection is widely adopted in industrial inspection due to the strong representational power of large pre-trained vision encoders. While most existing methods focus on improving within-category anomaly scoring, practical deployments increasingly require task-agnostic operation under continual category expansion, where the category identity is unknown at test time. In this setting, overall performance is often dominated by expert selection, namely routing an input to an appropriate normality model before any head-specific scoring is applied. However, routing rules that compare head-specific anomaly scores across independently constructed heads are unreliable in practice, as score distributions can differ substantially across categories in scale and tail behavior. We propose GCR, a lightweight mixture-of-experts framework for stabilizing task-agnostic continual anomaly detection through geometry-consistent routing. GCR routes each test image directly in a shared frozen patch-embedding space by minimizing an accumulated nearest-prototype distance to category-specific prototype banks, and then computes anomaly maps only within the routed expert using a standard prototype-based scoring rule. By separating cross-head decision making from within-head anomaly scoring, GCR avoids cross-head score comparability issues without requiring end-to-end representation learning. Experiments on MVTec AD and VisA show that geometry-consistent routing substantially improves routing stability and mitigates continual performance collapse, achieving near-zero forgetting while maintaining competitive detection and localization performance. These results indicate that many failures previously attributed to representation forgetting can instead be explained by decision-rule instability in cross-head routing. Code is available at https://github.com/jw-chae/GCR
SJTU:Spatial judgments in multimodal models towards unified segmentation through coordinate detection
Dec 03, 2024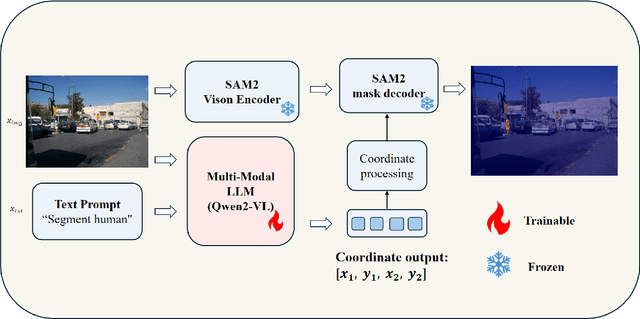
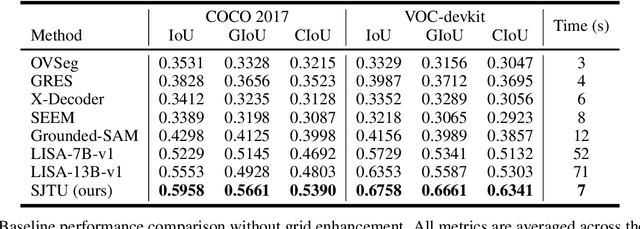
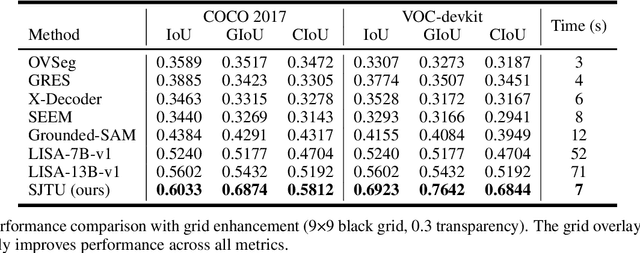
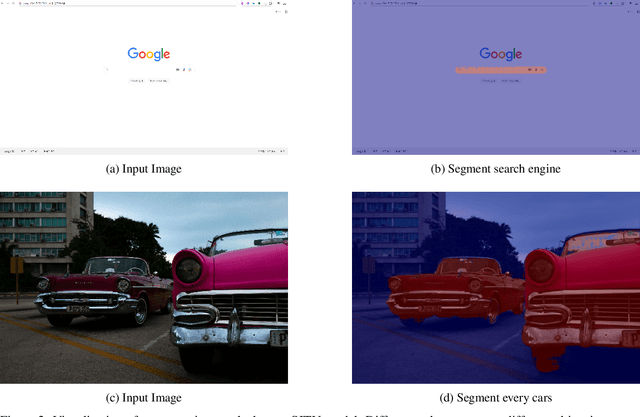
Despite advances in vision-language understanding, implementing image segmentation within multimodal architectures remains a fundamental challenge in modern artificial intelligence systems. Existing vision-language models, which primarily rely on backbone architectures or CLIP-based embedding learning, demonstrate inherent limitations in fine-grained spatial localization and operational capabilities. This paper introduces SJTU: Spatial Judgments in multimodal models - Towards Unified segmentation through coordinate detection, a novel framework that leverages spatial coordinate understanding to bridge vision-language interaction and precise segmentation, enabling accurate target identification through natural language instructions. The framework proposes a novel approach for integrating segmentation techniques with vision-language models based on multimodal spatial inference. By leveraging normalized coordinate detection for bounding boxes and translating it into actionable segmentation outputs, we explore the possibility of integrating multimodal spatial and language representations. Based on the proposed technical approach, the framework demonstrates superior performance on various benchmark datasets as well as accurate object segmentation. Results on the COCO 2017 dataset for general object detection and Pascal VOC datasets for semantic segmentation demonstrate the generalization capabilities of the framework.
Grid-augmented vision: A simple yet effective approach for enhanced spatial understanding in multi-modal agents
Dec 03, 2024
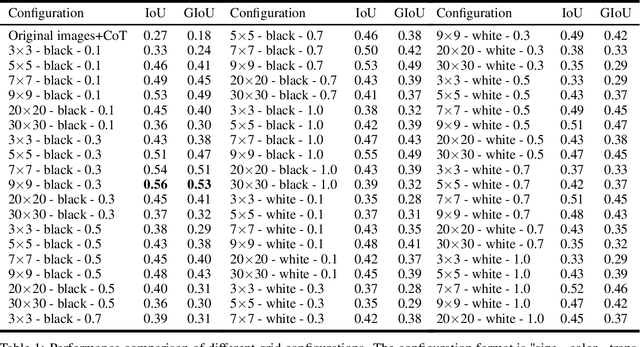

Recent advances in multimodal models have demonstrated impressive capabilities in object recognition and scene understanding. However, these models often struggle with precise spatial localization - a critical capability for real-world applications. Inspired by how humans use grid-based references like chess boards and maps, we propose introducing explicit visual position encoding through a simple grid overlay approach. By adding a 9x9 black grid pattern onto input images, our method provides visual spatial guidance analogous to how positional encoding works in transformers, but in an explicit, visual form. Experiments on the COCO 2017 dataset demonstrate that our grid-based approach achieves significant improvements in localization accuracy, with a 107.4% increase in IoU (from 0.27 to 0.56) and a 194.4% improvement in GIoU (from 0.18 to 0.53) compared to baseline performance. Through attention visualization analysis, we show how this visual position encoding helps models better ground spatial relationships. Our method's simplicity and effectiveness make it particularly valuable for applications requiring accurate spatial reasoning, such as robotic manipulation, medical imaging, and autonomous navigation.