 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Selective Focus: Investigating Semantics Sensitivity in Post-training Quantization for Lane Detection
May 10, 2024Lane detection (LD) plays a crucial role in enhancing the L2+ capabilities of autonomous driving, capturing widespread attention. The Post-Processing Quantization (PTQ) could facilitate the practical application of LD models, enabling fast speeds and limited memories without labeled data. However, prior PTQ methods do not consider the complex LD outputs that contain physical semantics, such as offsets, locations, etc., and thus cannot be directly applied to LD models. In this paper, we pioneeringly investigate semantic sensitivity to post-processing for lane detection with a novel Lane Distortion Score. Moreover, we identify two main factors impacting the LD performance after quantization, namely intra-head sensitivity and inter-head sensitivity, where a small quantization error in specific semantics can cause significant lane distortion. Thus, we propose a Selective Focus framework deployed with Semantic Guided Focus and Sensitivity Aware Selection modules, to incorporate post-processing information into PTQ reconstruction. Based on the observed intra-head sensitivity, Semantic Guided Focus is introduced to prioritize foreground-related semantics using a practical proxy. For inter-head sensitivity, we present Sensitivity Aware Selection, efficiently recognizing influential prediction heads and refining the optimization objectives at runtime. Extensive experiments have been done on a wide variety of models including keypoint-, anchor-, curve-, and segmentation-based ones. Our method produces quantized models in minutes on a single GPU and can achieve 6.4% F1 Score improvement on the CULane dataset.
* Accepted by AAAI-24
Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling
Apr 18, 2023



Quantization of transformer language models faces significant challenges due to the existence of detrimental outliers in activations. We observe that these outliers are asymmetric and concentrated in specific channels. To address this issue, we propose the Outlier Suppression+ framework. First, we introduce channel-wise shifting and scaling operations to eliminate asymmetric presentation and scale down problematic channels. We demonstrate that these operations can be seamlessly migrated into subsequent modules while maintaining equivalence. Second, we quantitatively analyze the optimal values for shifting and scaling, taking into account both the asymmetric property and quantization errors of weights in the next layer. Our lightweight framework can incur minimal performance degradation under static and standard post-training quantization settings. Comprehensive results across various tasks and models reveal that our approach achieves near-floating-point performance on both small models, such as BERT, and large language models (LLMs) including OPTs, BLOOM, and BLOOMZ at 8-bit and 6-bit settings. Furthermore, we establish a new state of the art for 4-bit BERT.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
Sep 27, 2022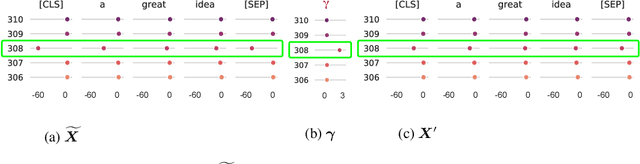

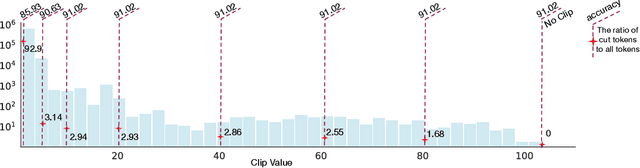

Transformer architecture has become the fundamental element of the widespread natural language processing~(NLP) models. With the trends of large NLP models, the increasing memory and computation costs hinder their efficient deployment on resource-limited devices. Therefore, transformer quantization attracts wide research interest. Recent work recognizes that structured outliers are the critical bottleneck for quantization performance. However, their proposed methods increase the computation overhead and still leave the outliers there. To fundamentally address this problem, this paper delves into the inherent inducement and importance of the outliers. We discover that $\boldsymbol \gamma$ in LayerNorm (LN) acts as a sinful amplifier for the outliers, and the importance of outliers varies greatly where some outliers provided by a few tokens cover a large area but can be clipped sharply without negative impacts. Motivated by these findings, we propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration migrates the outlier amplifier to subsequent modules in an equivalent transformation, contributing to a more quantization-friendly model without any extra burden. The Token-Wise Clipping takes advantage of the large variance of token range and designs a token-wise coarse-to-fine pipeline, obtaining a clipping range with minimal final quantization loss in an efficient way. This framework effectively suppresses the outliers and can be used in a plug-and-play mode. Extensive experiments prove that our framework surpasses the existing works and, for the first time, pushes the 6-bit post-training BERT quantization to the full-precision (FP) level. Our code is available at https://github.com/wimh966/outlier_suppression.
Distribution-sensitive Information Retention for Accurate Binary Neural Network
Sep 25, 2021

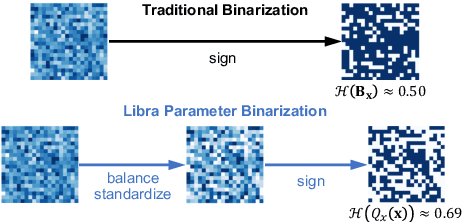

Model binarization is an effective method of compressing neural networks and accelerating their inference process, which enables state-of-the-art models to run on resource-limited devices. However, a significant performance gap still exists between the 1-bit model and the 32-bit one. The empirical study shows that binarization causes a great loss of information in the forward and backward propagation which harms the performance of binary neural networks (BNNs), and the limited information representation ability of binarized parameter is one of the bottlenecks of BNN performance. We present a novel Distribution-sensitive Information Retention Network (DIR-Net) to retain the information of the forward activations and backward gradients, which improves BNNs by distribution-sensitive optimization without increasing the overhead in the inference process. The DIR-Net mainly relies on two technical contributions: (1) Information Maximized Binarization (IMB): minimizing the information loss and the quantization error of weights/activations simultaneously by balancing and standardizing the weight distribution in the forward propagation; (2) Distribution-sensitive Two-stage Estimator (DTE): minimizing the information loss of gradients by gradual distribution-sensitive approximation of the sign function in the backward propagation, jointly considering the updating capability and accurate gradient. The DIR-Net investigates both forward and backward processes of BNNs from the unified information perspective, thereby provides new insight into the mechanism of network binarization. Comprehensive experiments on CIFAR-10 and ImageNet datasets show our DIR-Net consistently outperforms the SOTA binarization approaches under mainstream and compact architectures. Additionally, we conduct our DIR-Net on real-world resource-limited devices which achieves 11.1 times storage saving and 5.4 times speedup.
Diverse Sample Generation: Pushing the Limit of Data-free Quantization
Sep 03, 2021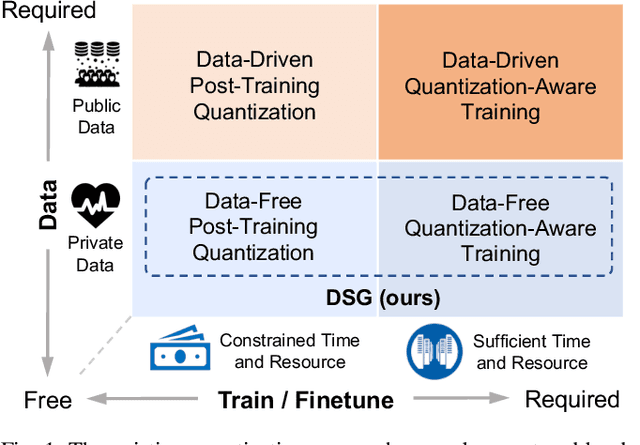
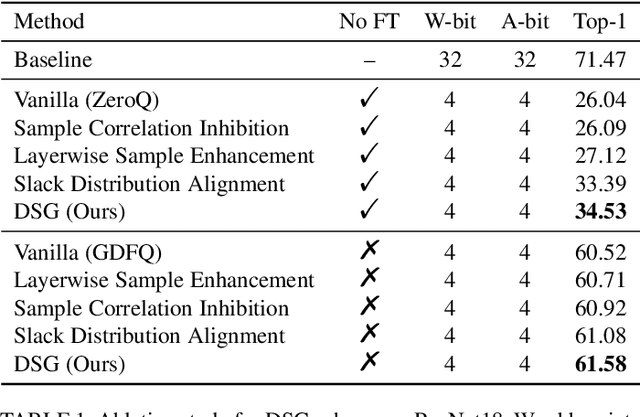
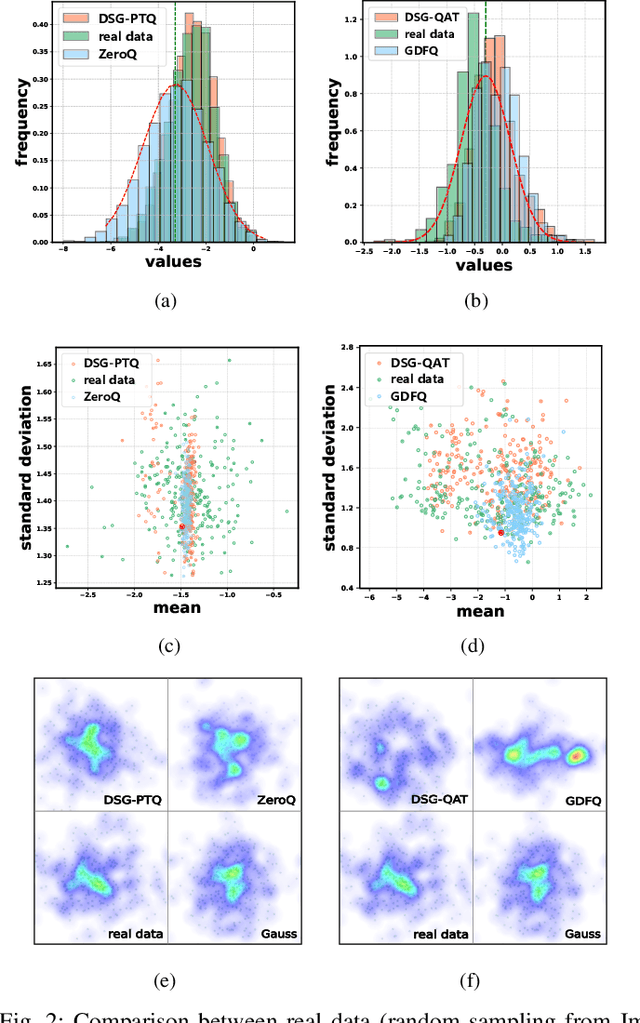
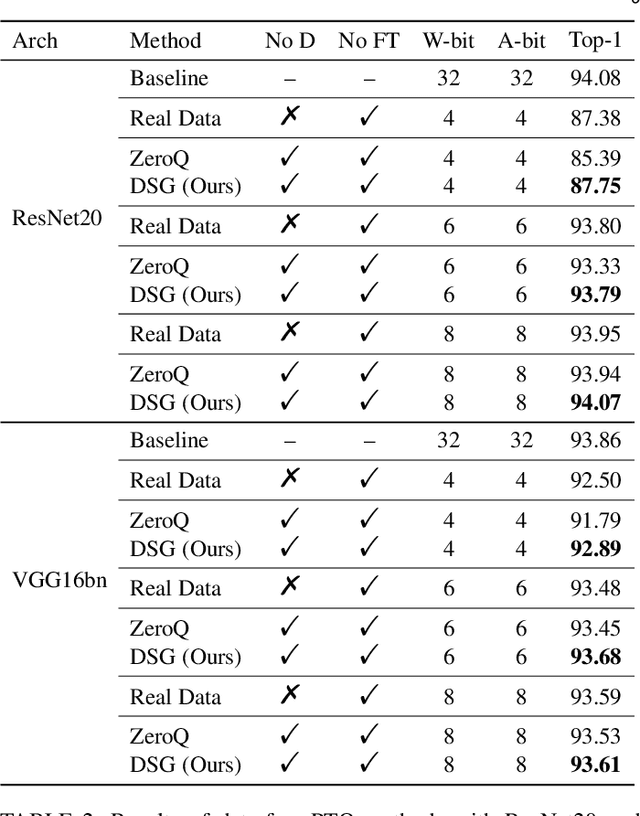
Recently, generative data-free quantization emerges as a practical approach that compresses the neural network to low bit-width without access to real data. It generates data to quantize the network by utilizing the batch normalization (BN) statistics of its full-precision counterpart. However, our study shows that in practice, the synthetic data completely constrained by BN statistics suffers severe homogenization at distribution and sample level, which causes serious accuracy degradation of the quantized network. This paper presents a generic Diverse Sample Generation (DSG) scheme for the generative data-free post-training quantization and quantization-aware training, to mitigate the detrimental homogenization. In our DSG, we first slack the statistics alignment for features in the BN layer to relax the distribution constraint. Then we strengthen the loss impact of the specific BN layer for different samples and inhibit the correlation among samples in the generation process, to diversify samples from the statistical and spatial perspective, respectively. Extensive experiments show that for large-scale image classification tasks, our DSG can consistently outperform existing data-free quantization methods on various neural architectures, especially under ultra-low bit-width (e.g., 22% gain under W4A4 setting). Moreover, data diversifying caused by our DSG brings a general gain in various quantization methods, demonstrating diversity is an important property of high-quality synthetic data for data-free quantization.
Diversifying Sample Generation for Accurate Data-Free Quantization
Mar 04, 2021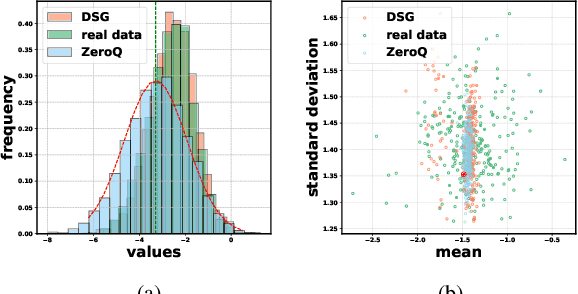

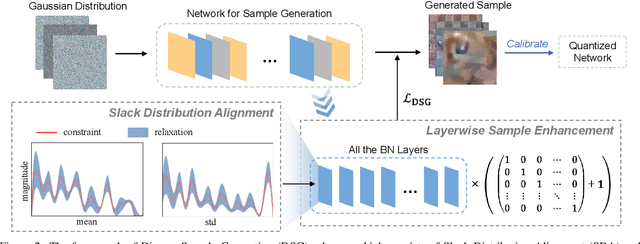
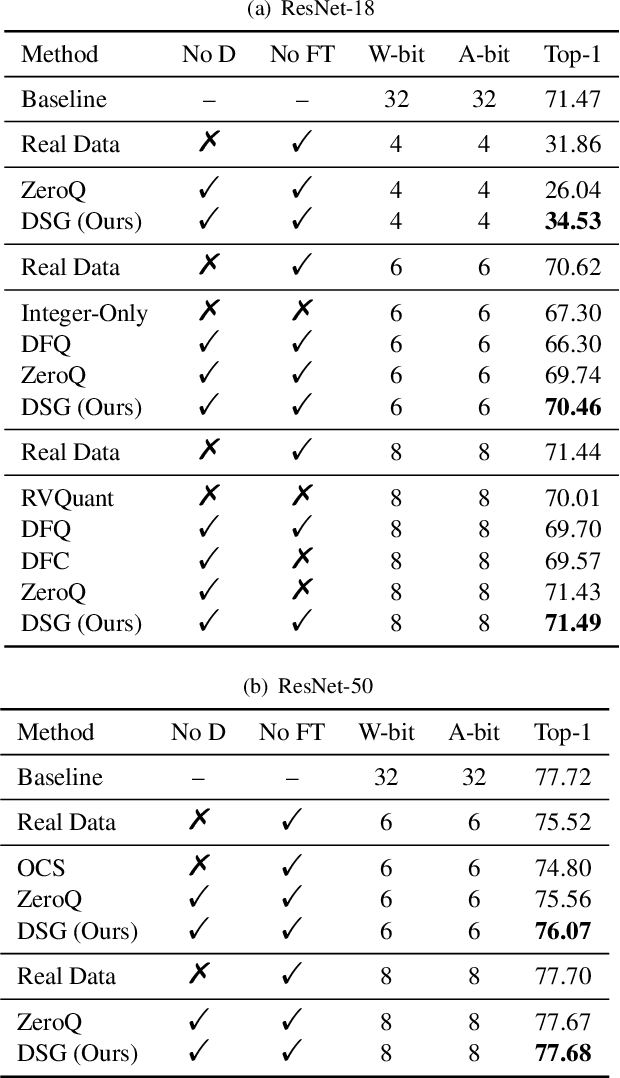
Quantization has emerged as one of the most prevalent approaches to compress and accelerate neural networks. Recently, data-free quantization has been widely studied as a practical and promising solution. It synthesizes data for calibrating the quantized model according to the batch normalization (BN) statistics of FP32 ones and significantly relieves the heavy dependency on real training data in traditional quantization methods. Unfortunately, we find that in practice, the synthetic data identically constrained by BN statistics suffers serious homogenization at both distribution level and sample level and further causes a significant performance drop of the quantized model. We propose Diverse Sample Generation (DSG) scheme to mitigate the adverse effects caused by homogenization. Specifically, we slack the alignment of feature statistics in the BN layer to relax the constraint at the distribution level and design a layerwise enhancement to reinforce specific layers for different data samples. Our DSG scheme is versatile and even able to be applied to the state-of-the-art post-training quantization method like AdaRound. We evaluate the DSG scheme on the large-scale image classification task and consistently obtain significant improvements over various network architectures and quantization methods, especially when quantized to lower bits (e.g., up to 22% improvement on W4A4). Moreover, benefiting from the enhanced diversity, models calibrated by synthetic data perform close to those calibrated by real data and even outperform them on W4A4.