 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACLR: A Scalable and Efficient Retrieval-based Method for Industrial Product Attribute Value Identification
Jan 07, 2025Product Attribute Value Identification (PAVI) involves identifying attribute values from product profiles, a key task for improving product search, recommendations, and business analytics on e-commerce platforms. However, existing PAVI methods face critical challenges, such as inferring implicit values, handling out-of-distribution (OOD) values, and producing normalized outputs. To address these limitations, we introduce Taxonomy-Aware Contrastive Learning Retrieval (TACLR), the first retrieval-based method for PAVI. TACLR formulates PAVI as an information retrieval task by encoding product profiles and candidate values into embeddings and retrieving values based on their similarity to the item embedding. It leverages contrastive training with taxonomy-aware hard negative sampling and employs adaptive inference with dynamic thresholds. TACLR offers three key advantages: (1) it effectively handles implicit and OOD values while producing normalized outputs; (2) it scales to thousands of categories, tens of thousands of attributes, and millions of values; and (3) it supports efficient inference for high-load industrial scenarios. Extensive experiments on proprietary and public datasets validate the effectiveness and efficiency of TACLR. Moreover, it has been successfully deployed in a real-world e-commerce platform, processing millions of product listings daily while supporting dynamic, large-scale attribute taxonomies.
HumanBench: Towards General Human-centric Perception with Projector Assisted Pretraining
Mar 10, 2023



Human-centric perceptions include a variety of vision tasks, which have widespread industrial applications, including surveillance, autonomous driving, and the metaverse. It is desirable to have a general pretrain model for versatile human-centric downstream tasks. This paper forges ahead along this path from the aspects of both benchmark and pretraining methods. Specifically, we propose a \textbf{HumanBench} based on existing datasets to comprehensively evaluate on the common ground the generalization abilities of different pretraining methods on 19 datasets from 6 diverse downstream tasks, including person ReID, pose estimation, human parsing, pedestrian attribute recognition, pedestrian detection, and crowd counting. To learn both coarse-grained and fine-grained knowledge in human bodies, we further propose a \textbf{P}rojector \textbf{A}ssis\textbf{T}ed \textbf{H}ierarchical pretraining method (\textbf{PATH}) to learn diverse knowledge at different granularity levels. Comprehensive evaluations on HumanBench show that our PATH achieves new state-of-the-art results on 17 downstream datasets and on-par results on the other 2 datasets. The code will be publicly at \href{https://github.com/OpenGVLab/HumanBench}{https://github.com/OpenGVLab/HumanBench}.
Saliency Guided Contrastive Learning on Scene Images
Feb 23, 2023



Self-supervised learning holds promise in leveraging large numbers of unlabeled data. However, its success heavily relies on the highly-curated dataset, e.g., ImageNet, which still needs human cleaning. Directly learning representations from less-curated scene images is essential for pushing self-supervised learning to a higher level. Different from curated images which include simple and clear semantic information, scene images are more complex and mosaic because they often include complex scenes and multiple objects. Despite being feasible, recent works largely overlooked discovering the most discriminative regions for contrastive learning to object representations in scene images. In this work, we leverage the saliency map derived from the model's output during learning to highlight these discriminative regions and guide the whole contrastive learning. Specifically, the saliency map first guides the method to crop its discriminative regions as positive pairs and then reweighs the contrastive losses among different crops by its saliency scores. Our method significantly improves the performance of self-supervised learning on scene images by +1.1, +4.3, +2.2 Top1 accuracy in ImageNet linear evaluation, Semi-supervised learning with 1% and 10% ImageNet labels, respectively. We hope our insights on saliency maps can motivate future research on more general-purpose unsupervised representation learning from scene data.
Spatial-Temporal Graph Convolutional Gated Recurrent Network for Traffic Forecasting
Oct 06, 2022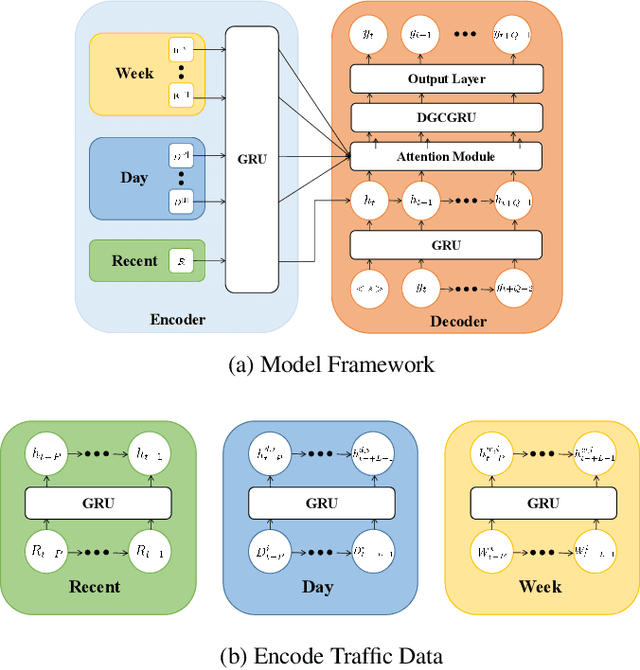
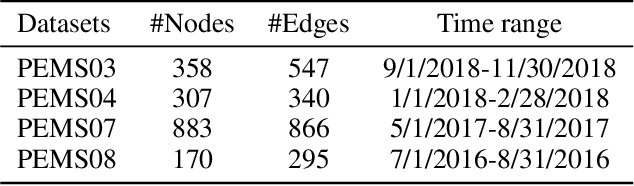
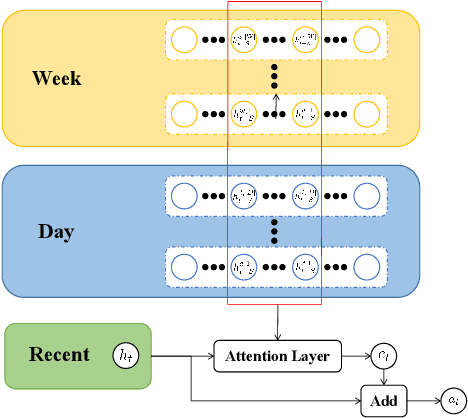
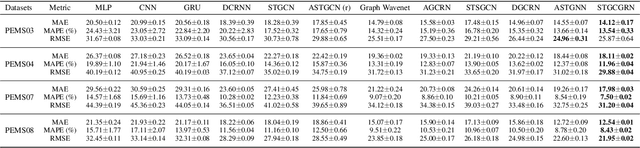
As an important part of intelligent transportation systems, traffic forecasting has attracted tremendous attention from academia and industry. Despite a lot of methods being proposed for traffic forecasting, it is still difficult to model complex spatial-temporal dependency. Temporal dependency includes short-term dependency and long-term dependency, and the latter is often overlooked. Spatial dependency can be divided into two parts: distance-based spatial dependency and hidden spatial dependency. To model complex spatial-temporal dependency, we propose a novel framework for traffic forecasting, named Spatial-Temporal Graph Convolutional Gated Recurrent Network (STGCGRN). We design an attention module to capture long-term dependency by mining periodic information in traffic data. We propose a Double Graph Convolution Gated Recurrent Unit (DGCGRU) to capture spatial dependency, which integrates graph convolutional network and GRU. The graph convolution part models distance-based spatial dependency with the distance-based predefined adjacency matrix and hidden spatial dependency with the self-adaptive adjacency matrix, respectively. Specially, we employ the multi-head mechanism to capture multiple hidden dependencies. In addition, the periodic pattern of each prediction node may be different, which is often ignored, resulting in mutual interference of periodic information among nodes when modeling spatial dependency. For this, we explore the architecture of model and improve the performance. Experiments on four datasets demonstrate the superior performance of our model.
Domain Invariant Masked Autoencoders for Self-supervised Learning from Multi-domains
May 10, 2022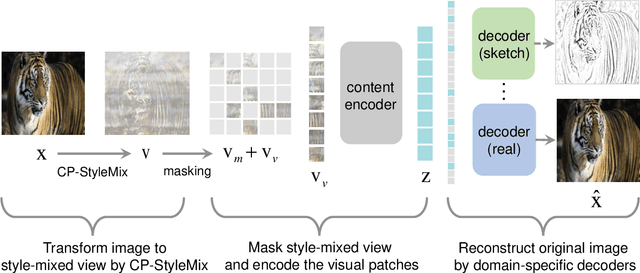
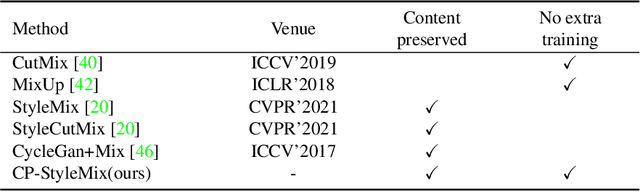

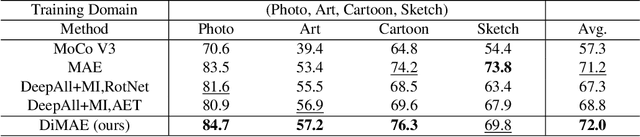
Generalizing learned representations across significantly different visual domains is a fundamental yet crucial ability of the human visual system. While recent self-supervised learning methods have achieved good performances with evaluation set on the same domain as the training set, they will have an undesirable performance decrease when tested on a different domain. Therefore, the self-supervised learning from multiple domains task is proposed to learn domain-invariant features that are not only suitable for evaluation on the same domain as the training set but also can be generalized to unseen domains. In this paper, we propose a Domain-invariant Masked AutoEncoder (DiMAE) for self-supervised learning from multi-domains, which designs a new pretext task, \emph{i.e.,} the cross-domain reconstruction task, to learn domain-invariant features. The core idea is to augment the input image with style noise from different domains and then reconstruct the image from the embedding of the augmented image, regularizing the encoder to learn domain-invariant features. To accomplish the idea, DiMAE contains two critical designs, 1) content-preserved style mix, which adds style information from other domains to input while persevering the content in a parameter-free manner, and 2) multiple domain-specific decoders, which recovers the corresponding domain style of input to the encoded domain-invariant features for reconstruction. Experiments on PACS and DomainNet illustrate that DiMAE achieves considerable gains compared with recent state-of-the-art methods.
Generation, augmentation, and alignment: A pseudo-source domain based method for source-free domain adaptation
Sep 09, 2021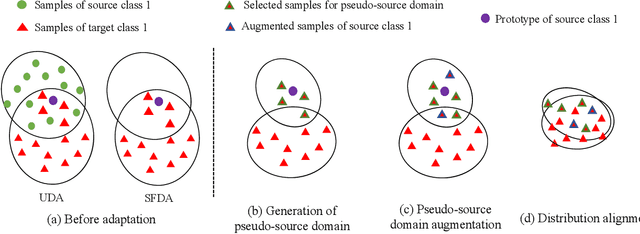
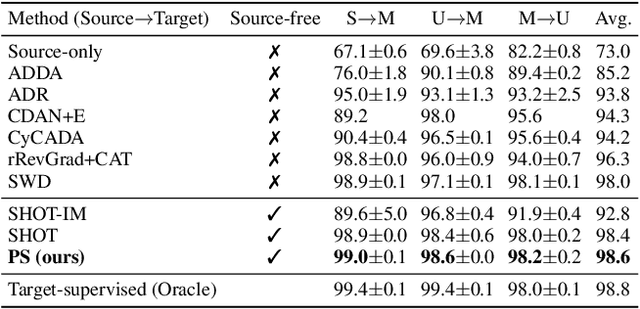
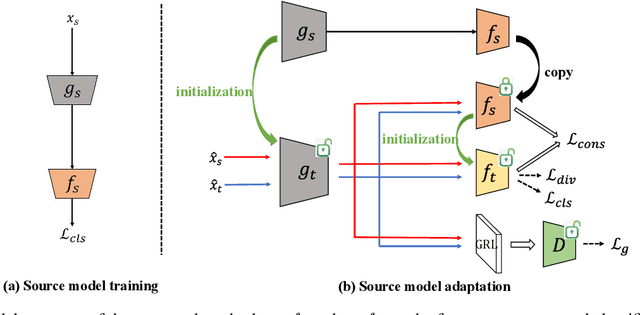
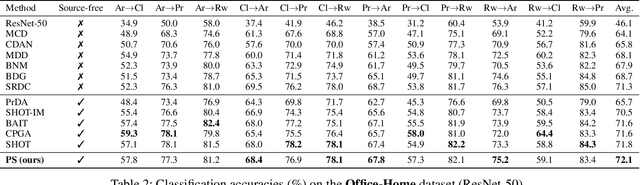
Conventional unsupervised domain adaptation (UDA) methods need to access both labeled source samples and unlabeled target samples simultaneously to train the model. While in some scenarios, the source samples are not available for the target domain due to data privacy and safety. To overcome this challenge, recently, source-free domain adaptation (SFDA) has attracted the attention of researchers, where both a trained source model and unlabeled target samples are given. Existing SFDA methods either adopt a pseudo-label based strategy or generate more samples. However, these methods do not explicitly reduce the distribution shift across domains, which is the key to a good adaptation. Although there are no source samples available, fortunately, we find that some target samples are very similar to the source domain and can be used to approximate the source domain. This approximated domain is denoted as the pseudo-source domain. In this paper, inspired by this observation, we propose a novel method based on the pseudo-source domain. The proposed method firstly generates and augments the pseudo-source domain, and then employs distribution alignment with four novel losses based on pseudo-label based strategy. Among them, a domain adversarial loss is introduced between the pseudo-source domain the remaining target domain to reduce the distribution shift. The results on three real-world datasets verify the effectiveness of the proposed method.