 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection for Caries or Pit and Fissure Sealing Requirement in Children's First Permanent Molars
Aug 31, 2023Dental caries is one of the most common oral diseases that, if left untreated, can lead to a variety of oral problems. It mainly occurs inside the pits and fissures on the occlusal/buccal/palatal surfaces of molars and children are a high-risk group for pit and fissure caries in permanent molars. Pit and fissure sealing is one of the most effective methods that is widely used in prevention of pit and fissure caries. However, current detection of pits and fissures or caries depends primarily on the experienced dentists, which ordinary parents do not have, and children may miss the remedial treatment without timely detection. To address this issue, we present a method to autodetect caries and pit and fissure sealing requirements using oral photos taken by smartphones. We use the YOLOv5 and YOLOX models and adopt a tiling strategy to reduce information loss during image pre-processing. The best result for YOLOXs model with tiling strategy is 72.3 mAP.5, while the best result without tiling strategy is 71.2. YOLOv5s6 model with/without tiling attains 70.9/67.9 mAP.5, respectively. We deploy the pre-trained network to mobile devices as a WeChat applet, allowing in-home detection by parents or children guardian.
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023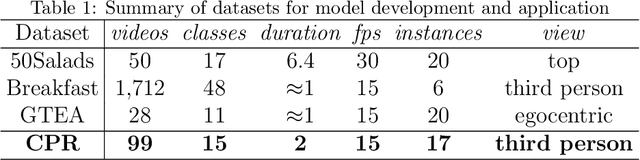
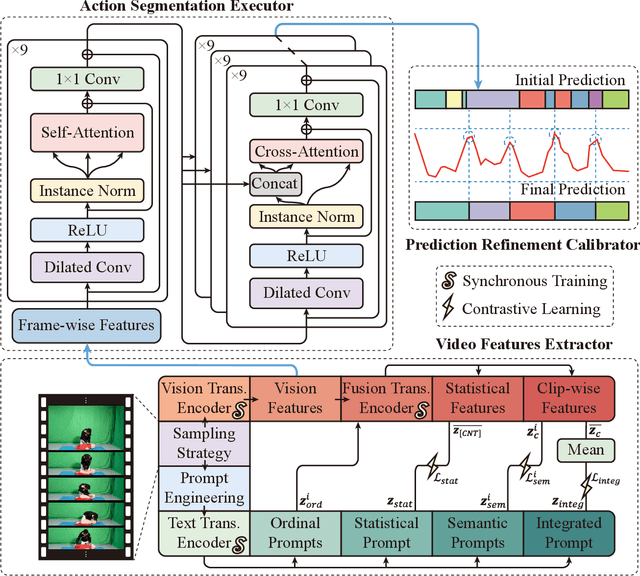
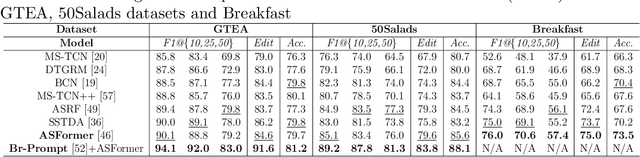

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.