 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructCore: Structure-Aware Image-Level Scoring for Training-Free Unsupervised Anomaly Detection
Feb 19, 2026Max pooling is the de facto standard for converting anomaly score maps into image-level decisions in memory-bank-based unsupervised anomaly detection (UAD). However, because it relies on a single extreme response, it discards most information about how anomaly evidence is distributed and structured across the image, often causing normal and anomalous scores to overlap. We propose StructCore, a training-free, structure-aware image-level scoring method that goes beyond max pooling. Given an anomaly score map, StructCore computes a low-dimensional structural descriptor phi(S) that captures distributional and spatial characteristics, and refines image-level scoring via a diagonal Mahalanobis calibration estimated from train-good samples, without modifying pixel-level localization. StructCore achieves image-level AUROC scores of 99.6% on MVTec AD and 98.4% on VisA, demonstrating robust image-level anomaly detection by exploiting structural signatures missed by max pooling.
Mapping the maturation of TCM as an adjuvant to radiotherapy
Jan 17, 2026The integration of complementary medicine into oncology represents a paradigm shift that has seen to increasing adoption of Traditional Chinese Medicine (TCM) as an adjuvant to radiotherapy. About twenty-five years since the formal institutionalization of integrated oncology, it is opportune to synthesize the trajectory of evidence for TCM as an adjuvant to radiotherapy. Here we conduct a large-scale analysis of 69,745 publications (2000 - 2025), emerging a cyclical evolution defined by coordinated expansion and contraction in publication output, international collaboration, and funding commitments that mirrors a define-ideate-test pattern. Using a theme modeling workflow designed to determine a stable thematic structure of the field, we identify five dominant thematic axes - cancer types, supportive care, clinical endpoints, mechanisms, and methodology - that signal a focus on patient well-being, scientific rigor and mechanistic exploration. Cross-theme integration of TCM is patient-centered and systems-oriented. Together with the emergent cycles of evolution, the thematic structure demonstrates progressive specialization and potential defragmentation of the field or saturation of existing research agenda. The analysis points to a field that has matured its current research agenda and is likely at the cusp of something new. Additionally, the field exhibits positive reporting of findings that is homogeneous across publication types, thematic areas, and the cycles of evolution suggesting a system-wide positive reporting bias agnostic to structural drivers.
GCR: Geometry-Consistent Routing for Task-Agnostic Continual Anomaly Detection
Jan 08, 2026Feature-based anomaly detection is widely adopted in industrial inspection due to the strong representational power of large pre-trained vision encoders. While most existing methods focus on improving within-category anomaly scoring, practical deployments increasingly require task-agnostic operation under continual category expansion, where the category identity is unknown at test time. In this setting, overall performance is often dominated by expert selection, namely routing an input to an appropriate normality model before any head-specific scoring is applied. However, routing rules that compare head-specific anomaly scores across independently constructed heads are unreliable in practice, as score distributions can differ substantially across categories in scale and tail behavior. We propose GCR, a lightweight mixture-of-experts framework for stabilizing task-agnostic continual anomaly detection through geometry-consistent routing. GCR routes each test image directly in a shared frozen patch-embedding space by minimizing an accumulated nearest-prototype distance to category-specific prototype banks, and then computes anomaly maps only within the routed expert using a standard prototype-based scoring rule. By separating cross-head decision making from within-head anomaly scoring, GCR avoids cross-head score comparability issues without requiring end-to-end representation learning. Experiments on MVTec AD and VisA show that geometry-consistent routing substantially improves routing stability and mitigates continual performance collapse, achieving near-zero forgetting while maintaining competitive detection and localization performance. These results indicate that many failures previously attributed to representation forgetting can instead be explained by decision-rule instability in cross-head routing. Code is available at https://github.com/jw-chae/GCR
Grid-augmented vision: A simple yet effective approach for enhanced spatial understanding in multi-modal agents
Dec 03, 2024
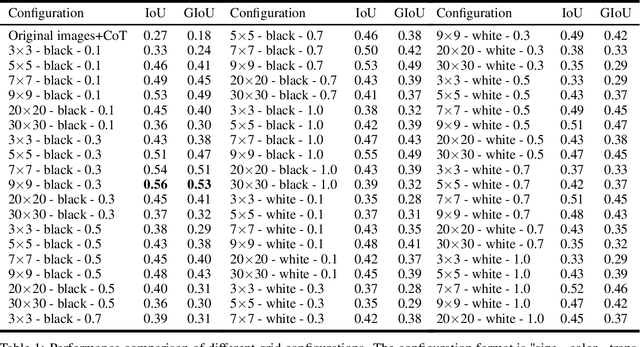

Recent advances in multimodal models have demonstrated impressive capabilities in object recognition and scene understanding. However, these models often struggle with precise spatial localization - a critical capability for real-world applications. Inspired by how humans use grid-based references like chess boards and maps, we propose introducing explicit visual position encoding through a simple grid overlay approach. By adding a 9x9 black grid pattern onto input images, our method provides visual spatial guidance analogous to how positional encoding works in transformers, but in an explicit, visual form. Experiments on the COCO 2017 dataset demonstrate that our grid-based approach achieves significant improvements in localization accuracy, with a 107.4% increase in IoU (from 0.27 to 0.56) and a 194.4% improvement in GIoU (from 0.18 to 0.53) compared to baseline performance. Through attention visualization analysis, we show how this visual position encoding helps models better ground spatial relationships. Our method's simplicity and effectiveness make it particularly valuable for applications requiring accurate spatial reasoning, such as robotic manipulation, medical imaging, and autonomous navigation.
COVID-19: post infection implications in different age groups, mechanism, diagnosis, effective prevention, treatment, and recommendations
Jun 02, 2024



SARS-CoV-2, the highly contagious pathogen responsible for the COVID-19 pandemic, has persistent effects that begin four weeks after initial infection and last for an undetermined duration. These chronic effects are more harmful than acute ones. This review explores the long-term impact of the virus on various human organs, including the pulmonary, cardiovascular, neurological, reproductive, gastrointestinal, musculoskeletal, endocrine, and lymphoid systems, particularly in older adults. Regarding diagnosis, RT-PCR is the gold standard for detecting COVID-19, though it requires specialized equipment, skilled personnel, and considerable time to produce results. To address these limitations, artificial intelligence in imaging and microfluidics technologies offers promising alternatives for diagnosing COVID-19 efficiently. Pharmacological and non-pharmacological strategies are effective in mitigating the persistent impacts of COVID-19. These strategies enhance immunity in post-COVID-19 patients by reducing cytokine release syndrome, improving T cell response, and increasing the circulation of activated natural killer and CD8 T cells in blood and tissues. This, in turn, alleviates symptoms such as fever, nausea, fatigue, muscle weakness, and pain. Vaccines, including inactivated viral, live attenuated viral, protein subunit, viral vectored, mRNA, DNA, and nanoparticle vaccines, significantly reduce the adverse long-term effects of the virus. However, no vaccine has been reported to provide lifetime protection against COVID-19. Consequently, protective measures such as physical distancing, mask usage, and hand hygiene remain essential strategies. This review offers a comprehensive understanding of the persistent effects of COVID-19 on individuals of varying ages, along with insights into diagnosis, treatment, vaccination, and future preventative measures against the spread of SARS-CoV-2.
Benchmarking the Cell Image Segmentation Models Robustness under the Microscope Optical Aberrations
Apr 12, 2024Cell segmentation is essential in biomedical research for analyzing cellular morphology and behavior. Deep learning methods, particularly convolutional neural networks (CNNs), have revolutionized cell segmentation by extracting intricate features from images. However, the robustness of these methods under microscope optical aberrations remains a critical challenge. This study comprehensively evaluates the performance of cell instance segmentation models under simulated aberration conditions using the DynamicNuclearNet (DNN) and LIVECell datasets. Aberrations, including Astigmatism, Coma, Spherical, and Trefoil, were simulated using Zernike polynomial equations. Various segmentation models, such as Mask R-CNN with different network heads (FPN, C3) and backbones (ResNet, VGG19, SwinS), were trained and tested under aberrated conditions. Results indicate that FPN combined with SwinS demonstrates superior robustness in handling simple cell images affected by minor aberrations. Conversely, Cellpose2.0 proves effective for complex cell images under similar conditions. Our findings provide insights into selecting appropriate segmentation models based on cell morphology and aberration severity, enhancing the reliability of cell segmentation in biomedical applications. Further research is warranted to validate these methods with diverse aberration types and emerging segmentation models. Overall, this research aims to guide researchers in effectively utilizing cell segmentation models in the presence of minor optical aberrations.
The neural network models with delays for solving absolute value equations
Oct 17, 2023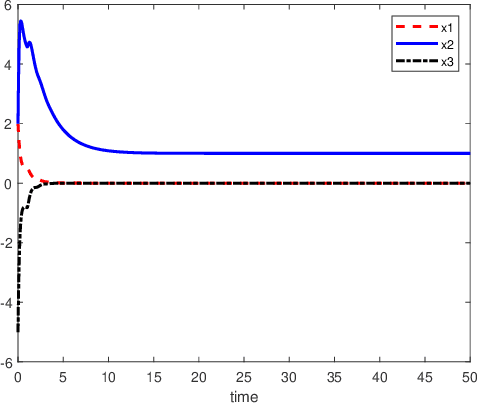
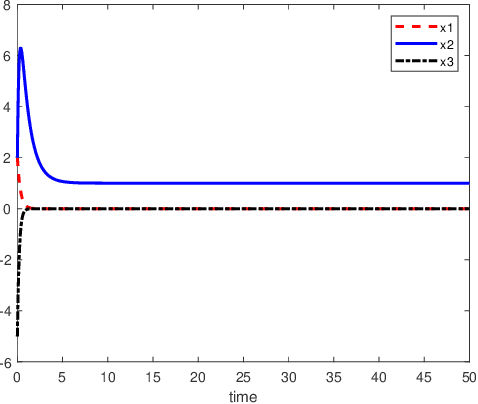
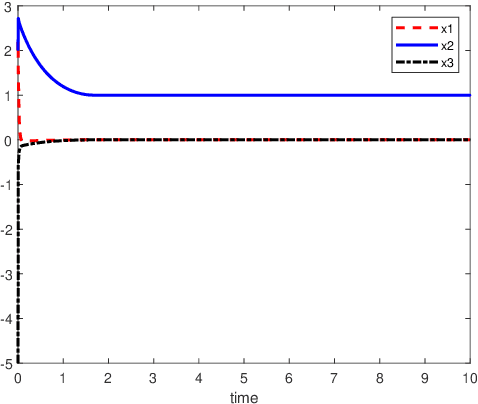
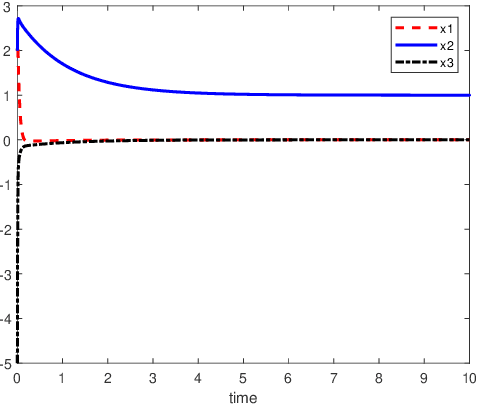
An inverse-free neural network model with mixed delays is proposed for solving the absolute value equation (AVE) $Ax -|x| - b =0$, which includes an inverse-free neural network model with discrete delay as a special case. By using the Lyapunov-Krasovskii theory and the linear matrix inequality (LMI) method, the developed neural network models are proved to be exponentially convergent to the solution of the AVE. Compared with the existing neural network models for solving the AVE, the proposed models feature the ability of solving a class of AVE with $\|A^{-1}\|>1$. Numerical simulations are given to show the effectiveness of the two delayed neural network models.
Ammonia-Net: A Multi-task Joint Learning Model for Multi-class Segmentation and Classification in Tooth-marked Tongue Diagnosis
Oct 05, 2023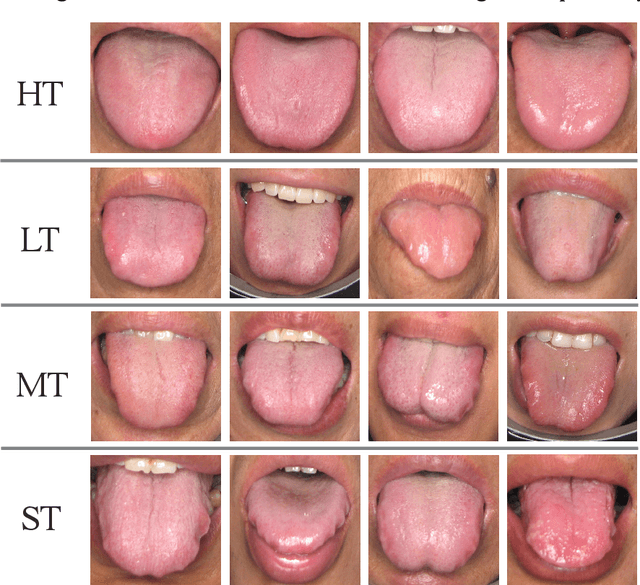

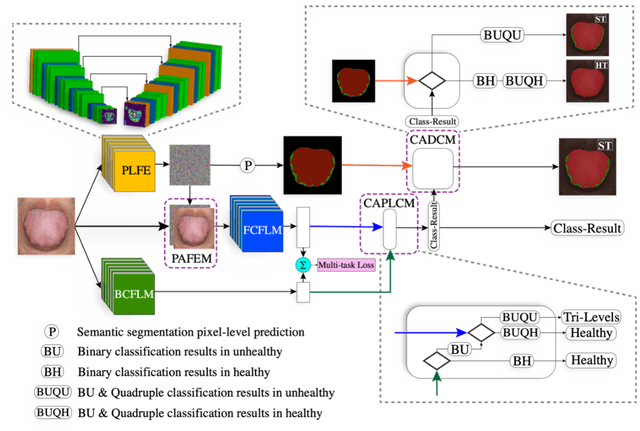
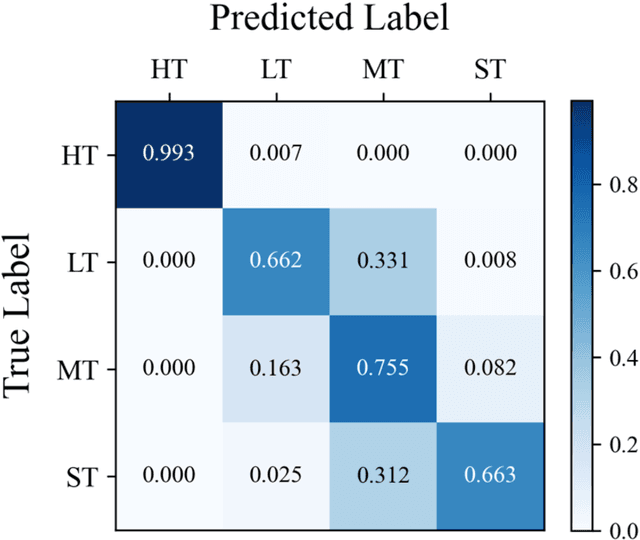
In Traditional Chinese Medicine, the tooth marks on the tongue, stemming from prolonged dental pressure, serve as a crucial indicator for assessing qi (yang) deficiency, which is intrinsically linked to visceral health. Manual diagnosis of tooth-marked tongue solely relies on experience. Nonetheless, the diversity in shape, color, and type of tooth marks poses a challenge to diagnostic accuracy and consistency. To address these problems, herein we propose a multi-task joint learning model named Ammonia-Net. This model employs a convolutional neural network-based architecture, specifically designed for multi-class segmentation and classification of tongue images. Ammonia-Net performs semantic segmentation of tongue images to identify tongue and tooth marks. With the assistance of segmentation output, it classifies the images into the desired number of classes: healthy tongue, light tongue, moderate tongue, and severe tongue. As far as we know, this is the first attempt to apply the semantic segmentation results of tooth marks for tooth-marked tongue classification. To train Ammonia-Net, we collect 856 tongue images from 856 subjects. After a number of extensive experiments, the experimental results show that the proposed model achieves 99.06% accuracy in the two-class classification task of tooth-marked tongue identification and 80.02%. As for the segmentation task, mIoU for tongue and tooth marks amounts to 71.65%.
GAME: Generalized deep learning model towards multimodal data integration for early screening of adolescent mental disorders
Sep 18, 2023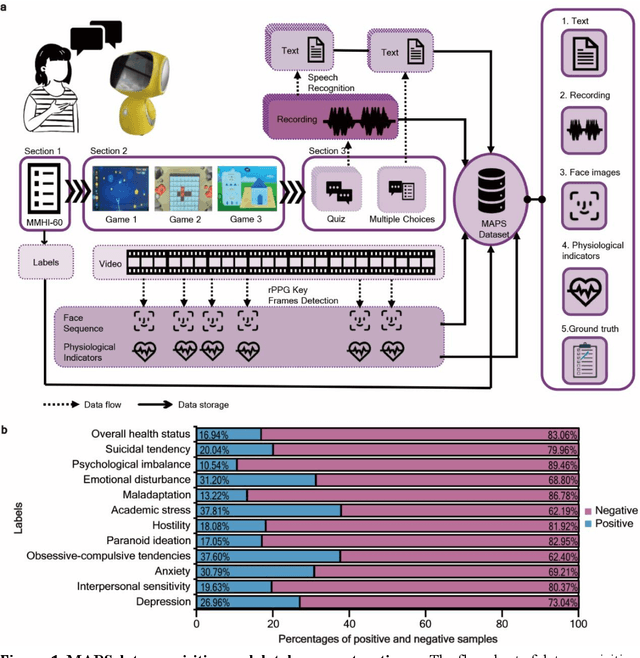


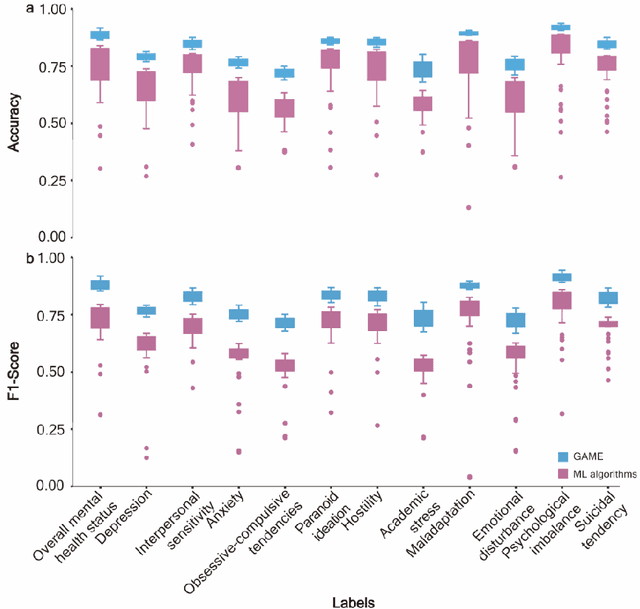
The timely identification of mental disorders in adolescents is a global public health challenge.Single factor is difficult to detect the abnormality due to its complex and subtle nature. Additionally, the generalized multimodal Computer-Aided Screening (CAS) systems with interactive robots for adolescent mental disorders are not available. Here, we design an android application with mini-games and chat recording deployed in a portable robot to screen 3,783 middle school students and construct the multimodal screening dataset, including facial images, physiological signs, voice recordings, and textual transcripts.We develop a model called GAME (Generalized Model with Attention and Multimodal EmbraceNet) with novel attention mechanism that integrates cross-modal features into the model. GAME evaluates adolescent mental conditions with high accuracy (73.34%-92.77%) and F1-Score (71.32%-91.06%).We find each modality contributes dynamically to the mental disorders screening and comorbidities among various mental disorders, indicating the feasibility of explainable model. This study provides a system capable of acquiring multimodal information and constructs a generalized multimodal integration algorithm with novel attention mechanisms for the early screening of adolescent mental disorders.
Object Detection for Caries or Pit and Fissure Sealing Requirement in Children's First Permanent Molars
Aug 31, 2023Dental caries is one of the most common oral diseases that, if left untreated, can lead to a variety of oral problems. It mainly occurs inside the pits and fissures on the occlusal/buccal/palatal surfaces of molars and children are a high-risk group for pit and fissure caries in permanent molars. Pit and fissure sealing is one of the most effective methods that is widely used in prevention of pit and fissure caries. However, current detection of pits and fissures or caries depends primarily on the experienced dentists, which ordinary parents do not have, and children may miss the remedial treatment without timely detection. To address this issue, we present a method to autodetect caries and pit and fissure sealing requirements using oral photos taken by smartphones. We use the YOLOv5 and YOLOX models and adopt a tiling strategy to reduce information loss during image pre-processing. The best result for YOLOXs model with tiling strategy is 72.3 mAP.5, while the best result without tiling strategy is 71.2. YOLOv5s6 model with/without tiling attains 70.9/67.9 mAP.5, respectively. We deploy the pre-trained network to mobile devices as a WeChat applet, allowing in-home detection by parents or children guardian.