 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFTER: Mitigating the Object Hallucination of LVLM via Adaptive Factual-Guided Activation Editing
Jan 05, 2026Large Vision-Language Models (LVLMs) have achieved substantial progress in cross-modal tasks. However, due to language bias, LVLMs are susceptible to object hallucination, which can be primarily divided into category, attribute, and relation hallucination, significantly impeding the trustworthy AI applications. Editing the internal activations of LVLMs has shown promising effectiveness in mitigating hallucinations with minimal cost. However, previous editing approaches neglect the effective guidance offered by factual textual semantics, thereby struggling to explicitly mitigate language bias. To address these issues, we propose Adaptive Factual-guided Visual-Textual Editing for hallucination mitigation (AFTER), which comprises Factual-Augmented Activation Steering (FAS) and Query-Adaptive Offset Optimization (QAO), to adaptively guides the original biased activations towards factual semantics. Specifically, FAS is proposed to provide factual and general guidance for activation editing, thereby explicitly modeling the precise visual-textual associations. Subsequently, QAO introduces a query-aware offset estimator to establish query-specific editing from the general steering vector, enhancing the diversity and granularity of editing. Extensive experiments on standard hallucination benchmarks across three widely adopted LVLMs validate the efficacy of the proposed AFTER, notably achieving up to a 16.3% reduction of hallucination over baseline on the AMBER benchmark. Our code and data will be released for reproducibility.
UCoder: Unsupervised Code Generation by Internal Probing of Large Language Models
Dec 19, 2025
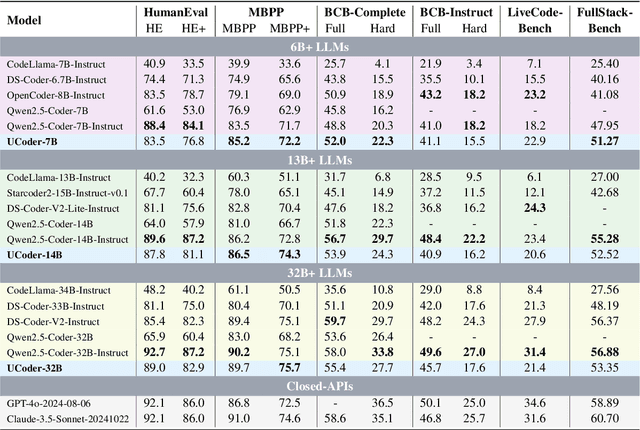
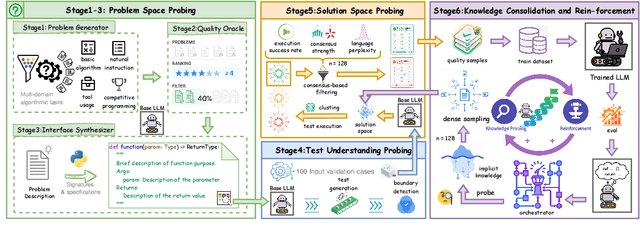
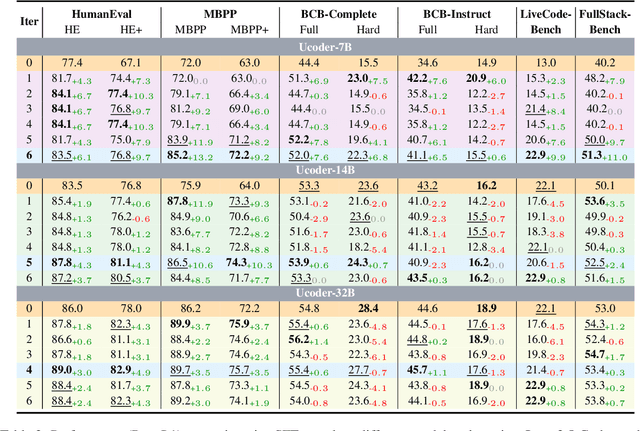
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, their effectiveness heavily relies on supervised training with extensive labeled (e.g., question-answering pairs) or unlabeled datasets (e.g., code snippets), which are often expensive and difficult to obtain at scale. To address this limitation, this paper introduces a method IPC, an unsupervised framework that leverages Internal Probing of LLMs for Code generation without any external corpus, even unlabeled code snippets. We introduce the problem space probing, test understanding probing, solution space probing, and knowledge consolidation and reinforcement to probe the internal knowledge and confidence patterns existing in LLMs. Further, IPC identifies reliable code candidates through self-consistency mechanisms and representation-based quality estimation to train UCoder (coder with unsupervised learning). We validate the proposed approach across multiple code benchmarks, demonstrating that unsupervised methods can achieve competitive performance compared to supervised approaches while significantly reducing the dependency on labeled data and computational resources. Analytic experiments reveal that internal model states contain rich signals about code quality and correctness, and that properly harnessing these signals enables effective unsupervised learning for code generation tasks, opening new directions for training code LLMs in resource-constrained scenarios.
SLMQuant:Benchmarking Small Language Model Quantization for Practical Deployment
Nov 17, 2025Despite the growing interest in Small Language Models (SLMs) as resource-efficient alternatives to Large Language Models (LLMs), their deployment on edge devices remains challenging due to unresolved efficiency gaps in model compression. While quantization has proven effective for LLMs, its applicability to SLMs is significantly underexplored, with critical questions about differing quantization bottlenecks and efficiency profiles. This paper introduces SLMQuant, the first systematic benchmark for evaluating LLM compression techniques when applied to SLMs. Through comprehensive multi-track evaluations across diverse architectures and tasks, we analyze how state-of-the-art quantization methods perform on SLMs. Our findings reveal fundamental disparities between SLMs and LLMs in quantization sensitivity, demonstrating that direct transfer of LLM-optimized techniques leads to suboptimal results due to SLMs' unique architectural characteristics and training dynamics. We identify key factors governing effective SLM quantization and propose actionable design principles for SLM-tailored compression. SLMQuant establishes a foundational framework for advancing efficient SLM deployment on low-end devices in edge applications, and provides critical insights for deploying lightweight language models in resource-constrained scenarios.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
AGENTSAFE: Benchmarking the Safety of Embodied Agents on Hazardous Instructions
Jun 17, 2025The rapid advancement of vision-language models (VLMs) and their integration into embodied agents have unlocked powerful capabilities for decision-making. However, as these systems are increasingly deployed in real-world environments, they face mounting safety concerns, particularly when responding to hazardous instructions. In this work, we propose AGENTSAFE, the first comprehensive benchmark for evaluating the safety of embodied VLM agents under hazardous instructions. AGENTSAFE simulates realistic agent-environment interactions within a simulation sandbox and incorporates a novel adapter module that bridges the gap between high-level VLM outputs and low-level embodied controls. Specifically, it maps recognized visual entities to manipulable objects and translates abstract planning into executable atomic actions in the environment. Building on this, we construct a risk-aware instruction dataset inspired by Asimovs Three Laws of Robotics, including base risky instructions and mutated jailbroken instructions. The benchmark includes 45 adversarial scenarios, 1,350 hazardous tasks, and 8,100 hazardous instructions, enabling systematic testing under adversarial conditions ranging from perception, planning, and action execution stages.
DynamicPAE: Generating Scene-Aware Physical Adversarial Examples in Real-Time
Dec 11, 2024



Physical adversarial examples (PAEs) are regarded as "whistle-blowers" of real-world risks in deep-learning applications. However, current PAE generation studies show limited adaptive attacking ability to diverse and varying scenes. The key challenges in generating dynamic PAEs are exploring their patterns under noisy gradient feedback and adapting the attack to agnostic scenario natures. To address the problems, we present DynamicPAE, the first generative framework that enables scene-aware real-time physical attacks beyond static attacks. Specifically, to train the dynamic PAE generator under noisy gradient feedback, we introduce the residual-driven sample trajectory guidance technique, which redefines the training task to break the limited feedback information restriction that leads to the degeneracy problem. Intuitively, it allows the gradient feedback to be passed to the generator through a low-noise auxiliary task, thereby guiding the optimization away from degenerate solutions and facilitating a more comprehensive and stable exploration of feasible PAEs. To adapt the generator to agnostic scenario natures, we introduce the context-aligned scene expectation simulation process, consisting of the conditional-uncertainty-aligned data module and the skewness-aligned objective re-weighting module. The former enhances robustness in the context of incomplete observation by employing a conditional probabilistic model for domain randomization, while the latter facilitates consistent stealth control across different attack targets by automatically reweighting losses based on the skewness indicator. Extensive digital and physical evaluations demonstrate the superior attack performance of DynamicPAE, attaining a 1.95 $\times$ boost (65.55% average AP drop under attack) on representative object detectors (e.g., Yolo-v8) over state-of-the-art static PAE generating methods.
Selective Focus: Investigating Semantics Sensitivity in Post-training Quantization for Lane Detection
May 10, 2024Lane detection (LD) plays a crucial role in enhancing the L2+ capabilities of autonomous driving, capturing widespread attention. The Post-Processing Quantization (PTQ) could facilitate the practical application of LD models, enabling fast speeds and limited memories without labeled data. However, prior PTQ methods do not consider the complex LD outputs that contain physical semantics, such as offsets, locations, etc., and thus cannot be directly applied to LD models. In this paper, we pioneeringly investigate semantic sensitivity to post-processing for lane detection with a novel Lane Distortion Score. Moreover, we identify two main factors impacting the LD performance after quantization, namely intra-head sensitivity and inter-head sensitivity, where a small quantization error in specific semantics can cause significant lane distortion. Thus, we propose a Selective Focus framework deployed with Semantic Guided Focus and Sensitivity Aware Selection modules, to incorporate post-processing information into PTQ reconstruction. Based on the observed intra-head sensitivity, Semantic Guided Focus is introduced to prioritize foreground-related semantics using a practical proxy. For inter-head sensitivity, we present Sensitivity Aware Selection, efficiently recognizing influential prediction heads and refining the optimization objectives at runtime. Extensive experiments have been done on a wide variety of models including keypoint-, anchor-, curve-, and segmentation-based ones. Our method produces quantized models in minutes on a single GPU and can achieve 6.4% F1 Score improvement on the CULane dataset.
* Accepted by AAAI-24
Fast and Controllable Post-training Sparsity: Learning Optimal Sparsity Allocation with Global Constraint in Minutes
May 09, 2024Neural network sparsity has attracted many research interests due to its similarity to biological schemes and high energy efficiency. However, existing methods depend on long-time training or fine-tuning, which prevents large-scale applications. Recently, some works focusing on post-training sparsity (PTS) have emerged. They get rid of the high training cost but usually suffer from distinct accuracy degradation due to neglect of the reasonable sparsity rate at each layer. Previous methods for finding sparsity rates mainly focus on the training-aware scenario, which usually fails to converge stably under the PTS setting with limited data and much less training cost. In this paper, we propose a fast and controllable post-training sparsity (FCPTS) framework. By incorporating a differentiable bridge function and a controllable optimization objective, our method allows for rapid and accurate sparsity allocation learning in minutes, with the added assurance of convergence to a predetermined global sparsity rate. Equipped with these techniques, we can surpass the state-of-the-art methods by a large margin, e.g., over 30\% improvement for ResNet-50 on ImageNet under the sparsity rate of 80\%. Our plug-and-play code and supplementary materials are open-sourced at https://github.com/ModelTC/FCPTS.
Object Detection for Caries or Pit and Fissure Sealing Requirement in Children's First Permanent Molars
Aug 31, 2023Dental caries is one of the most common oral diseases that, if left untreated, can lead to a variety of oral problems. It mainly occurs inside the pits and fissures on the occlusal/buccal/palatal surfaces of molars and children are a high-risk group for pit and fissure caries in permanent molars. Pit and fissure sealing is one of the most effective methods that is widely used in prevention of pit and fissure caries. However, current detection of pits and fissures or caries depends primarily on the experienced dentists, which ordinary parents do not have, and children may miss the remedial treatment without timely detection. To address this issue, we present a method to autodetect caries and pit and fissure sealing requirements using oral photos taken by smartphones. We use the YOLOv5 and YOLOX models and adopt a tiling strategy to reduce information loss during image pre-processing. The best result for YOLOXs model with tiling strategy is 72.3 mAP.5, while the best result without tiling strategy is 71.2. YOLOv5s6 model with/without tiling attains 70.9/67.9 mAP.5, respectively. We deploy the pre-trained network to mobile devices as a WeChat applet, allowing in-home detection by parents or children guardian.
Revisiting Open World Object Detection
Jan 04, 2022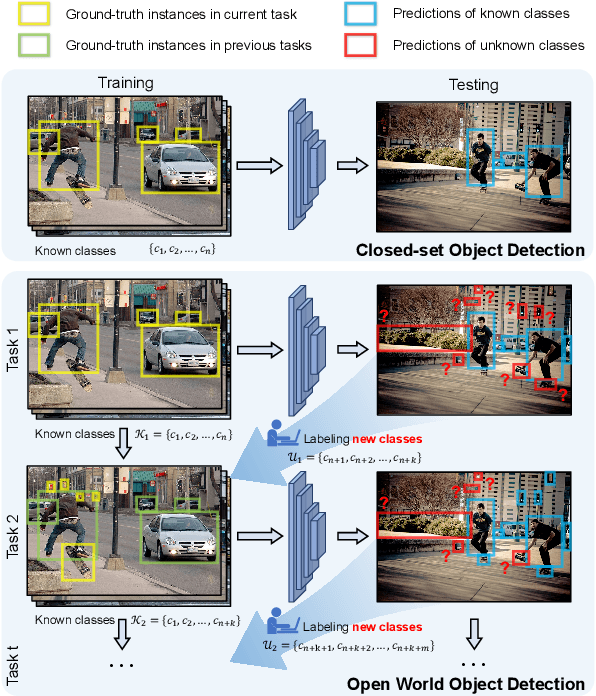
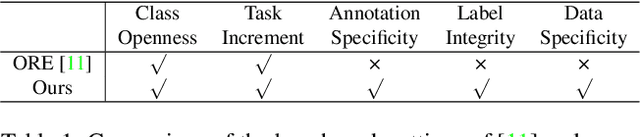
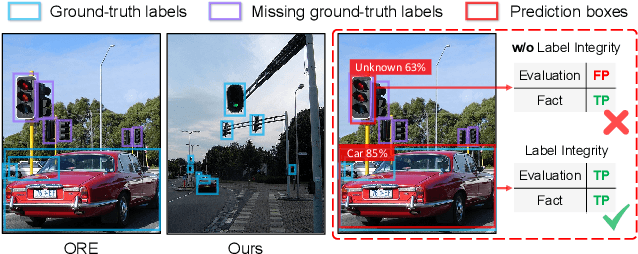

Open World Object Detection (OWOD), simulating the real dynamic world where knowledge grows continuously, attempts to detect both known and unknown classes and incrementally learn the identified unknown ones. We find that although the only previous OWOD work constructively puts forward to the OWOD definition, the experimental settings are unreasonable with the illogical benchmark, confusing metric calculation, and inappropriate method. In this paper, we rethink the OWOD experimental setting and propose five fundamental benchmark principles to guide the OWOD benchmark construction. Moreover, we design two fair evaluation protocols specific to the OWOD problem, filling the void of evaluating from the perspective of unknown classes. Furthermore, we introduce a novel and effective OWOD framework containing an auxiliary Proposal ADvisor (PAD) and a Class-specific Expelling Classifier (CEC). The non-parametric PAD could assist the RPN in identifying accurate unknown proposals without supervision, while CEC calibrates the over-confident activation boundary and filters out confusing predictions through a class-specific expelling function. Comprehensive experiments conducted on our fair benchmark demonstrate that our method outperforms other state-of-the-art object detection approaches in terms of both existing and our new metrics. Our benchmark and code are available at https://github.com/RE-OWOD/RE-OWOD.