 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead
Apr 06, 2023



We present FengWu, an advanced data-driven global medium-range weather forecast system based on Artificial Intelligence (AI). Different from existing data-driven weather forecast methods, FengWu solves the medium-range forecast problem from a multi-modal and multi-task perspective. Specifically, a deep learning architecture equipped with model-specific encoder-decoders and cross-modal fusion Transformer is elaborately designed, which is learned under the supervision of an uncertainty loss to balance the optimization of different predictors in a region-adaptive manner. Besides this, a replay buffer mechanism is introduced to improve medium-range forecast performance. With 39-year data training based on the ERA5 reanalysis, FengWu is able to accurately reproduce the atmospheric dynamics and predict the future land and atmosphere states at 37 vertical levels on a 0.25{\deg} latitude-longitude resolution. Hindcasts of 6-hourly weather in 2018 based on ERA5 demonstrate that FengWu performs better than GraphCast in predicting 80\% of the 880 reported predictands, e.g., reducing the root mean square error (RMSE) of 10-day lead global z500 prediction from 733 to 651 $m^{2}/s^2$. In addition, the inference cost of each iteration is merely 600ms on NVIDIA Tesla A100 hardware. The results suggest that FengWu can significantly improve the forecast skill and extend the skillful global medium-range weather forecast out to 10.75 days lead (with ACC of z500 > 0.6) for the first time.
UniHCP: A Unified Model for Human-Centric Perceptions
Mar 19, 2023



Human-centric perceptions (e.g., pose estimation, human parsing, pedestrian detection, person re-identification, etc.) play a key role in industrial applications of visual models. While specific human-centric tasks have their own relevant semantic aspect to focus on, they also share the same underlying semantic structure of the human body. However, few works have attempted to exploit such homogeneity and design a general-propose model for human-centric tasks. In this work, we revisit a broad range of human-centric tasks and unify them in a minimalist manner. We propose UniHCP, a Unified Model for Human-Centric Perceptions, which unifies a wide range of human-centric tasks in a simplified end-to-end manner with the plain vision transformer architecture. With large-scale joint training on 33 human-centric datasets, UniHCP can outperform strong baselines on several in-domain and downstream tasks by direct evaluation. When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e.g., 69.8 mIoU on CIHP for human parsing, 86.18 mA on PA-100K for attribute prediction, 90.3 mAP on Market1501 for ReID, and 85.8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task.
HumanBench: Towards General Human-centric Perception with Projector Assisted Pretraining
Mar 10, 2023



Human-centric perceptions include a variety of vision tasks, which have widespread industrial applications, including surveillance, autonomous driving, and the metaverse. It is desirable to have a general pretrain model for versatile human-centric downstream tasks. This paper forges ahead along this path from the aspects of both benchmark and pretraining methods. Specifically, we propose a \textbf{HumanBench} based on existing datasets to comprehensively evaluate on the common ground the generalization abilities of different pretraining methods on 19 datasets from 6 diverse downstream tasks, including person ReID, pose estimation, human parsing, pedestrian attribute recognition, pedestrian detection, and crowd counting. To learn both coarse-grained and fine-grained knowledge in human bodies, we further propose a \textbf{P}rojector \textbf{A}ssis\textbf{T}ed \textbf{H}ierarchical pretraining method (\textbf{PATH}) to learn diverse knowledge at different granularity levels. Comprehensive evaluations on HumanBench show that our PATH achieves new state-of-the-art results on 17 downstream datasets and on-par results on the other 2 datasets. The code will be publicly at \href{https://github.com/OpenGVLab/HumanBench}{https://github.com/OpenGVLab/HumanBench}.
Fast-MoCo: Boost Momentum-based Contrastive Learning with Combinatorial Patches
Jul 19, 2022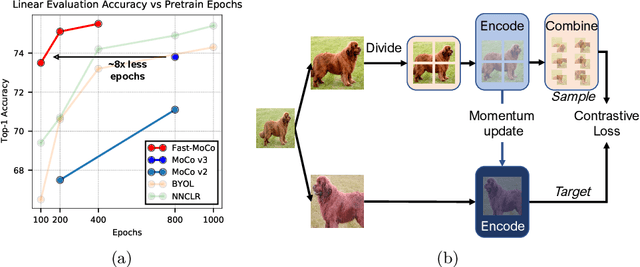



Contrastive-based self-supervised learning methods achieved great success in recent years. However, self-supervision requires extremely long training epochs (e.g., 800 epochs for MoCo v3) to achieve promising results, which is unacceptable for the general academic community and hinders the development of this topic. This work revisits the momentum-based contrastive learning frameworks and identifies the inefficiency in which two augmented views generate only one positive pair. We propose Fast-MoCo - a novel framework that utilizes combinatorial patches to construct multiple positive pairs from two augmented views, which provides abundant supervision signals that bring significant acceleration with neglectable extra computational cost. Fast-MoCo trained with 100 epochs achieves 73.5% linear evaluation accuracy, similar to MoCo v3 (ResNet-50 backbone) trained with 800 epochs. Extra training (200 epochs) further improves the result to 75.1%, which is on par with state-of-the-art methods. Experiments on several downstream tasks also confirm the effectiveness of Fast-MoCo.
Evolving Search Space for Neural Architecture Search
Nov 22, 2020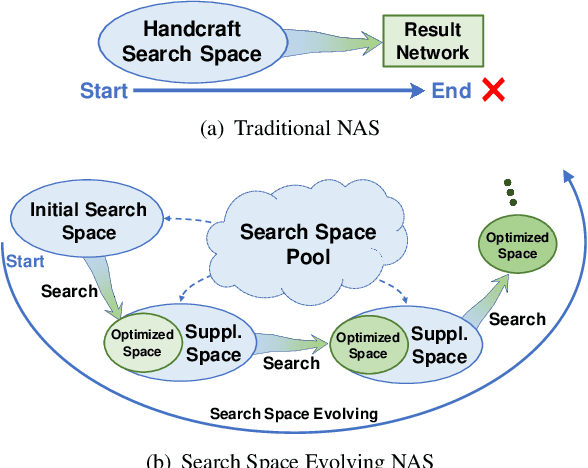
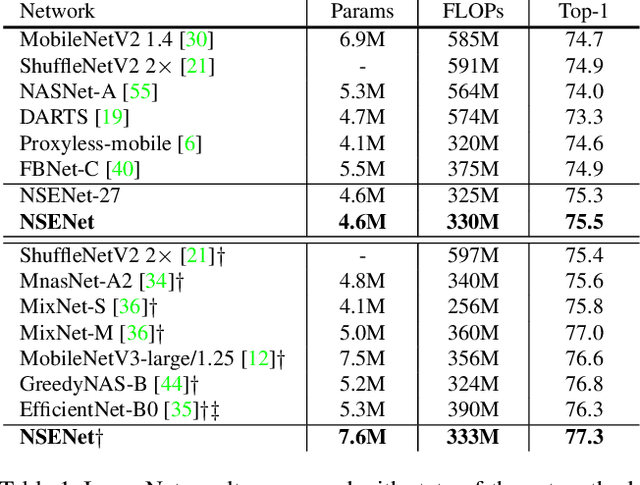


The automation of neural architecture design has been a coveted alternative to human experts. Recent works have small search space, which is easier to optimize but has a limited upper bound of the optimal solution. Extra human design is needed for those methods to propose a more suitable space with respect to the specific task and algorithm capacity. To further enhance the degree of automation for neural architecture search, we present a Neural Search-space Evolution (NSE) scheme that iteratively amplifies the results from the previous effort by maintaining an optimized search space subset. This design minimizes the necessity of a well-designed search space. We further extend the flexibility of obtainable architectures by introducing a learnable multi-branch setting. By employing the proposed method, a consistent performance gain is achieved during a progressive search over upcoming search spaces. We achieve 77.3% top-1 retrain accuracy on ImageNet with 333M FLOPs, which yielded a state-of-the-art performance among previous auto-generated architectures that do not involve knowledge distillation or weight pruning. When the latency constraint is adopted, our result also performs better than the previous best-performing mobile models with a 77.9% Top-1 retrain accuracy.
User-Guided Deep Anime Line Art Colorization with Conditional Adversarial Networks
Aug 10, 2018

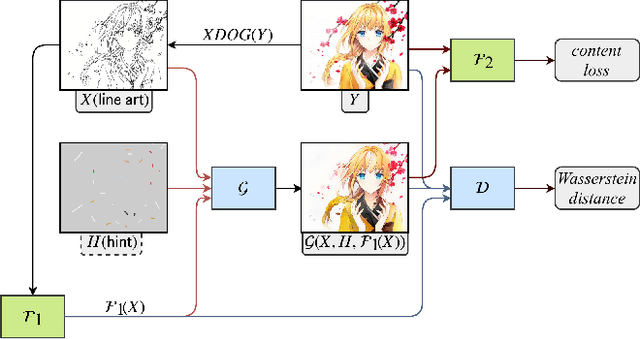

Scribble colors based line art colorization is a challenging computer vision problem since neither greyscale values nor semantic information is presented in line arts, and the lack of authentic illustration-line art training pairs also increases difficulty of model generalization. Recently, several Generative Adversarial Nets (GANs) based methods have achieved great success. They can generate colorized illustrations conditioned on given line art and color hints. However, these methods fail to capture the authentic illustration distributions and are hence perceptually unsatisfying in the sense that they often lack accurate shading. To address these challenges, we propose a novel deep conditional adversarial architecture for scribble based anime line art colorization. Specifically, we integrate the conditional framework with WGAN-GP criteria as well as the perceptual loss to enable us to robustly train a deep network that makes the synthesized images more natural and real. We also introduce a local features network that is independent of synthetic data. With GANs conditioned on features from such network, we notably increase the generalization capability over "in the wild" line arts. Furthermore, we collect two datasets that provide high-quality colorful illustrations and authentic line arts for training and benchmarking. With the proposed model trained on our illustration dataset, we demonstrate that images synthesized by the presented approach are considerably more realistic and precise than alternative approaches.