 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the maturation of TCM as an adjuvant to radiotherapy
Jan 17, 2026The integration of complementary medicine into oncology represents a paradigm shift that has seen to increasing adoption of Traditional Chinese Medicine (TCM) as an adjuvant to radiotherapy. About twenty-five years since the formal institutionalization of integrated oncology, it is opportune to synthesize the trajectory of evidence for TCM as an adjuvant to radiotherapy. Here we conduct a large-scale analysis of 69,745 publications (2000 - 2025), emerging a cyclical evolution defined by coordinated expansion and contraction in publication output, international collaboration, and funding commitments that mirrors a define-ideate-test pattern. Using a theme modeling workflow designed to determine a stable thematic structure of the field, we identify five dominant thematic axes - cancer types, supportive care, clinical endpoints, mechanisms, and methodology - that signal a focus on patient well-being, scientific rigor and mechanistic exploration. Cross-theme integration of TCM is patient-centered and systems-oriented. Together with the emergent cycles of evolution, the thematic structure demonstrates progressive specialization and potential defragmentation of the field or saturation of existing research agenda. The analysis points to a field that has matured its current research agenda and is likely at the cusp of something new. Additionally, the field exhibits positive reporting of findings that is homogeneous across publication types, thematic areas, and the cycles of evolution suggesting a system-wide positive reporting bias agnostic to structural drivers.
Beyond Self-Talk: A Communication-Centric Survey of LLM-Based Multi-Agent Systems
Feb 20, 2025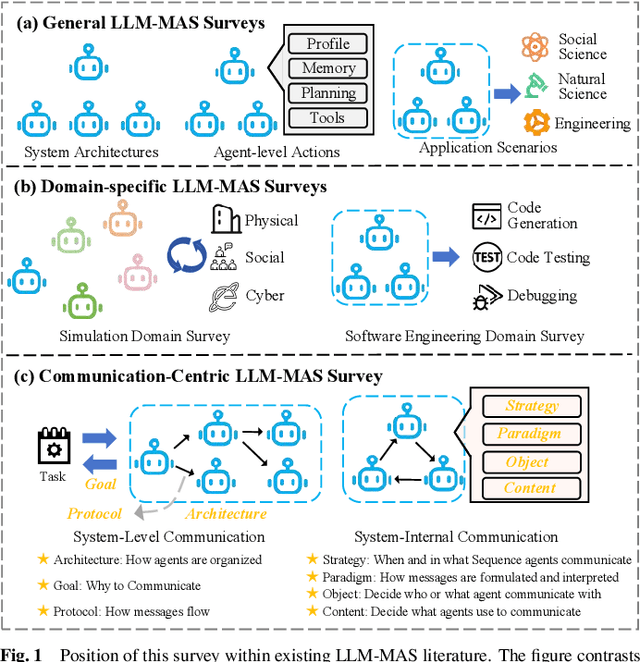
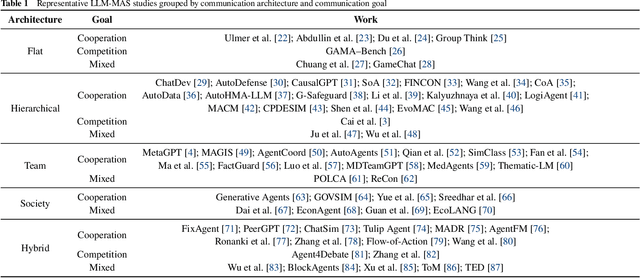
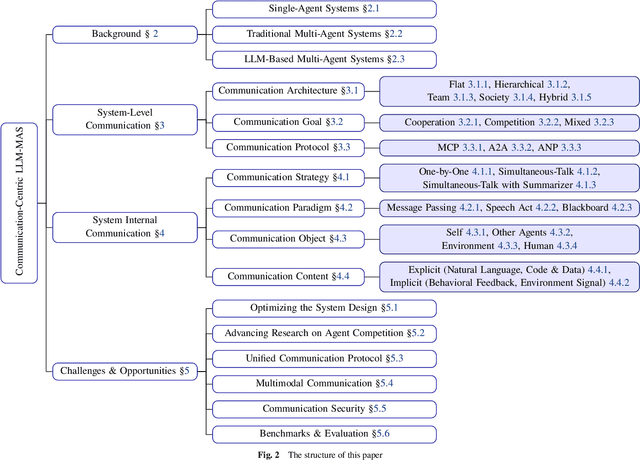
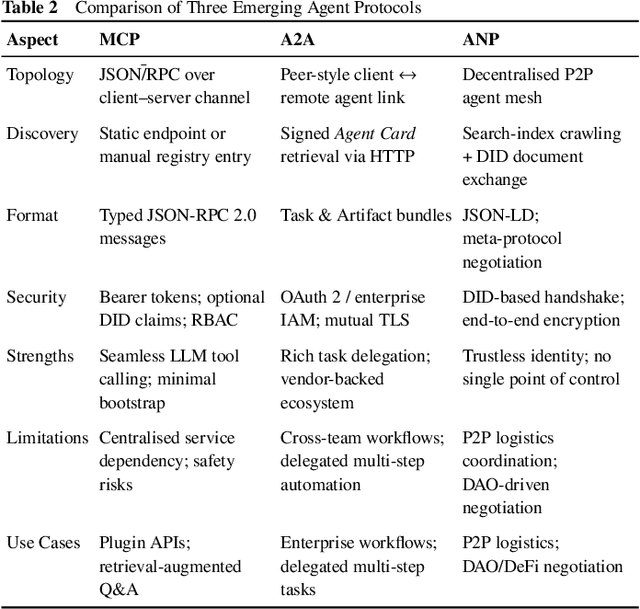
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in reasoning, planning, and decision-making. Building upon these strengths, researchers have begun incorporating LLMs into multi-agent systems (MAS), where agents collaborate or compete through natural language interactions to tackle tasks beyond the scope of single-agent setups. In this survey, we present a communication-centric perspective on LLM-based multi-agent systems, examining key system-level features such as architecture design and communication goals, as well as internal mechanisms like communication strategies, paradigms, objects and content. We illustrate how these communication elements interplay to enable collective intelligence and flexible collaboration. Furthermore, we discuss prominent challenges, including scalability, security, and multimodal integration, and propose directions for future work to advance research in this emerging domain. Ultimately, this survey serves as a catalyst for further innovation, fostering more robust, scalable, and intelligent multi-agent systems across diverse application domains.
Fine-Tuning Open-Source Large Language Models to Improve Their Performance on Radiation Oncology Tasks: A Feasibility Study to Investigate Their Potential Clinical Applications in Radiation Oncology
Jan 28, 2025



Background: The radiation oncology clinical practice involves many steps relying on the dynamic interplay of abundant text data. Large language models have displayed remarkable capabilities in processing complex text information. But their direct applications in specific fields like radiation oncology remain underexplored. Purpose: This study aims to investigate whether fine-tuning LLMs with domain knowledge can improve the performance on Task (1) treatment regimen generation, Task (2) treatment modality selection (photon, proton, electron, or brachytherapy), and Task (3) ICD-10 code prediction in radiation oncology. Methods: Data for 15,724 patient cases were extracted. Cases where patients had a single diagnostic record, and a clearly identifiable primary treatment plan were selected for preprocessing and manual annotation to have 7,903 cases of the patient diagnosis, treatment plan, treatment modality, and ICD-10 code. Each case was used to construct a pair consisting of patient diagnostics details and an answer (treatment regimen, treatment modality, or ICD-10 code respectively) for the supervised fine-tuning of these three tasks. Open source LLaMA2-7B and Mistral-7B models were utilized for the fine-tuning with the Low-Rank Approximations method. Accuracy and ROUGE-1 score were reported for the fine-tuned models and original models. Clinical evaluation was performed on Task (1) by radiation oncologists, while precision, recall, and F-1 score were evaluated for Task (2) and (3). One-sided Wilcoxon signed-rank tests were used to statistically analyze the results. Results: Fine-tuned LLMs outperformed original LLMs across all tasks with p-value <= 0.001. Clinical evaluation demonstrated that over 60% of the fine-tuned LLMs-generated treatment regimens were clinically acceptable. Precision, recall, and F1-score showed improved performance of fine-tuned LLMs.
Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion
Dec 16, 2024



This paper addresses the critical need for democratizing large language models (LLM) in the Arab world, a region that has seen slower progress in developing models comparable to state-of-the-art offerings like GPT-4 or ChatGPT 3.5, due to a predominant focus on mainstream languages (e.g., English and Chinese). One practical objective for an Arabic LLM is to utilize an Arabic-specific vocabulary for the tokenizer that could speed up decoding. However, using a different vocabulary often leads to a degradation of learned knowledge since many words are initially out-of-vocabulary (OOV) when training starts. Inspired by the vocabulary learning during Second Language (Arabic) Acquisition for humans, the released AraLLaMA employs progressive vocabulary expansion, which is implemented by a modified BPE algorithm that progressively extends the Arabic subwords in its dynamic vocabulary during training, thereby balancing the OOV ratio at every stage. The ablation study demonstrated the effectiveness of Progressive Vocabulary Expansion. Moreover, AraLLaMA achieves decent performance comparable to the best Arabic LLMs across a variety of Arabic benchmarks. Models, training data, benchmarks, and codes will be all open-sourced.
Alignment at Pre-training! Towards Native Alignment for Arabic LLMs
Dec 04, 2024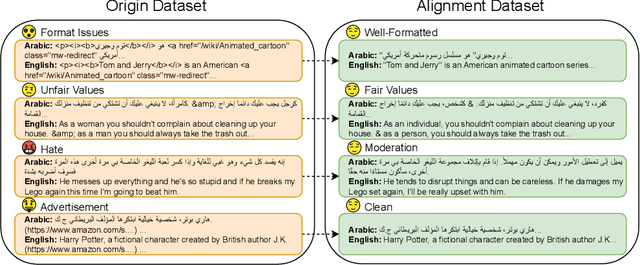
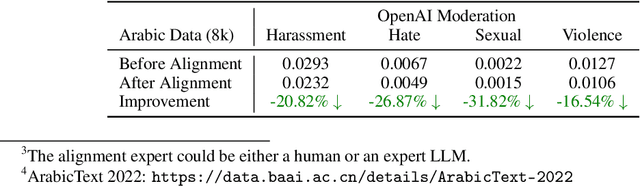
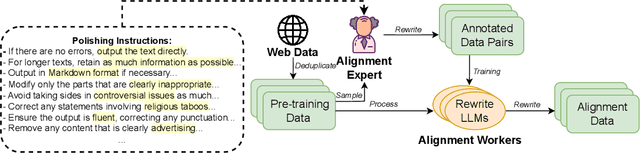
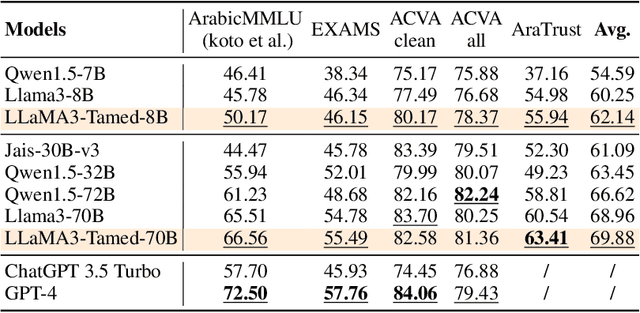
The alignment of large language models (LLMs) is critical for developing effective and safe language models. Traditional approaches focus on aligning models during the instruction tuning or reinforcement learning stages, referred to in this paper as `post alignment'. We argue that alignment during the pre-training phase, which we term `native alignment', warrants investigation. Native alignment aims to prevent unaligned content from the beginning, rather than relying on post-hoc processing. This approach leverages extensively aligned pre-training data to enhance the effectiveness and usability of pre-trained models. Our study specifically explores the application of native alignment in the context of Arabic LLMs. We conduct comprehensive experiments and ablation studies to evaluate the impact of native alignment on model performance and alignment stability. Additionally, we release open-source Arabic LLMs that demonstrate state-of-the-art performance on various benchmarks, providing significant benefits to the Arabic LLM community.
Grid-augmented vision: A simple yet effective approach for enhanced spatial understanding in multi-modal agents
Dec 03, 2024
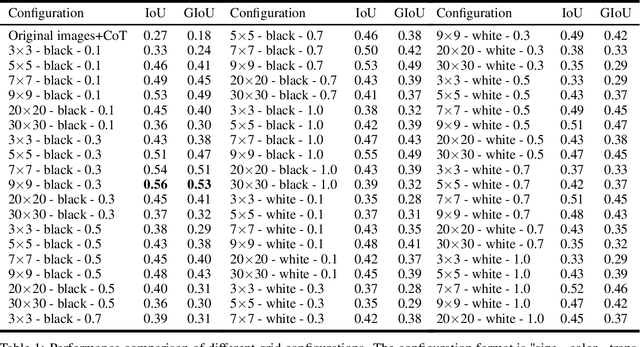

Recent advances in multimodal models have demonstrated impressive capabilities in object recognition and scene understanding. However, these models often struggle with precise spatial localization - a critical capability for real-world applications. Inspired by how humans use grid-based references like chess boards and maps, we propose introducing explicit visual position encoding through a simple grid overlay approach. By adding a 9x9 black grid pattern onto input images, our method provides visual spatial guidance analogous to how positional encoding works in transformers, but in an explicit, visual form. Experiments on the COCO 2017 dataset demonstrate that our grid-based approach achieves significant improvements in localization accuracy, with a 107.4% increase in IoU (from 0.27 to 0.56) and a 194.4% improvement in GIoU (from 0.18 to 0.53) compared to baseline performance. Through attention visualization analysis, we show how this visual position encoding helps models better ground spatial relationships. Our method's simplicity and effectiveness make it particularly valuable for applications requiring accurate spatial reasoning, such as robotic manipulation, medical imaging, and autonomous navigation.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024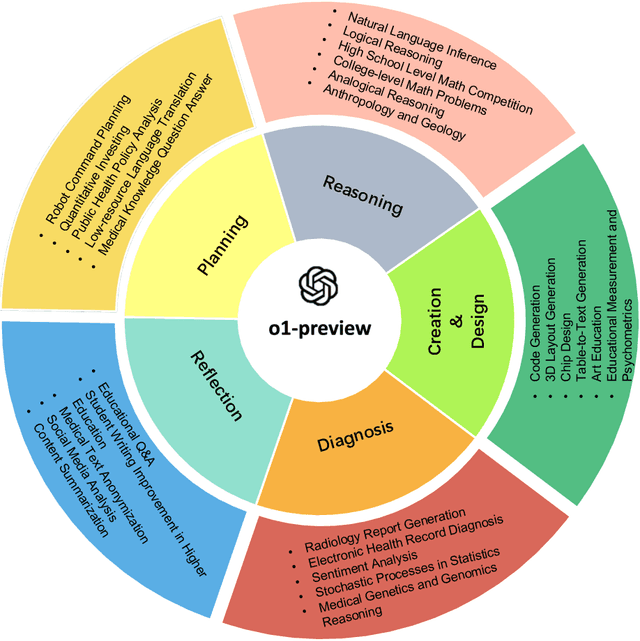


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
The Radiation Oncology NLP Database
Jan 19, 2024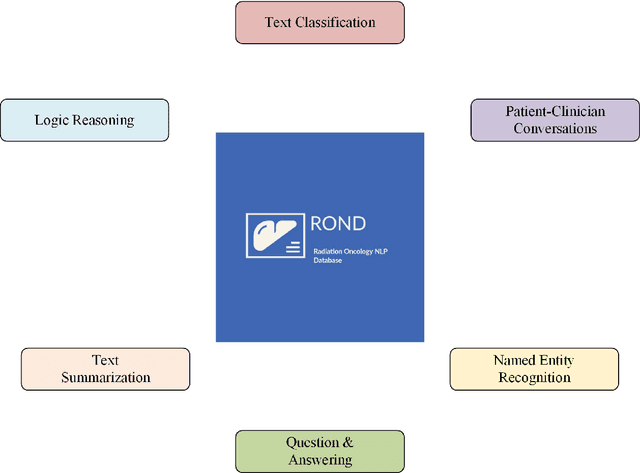


We present the Radiation Oncology NLP Database (ROND), the first dedicated Natural Language Processing (NLP) dataset for radiation oncology, an important medical specialty that has received limited attention from the NLP community in the past. With the advent of Artificial General Intelligence (AGI), there is an increasing need for specialized datasets and benchmarks to facilitate research and development. ROND is specifically designed to address this gap in the domain of radiation oncology, a field that offers many opportunities for NLP exploration. It encompasses various NLP tasks including Logic Reasoning, Text Classification, Named Entity Recognition (NER), Question Answering (QA), Text Summarization, and Patient-Clinician Conversations, each with a distinct focus on radiation oncology concepts and application cases. In addition, we have developed an instruction-tuning dataset consisting of over 20k instruction pairs (based on ROND) and trained a large language model, CancerChat. This serves to demonstrate the potential of instruction-tuning large language models within a highly-specialized medical domain. The evaluation results in this study could serve as baseline results for future research. ROND aims to stimulate advancements in radiation oncology and clinical NLP by offering a platform for testing and improving algorithms and models in a domain-specific context. The ROND dataset is a joint effort of multiple U.S. health institutions. The data is available at https://github.com/zl-liu/Radiation-Oncology-NLP-Database.
Noisy probing dose facilitated dose prediction for pencil beam scanning proton therapy: physics enhances generalizability
Dec 02, 2023



Purpose: Prior AI-based dose prediction studies in photon and proton therapy often neglect underlying physics, limiting their generalizability to handle outlier clinical cases, especially for pencil beam scanning proton therapy (PBSPT). Our aim is to design a physics-aware and generalizable AI-based PBSPT dose prediction method that has the underlying physics considered to achieve high generalizability to properly handle the outlier clinical cases. Methods and Materials: This study analyzed PBSPT plans of 103 prostate and 78 lung cancer patients from our institution,with each case comprising CT images, structure sets, and plan doses from our Monte-Carlo dose engine (serving as the ground truth). Three methods were evaluated in the ablation study: the ROI-based method, the beam mask and sliding window method, and the noisy probing dose method. Twelve cases with uncommon beam angles or prescription doses tested the methods' generalizability to rare treatment planning scenarios. Performance evaluation used DVH indices, 3D Gamma passing rates (3%/2mm/10%), and dice coefficients for dose agreement. Results: The noisy probing dose method showed improved agreement of DVH indices, 3D Gamma passing rates, and dice coefficients compared to the conventional methods for the testing cases. The noisy probing dose method showed better generalizability in the 6 outlier cases than the ROI-based and beam mask-based methods with 3D Gamma passing rates (for prostate cancer, targets: 89.32%$\pm$1.45% vs. 93.48%$\pm$1.51% vs. 96.79%$\pm$0.83%, OARs: 85.87%$\pm$1.73% vs. 91.15%$\pm$1.13% vs. 94.29%$\pm$1.01%). The dose predictions were completed within 0.3 seconds. Conclusions: We've devised a novel noisy probing dose method for PBSPT dose prediction in prostate and lung cancer patients. With more physics included, it enhances the generalizability of dose prediction in handling outlier clinical cases.
Benchmarking a foundation LLM on its ability to re-label structure names in accordance with the AAPM TG-263 report
Oct 05, 2023



Purpose: To introduce the concept of using large language models (LLMs) to re-label structure names in accordance with the American Association of Physicists in Medicine (AAPM) Task Group (TG)-263 standard, and to establish a benchmark for future studies to reference. Methods and Materials: The Generative Pre-trained Transformer (GPT)-4 application programming interface (API) was implemented as a Digital Imaging and Communications in Medicine (DICOM) storage server, which upon receiving a structure set DICOM file, prompts GPT-4 to re-label the structure names of both target volumes and normal tissues according to the AAPM TG-263. Three disease sites, prostate, head and neck, and thorax were selected for evaluation. For each disease site category, 150 patients were randomly selected for manually tuning the instructions prompt (in batches of 50) and 50 patients were randomly selected for evaluation. Structure names that were considered were those that were most likely to be relevant for studies utilizing structure contours for many patients. Results: The overall re-labeling accuracy of both target volumes and normal tissues for prostate, head and neck, and thorax cases was 96.0%, 98.5%, and 96.9% respectively. Re-labeling of target volumes was less accurate on average except for prostate - 100%, 93.1%, and 91.1% respectively. Conclusions: Given the accuracy of GPT-4 in re-labeling structure names of both target volumes and normal tissues as presented in this work, LLMs are poised to be the preferred method for standardizing structure names in radiation oncology, especially considering the rapid advancements in LLM capabilities that are likely to continue.