 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSysNoise: Exploring and Benchmarking Training-Deployment System Inconsistency
Jul 01, 2023Extensive studies have shown that deep learning models are vulnerable to adversarial and natural noises, yet little is known about model robustness on noises caused by different system implementations. In this paper, we for the first time introduce SysNoise, a frequently occurred but often overlooked noise in the deep learning training-deployment cycle. In particular, SysNoise happens when the source training system switches to a disparate target system in deployments, where various tiny system mismatch adds up to a non-negligible difference. We first identify and classify SysNoise into three categories based on the inference stage; we then build a holistic benchmark to quantitatively measure the impact of SysNoise on 20+ models, comprehending image classification, object detection, instance segmentation and natural language processing tasks. Our extensive experiments revealed that SysNoise could bring certain impacts on model robustness across different tasks and common mitigations like data augmentation and adversarial training show limited effects on it. Together, our findings open a new research topic and we hope this work will raise research attention to deep learning deployment systems accounting for model performance. We have open-sourced the benchmark and framework at https://modeltc.github.io/systemnoise_web.
* Proceedings of Machine Learning and Systems. 2023 Mar 18
UniHCP: A Unified Model for Human-Centric Perceptions
Mar 19, 2023



Human-centric perceptions (e.g., pose estimation, human parsing, pedestrian detection, person re-identification, etc.) play a key role in industrial applications of visual models. While specific human-centric tasks have their own relevant semantic aspect to focus on, they also share the same underlying semantic structure of the human body. However, few works have attempted to exploit such homogeneity and design a general-propose model for human-centric tasks. In this work, we revisit a broad range of human-centric tasks and unify them in a minimalist manner. We propose UniHCP, a Unified Model for Human-Centric Perceptions, which unifies a wide range of human-centric tasks in a simplified end-to-end manner with the plain vision transformer architecture. With large-scale joint training on 33 human-centric datasets, UniHCP can outperform strong baselines on several in-domain and downstream tasks by direct evaluation. When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e.g., 69.8 mIoU on CIHP for human parsing, 86.18 mA on PA-100K for attribute prediction, 90.3 mAP on Market1501 for ReID, and 85.8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task.
Improving Long-tailed Object Detection with Image-Level Supervision by Multi-Task Collaborative Learning
Oct 11, 2022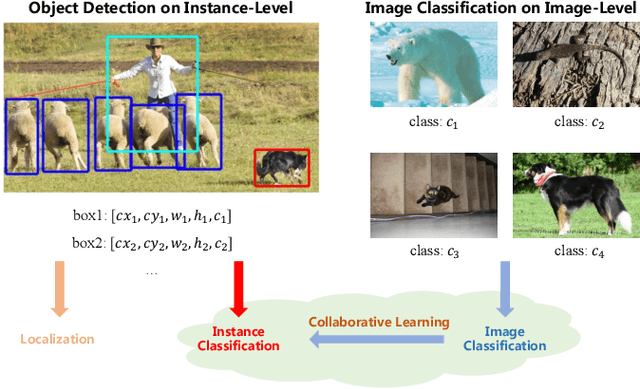
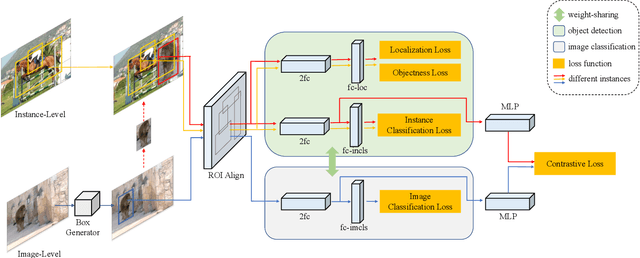
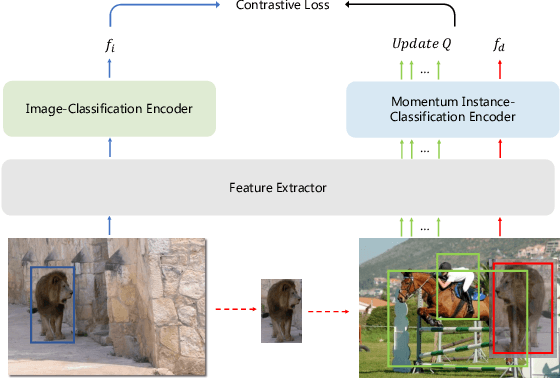

Data in real-world object detection often exhibits the long-tailed distribution. Existing solutions tackle this problem by mitigating the competition between the head and tail categories. However, due to the scarcity of training samples, tail categories are still unable to learn discriminative representations. Bringing more data into the training may alleviate the problem, but collecting instance-level annotations is an excruciating task. In contrast, image-level annotations are easily accessible but not fully exploited. In this paper, we propose a novel framework CLIS (multi-task Collaborative Learning with Image-level Supervision), which leverage image-level supervision to enhance the detection ability in a multi-task collaborative way. Specifically, there are an object detection task (consisting of an instance-classification task and a localization task) and an image-classification task in our framework, responsible for utilizing the two types of supervision. Different tasks are trained collaboratively by three key designs: (1) task-specialized sub-networks that learn specific representations of different tasks without feature entanglement. (2) a siamese sub-network for the image-classification task that shares its knowledge with the instance-classification task, resulting in feature enrichment of detectors. (3) a contrastive learning regularization that maintains representation consistency, bridging feature gaps of different supervision. Extensive experiments are conducted on the challenging LVIS dataset. Without sophisticated loss engineering, CLIS achieves an overall AP of 31.1 with 10.1 point improvement on tail categories, establishing a new state-of-the-art. Code will be at https://github.com/waveboo/CLIS.
The Equalization Losses: Gradient-Driven Training for Long-tailed Object Recognition
Oct 11, 2022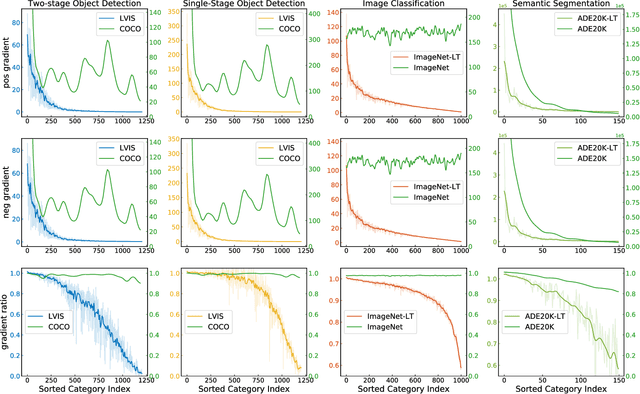
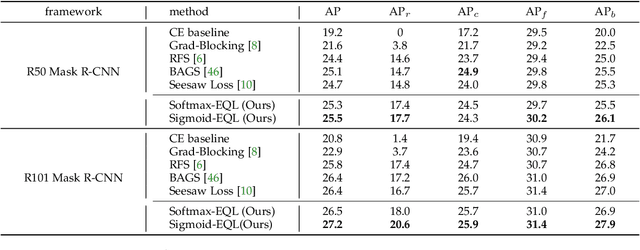

Long-tail distribution is widely spread in real-world applications. Due to the extremely small ratio of instances, tail categories often show inferior accuracy. In this paper, we find such performance bottleneck is mainly caused by the imbalanced gradients, which can be categorized into two parts: (1) positive part, deriving from the samples of the same category, and (2) negative part, contributed by other categories. Based on comprehensive experiments, it is also observed that the gradient ratio of accumulated positives to negatives is a good indicator to measure how balanced a category is trained. Inspired by this, we come up with a gradient-driven training mechanism to tackle the long-tail problem: re-balancing the positive/negative gradients dynamically according to current accumulative gradients, with a unified goal of achieving balance gradient ratios. Taking advantage of the simple and flexible gradient mechanism, we introduce a new family of gradient-driven loss functions, namely equalization losses. We conduct extensive experiments on a wide spectrum of visual tasks, including two-stage/single-stage long-tailed object detection (LVIS), long-tailed image classification (ImageNet-LT, Places-LT, iNaturalist), and long-tailed semantic segmentation (ADE20K). Our method consistently outperforms the baseline models, demonstrating the effectiveness and generalization ability of the proposed equalization losses. Codes will be released at https://github.com/ModelTC/United-Perception.
Towards Frame Rate Agnostic Multi-Object Tracking
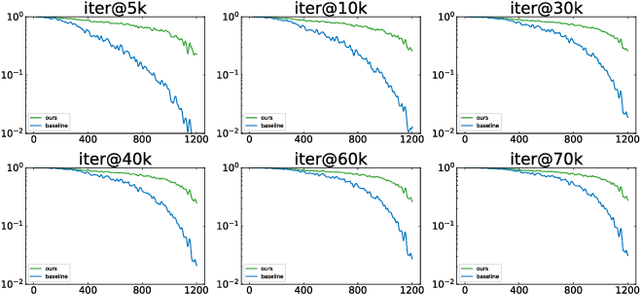
Oct 07, 2022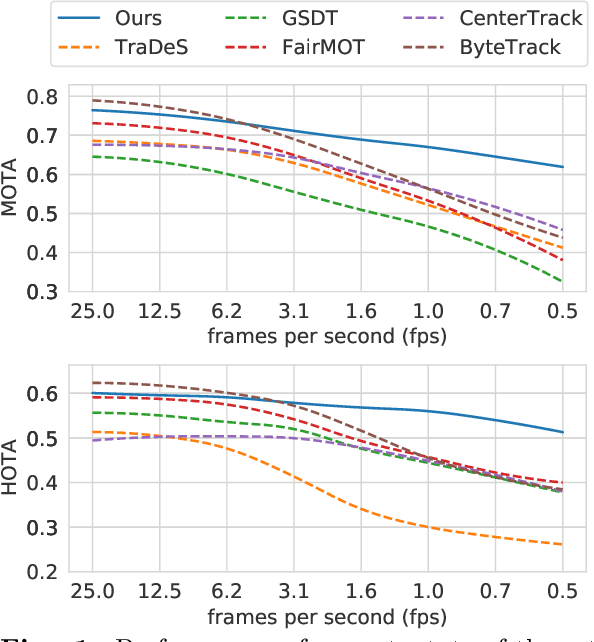

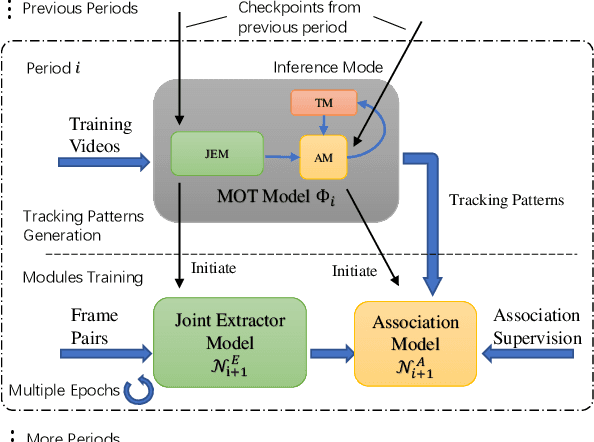
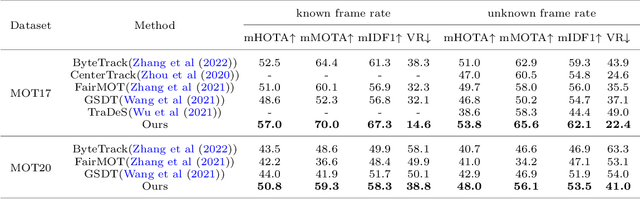
Multi-Object Tracking (MOT) is one of the most fundamental computer vision tasks which contributes to a variety of video analysis applications. Despite the recent promising progress, current MOT research is still limited to a fixed sampling frame rate of the input stream. In fact, we empirically find that the accuracy of all recent state-of-the-art trackers drops dramatically when the input frame rate changes. For a more intelligent tracking solution, we shift the attention of our research work to the problem of Frame Rate Agnostic MOT (FraMOT). In this paper, we propose a Frame Rate Agnostic MOT framework with Periodic training Scheme (FAPS) to tackle the FraMOT problem for the first time. Specifically, we propose a Frame Rate Agnostic Association Module (FAAM) that infers and encodes the frame rate information to aid identity matching across multi-frame-rate inputs, improving the capability of the learned model in handling complex motion-appearance relations in FraMOT. Besides, the association gap between training and inference is enlarged in FraMOT because those post-processing steps not included in training make a larger difference in lower frame rate scenarios. To address it, we propose Periodic Training Scheme (PTS) to reflect all post-processing steps in training via tracking pattern matching and fusion. Along with the proposed approaches, we make the first attempt to establish an evaluation method for this new task of FraMOT in two different modes, i.e., known frame rate and unknown frame rate, aiming to handle a more complex situation. The quantitative experiments on the challenging MOT datasets (FraMOT version) have clearly demonstrated that the proposed approaches can handle different frame rates better and thus improve the robustness against complicated scenarios.
Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models
Sep 27, 2022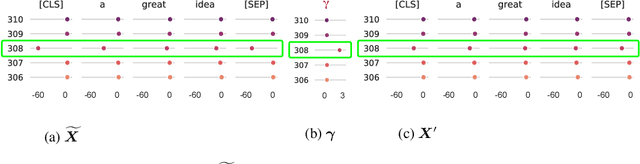

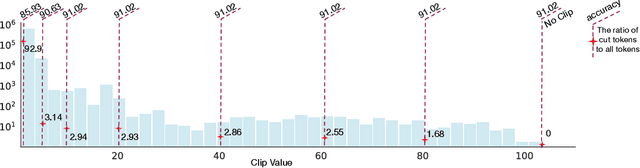

Transformer architecture has become the fundamental element of the widespread natural language processing~(NLP) models. With the trends of large NLP models, the increasing memory and computation costs hinder their efficient deployment on resource-limited devices. Therefore, transformer quantization attracts wide research interest. Recent work recognizes that structured outliers are the critical bottleneck for quantization performance. However, their proposed methods increase the computation overhead and still leave the outliers there. To fundamentally address this problem, this paper delves into the inherent inducement and importance of the outliers. We discover that $\boldsymbol \gamma$ in LayerNorm (LN) acts as a sinful amplifier for the outliers, and the importance of outliers varies greatly where some outliers provided by a few tokens cover a large area but can be clipped sharply without negative impacts. Motivated by these findings, we propose an outlier suppression framework including two components: Gamma Migration and Token-Wise Clipping. The Gamma Migration migrates the outlier amplifier to subsequent modules in an equivalent transformation, contributing to a more quantization-friendly model without any extra burden. The Token-Wise Clipping takes advantage of the large variance of token range and designs a token-wise coarse-to-fine pipeline, obtaining a clipping range with minimal final quantization loss in an efficient way. This framework effectively suppresses the outliers and can be used in a plug-and-play mode. Extensive experiments prove that our framework surpasses the existing works and, for the first time, pushes the 6-bit post-training BERT quantization to the full-precision (FP) level. Our code is available at https://github.com/wimh966/outlier_suppression.
QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization
Mar 11, 2022
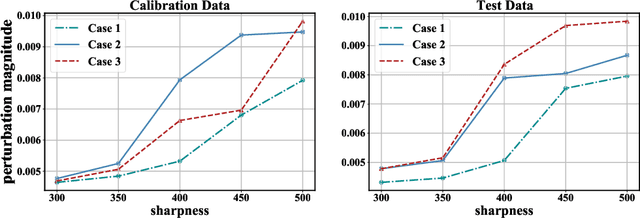

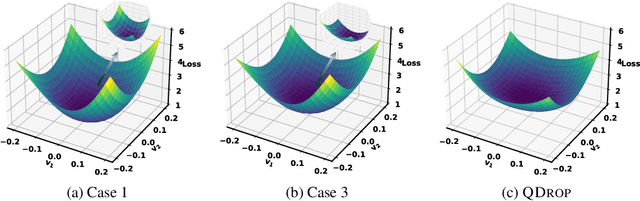
Recently, post-training quantization (PTQ) has driven much attention to produce efficient neural networks without long-time retraining. Despite its low cost, current PTQ works tend to fail under the extremely low-bit setting. In this study, we pioneeringly confirm that properly incorporating activation quantization into the PTQ reconstruction benefits the final accuracy. To deeply understand the inherent reason, a theoretical framework is established, indicating that the flatness of the optimized low-bit model on calibration and test data is crucial. Based on the conclusion, a simple yet effective approach dubbed as QDROP is proposed, which randomly drops the quantization of activations during PTQ. Extensive experiments on various tasks including computer vision (image classification, object detection) and natural language processing (text classification and question answering) prove its superiority. With QDROP, the limit of PTQ is pushed to the 2-bit activation for the first time and the accuracy boost can be up to 51.49%. Without bells and whistles, QDROP establishes a new state of the art for PTQ. Our code is available at https://github.com/wimh966/QDrop and has been integrated into MQBench (https://github.com/ModelTC/MQBench)
Equalized Focal Loss for Dense Long-Tailed Object Detection
Jan 07, 2022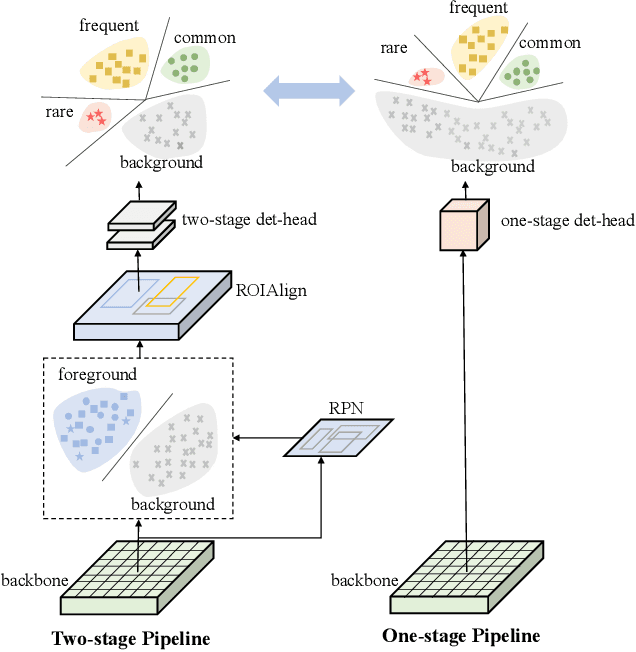
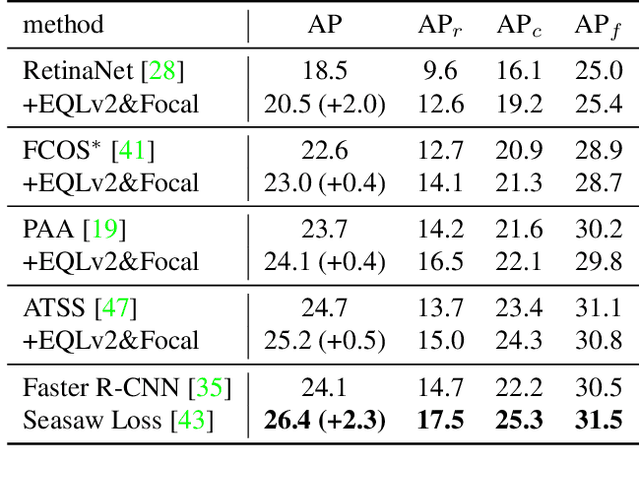
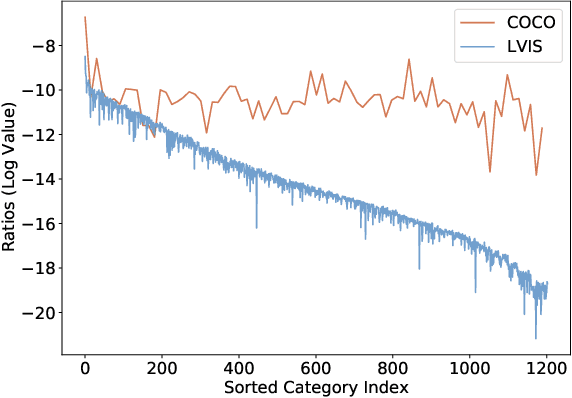
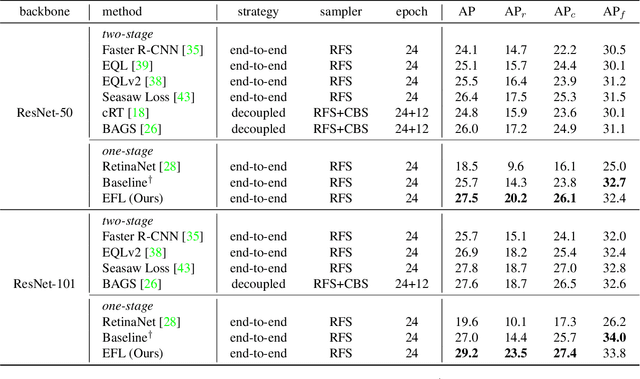
Despite the recent success of long-tailed object detection, almost all long-tailed object detectors are developed based on the two-stage paradigm. In practice, one-stage detectors are more prevalent in the industry because they have a simple and fast pipeline that is easy to deploy. However, in the long-tailed scenario, this line of work has not been explored so far. In this paper, we investigate whether one-stage detectors can perform well in this case. We discover the primary obstacle that prevents one-stage detectors from achieving excellent performance is: categories suffer from different degrees of positive-negative imbalance problems under the long-tailed data distribution. The conventional focal loss balances the training process with the same modulating factor for all categories, thus failing to handle the long-tailed problem. To address this issue, we propose the Equalized Focal Loss (EFL) that rebalances the loss contribution of positive and negative samples of different categories independently according to their imbalance degrees. Specifically, EFL adopts a category-relevant modulating factor which can be adjusted dynamically by the training status of different categories. Extensive experiments conducted on the challenging LVIS v1 benchmark demonstrate the effectiveness of our proposed method. With an end-to-end training pipeline, EFL achieves 29.2% in terms of overall AP and obtains significant performance improvements on rare categories, surpassing all existing state-of-the-art methods. The code is available at https://github.com/ModelTC/EOD.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021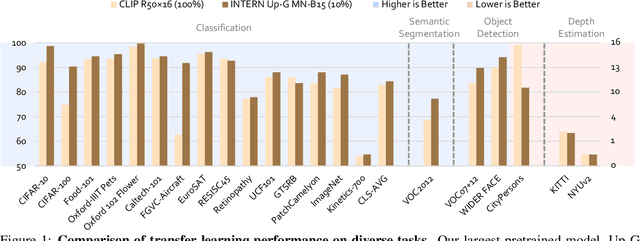
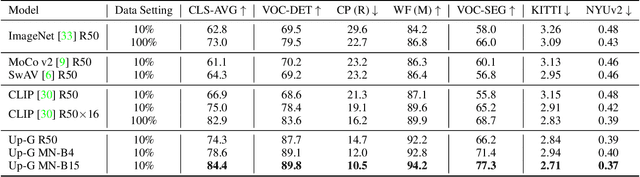
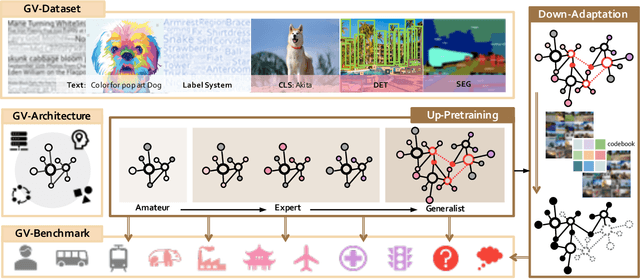
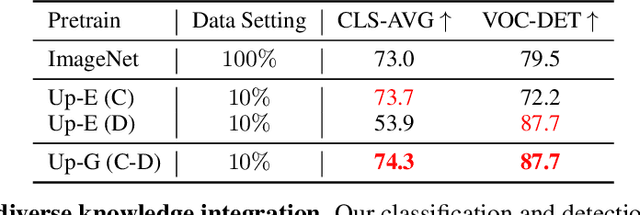
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
Nov 05, 2021
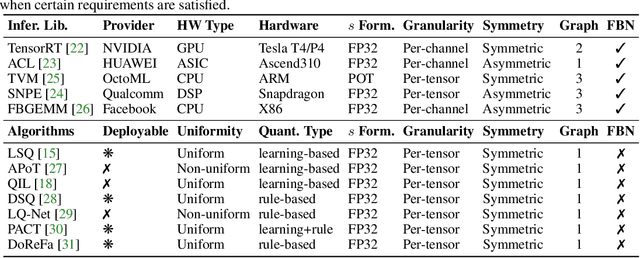

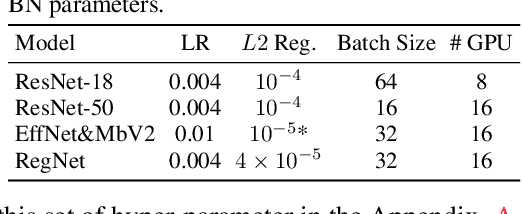
Model quantization has emerged as an indispensable technique to accelerate deep learning inference. While researchers continue to push the frontier of quantization algorithms, existing quantization work is often unreproducible and undeployable. This is because researchers do not choose consistent training pipelines and ignore the requirements for hardware deployments. In this work, we propose Model Quantization Benchmark (MQBench), a first attempt to evaluate, analyze, and benchmark the reproducibility and deployability for model quantization algorithms. We choose multiple different platforms for real-world deployments, including CPU, GPU, ASIC, DSP, and evaluate extensive state-of-the-art quantization algorithms under a unified training pipeline. MQBench acts like a bridge to connect the algorithm and the hardware. We conduct a comprehensive analysis and find considerable intuitive or counter-intuitive insights. By aligning the training settings, we find existing algorithms have about the same performance on the conventional academic track. While for the hardware-deployable quantization, there is a huge accuracy gap which remains unsettled. Surprisingly, no existing algorithm wins every challenge in MQBench, and we hope this work could inspire future research directions.