 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-MoCo: Boost Momentum-based Contrastive Learning with Combinatorial Patches
Paper and Code
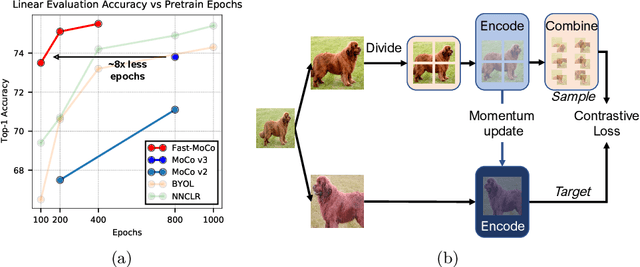



Contrastive-based self-supervised learning methods achieved great success in recent years. However, self-supervision requires extremely long training epochs (e.g., 800 epochs for MoCo v3) to achieve promising results, which is unacceptable for the general academic community and hinders the development of this topic. This work revisits the momentum-based contrastive learning frameworks and identifies the inefficiency in which two augmented views generate only one positive pair. We propose Fast-MoCo - a novel framework that utilizes combinatorial patches to construct multiple positive pairs from two augmented views, which provides abundant supervision signals that bring significant acceleration with neglectable extra computational cost. Fast-MoCo trained with 100 epochs achieves 73.5% linear evaluation accuracy, similar to MoCo v3 (ResNet-50 backbone) trained with 800 epochs. Extra training (200 epochs) further improves the result to 75.1%, which is on par with state-of-the-art methods. Experiments on several downstream tasks also confirm the effectiveness of Fast-MoCo.