 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIU4Rec: Interest Unit-Based Product Organization and Recommendation for E-Commerce Platform
Feb 11, 2025Most recommendation systems typically follow a product-based paradigm utilizing user-product interactions to identify the most engaging items for users. However, this product-based paradigm has notable drawbacks for Xianyu~\footnote{Xianyu is China's largest online C2C e-commerce platform where a large portion of the product are post by individual sellers}. Most of the product on Xianyu posted from individual sellers often have limited stock available for distribution, and once the product is sold, it's no longer available for distribution. This result in most items distributed product on Xianyu having relatively few interactions, affecting the effectiveness of traditional recommendation depending on accumulating user-item interactions. To address these issues, we introduce \textbf{IU4Rec}, an \textbf{I}nterest \textbf{U}nit-based two-stage \textbf{Rec}ommendation system framework. We first group products into clusters based on attributes such as category, image, and semantics. These IUs are then integrated into the Recommendation system, delivering both product and technological innovations. IU4Rec begins by grouping products into clusters based on attributes such as category, image, and semantics, forming Interest Units (IUs). Then we redesign the recommendation process into two stages. In the first stage, the focus is on recommend these Interest Units, capturing broad-level interests. In the second stage, it guides users to find the best option among similar products within the selected Interest Unit. User-IU interactions are incorporated into our ranking models, offering the advantage of more persistent IU behaviors compared to item-specific interactions. Experimental results on the production dataset and online A/B testing demonstrate the effectiveness and superiority of our proposed IU-centric recommendation approach.
TACLR: A Scalable and Efficient Retrieval-based Method for Industrial Product Attribute Value Identification
Jan 07, 2025Product Attribute Value Identification (PAVI) involves identifying attribute values from product profiles, a key task for improving product search, recommendations, and business analytics on e-commerce platforms. However, existing PAVI methods face critical challenges, such as inferring implicit values, handling out-of-distribution (OOD) values, and producing normalized outputs. To address these limitations, we introduce Taxonomy-Aware Contrastive Learning Retrieval (TACLR), the first retrieval-based method for PAVI. TACLR formulates PAVI as an information retrieval task by encoding product profiles and candidate values into embeddings and retrieving values based on their similarity to the item embedding. It leverages contrastive training with taxonomy-aware hard negative sampling and employs adaptive inference with dynamic thresholds. TACLR offers three key advantages: (1) it effectively handles implicit and OOD values while producing normalized outputs; (2) it scales to thousands of categories, tens of thousands of attributes, and millions of values; and (3) it supports efficient inference for high-load industrial scenarios. Extensive experiments on proprietary and public datasets validate the effectiveness and efficiency of TACLR. Moreover, it has been successfully deployed in a real-world e-commerce platform, processing millions of product listings daily while supporting dynamic, large-scale attribute taxonomies.
IPL: Leveraging Multimodal Large Language Models for Intelligent Product Listing
Oct 22, 2024



Unlike professional Business-to-Consumer (B2C) e-commerce platforms (e.g., Amazon), Consumer-to-Consumer (C2C) platforms (e.g., Facebook marketplace) are mainly targeting individual sellers who usually lack sufficient experience in e-commerce. Individual sellers often struggle to compose proper descriptions for selling products. With the recent advancement of Multimodal Large Language Models (MLLMs), we attempt to integrate such state-of-the-art generative AI technologies into the product listing process. To this end, we develop IPL, an Intelligent Product Listing tool tailored to generate descriptions using various product attributes such as category, brand, color, condition, etc. IPL enables users to compose product descriptions by merely uploading photos of the selling product. More importantly, it can imitate the content style of our C2C platform Xianyu. This is achieved by employing domain-specific instruction tuning on MLLMs and adopting the multi-modal Retrieval-Augmented Generation (RAG) process. A comprehensive empirical evaluation demonstrates that the underlying model of IPL significantly outperforms the base model in domain-specific tasks while producing less hallucination. IPL has been successfully deployed in our production system, where 72% of users have their published product listings based on the generated content, and those product listings are shown to have a quality score 5.6% higher than those without AI assistance.
Realistic Re-evaluation of Knowledge Graph Completion Methods: An Experimental Study
Mar 18, 2020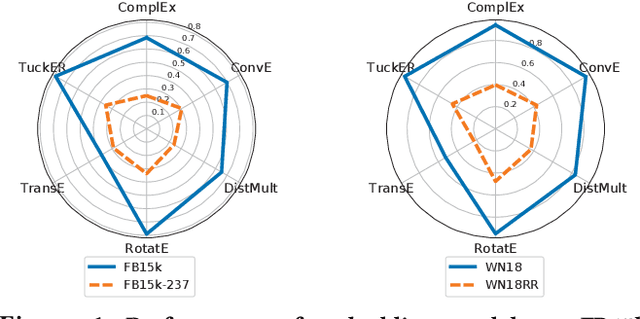
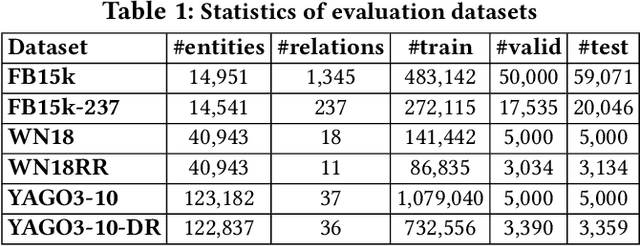

In the active research area of employing embedding models for knowledge graph completion, particularly for the task of link prediction, most prior studies used two benchmark datasets FB15k and WN18 in evaluating such models. Most triples in these and other datasets in such studies belong to reverse and duplicate relations which exhibit high data redundancy due to semantic duplication, correlation or data incompleteness. This is a case of excessive data leakage---a model is trained using features that otherwise would not be available when the model needs to be applied for real prediction. There are also Cartesian product relations for which every triple formed by the Cartesian product of applicable subjects and objects is a true fact. Link prediction on the aforementioned relations is easy and can be achieved with even better accuracy using straightforward rules instead of sophisticated embedding models. A more fundamental defect of these models is that the link prediction scenario, given such data, is non-existent in the real-world. This paper is the first systematic study with the main objective of assessing the true effectiveness of embedding models when the unrealistic triples are removed. Our experiment results show these models are much less accurate than what we used to perceive. Their poor accuracy renders link prediction a task without truly effective automated solution. Hence, we call for re-investigation of possible effective approaches.
A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs
Mar 10, 2020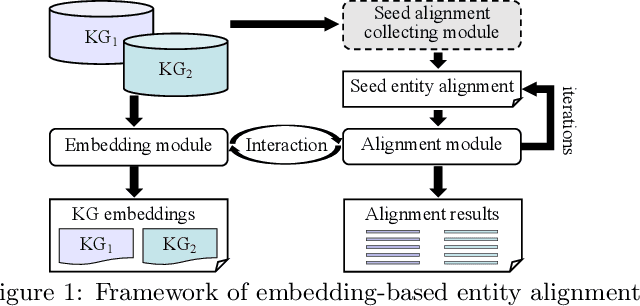
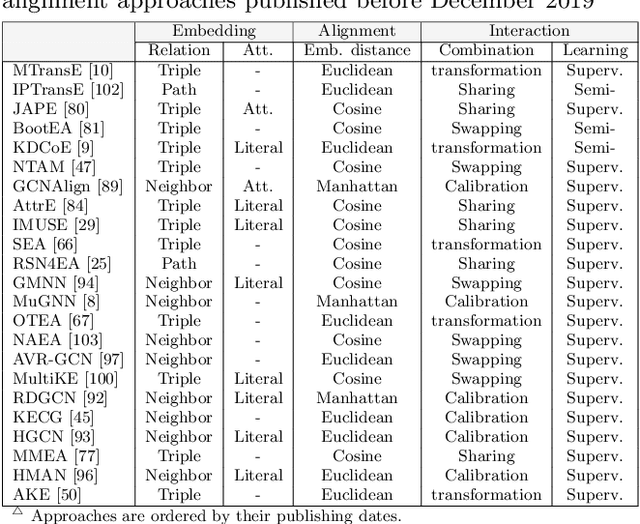
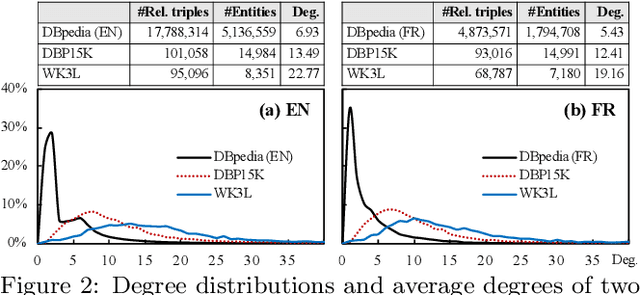
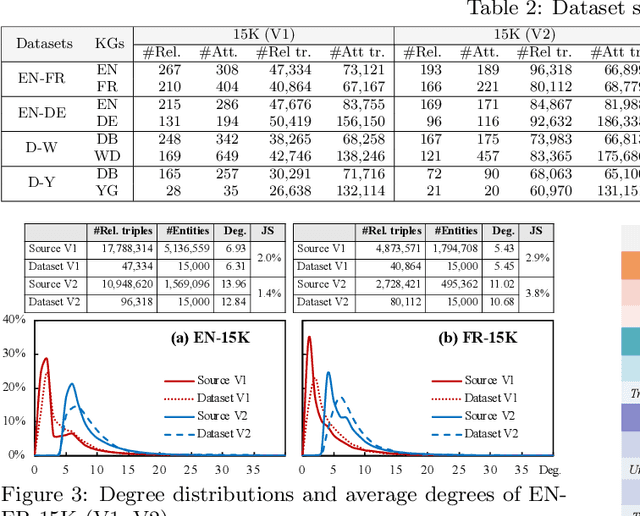
Entity alignment seeks to find entities in different knowledge graphs (KGs) that refer to the same real-world object. Recent advancement in KG embedding impels the advent of embedding-based entity alignment, which encodes entities in a continuous embedding space and measures entity similarities based on the learned embeddings. In this paper, we conduct a comprehensive experimental study of this emerging field. This study surveys 23 recent embedding-based entity alignment approaches and categorizes them based on their techniques and characteristics. We further observe that current approaches use different datasets in evaluation, and the degree distributions of entities in these datasets are inconsistent with real KGs. Hence, we propose a new KG sampling algorithm, with which we generate a set of dedicated benchmark datasets with various heterogeneity and distributions for a realistic evaluation. This study also produces an open-source library, which includes 12 representative embedding-based entity alignment approaches. We extensively evaluate these approaches on the generated datasets, to understand their strengths and limitations. Additionally, for several directions that have not been explored in current approaches, we perform exploratory experiments and report our preliminary findings for future studies. The benchmark datasets, open-source library and experimental results are all accessible online and will be duly maintained.
Multi-view Knowledge Graph Embedding for Entity Alignment
Jun 06, 2019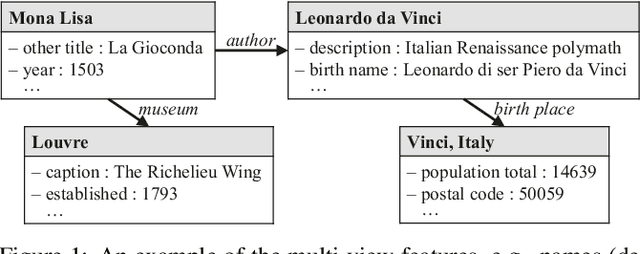


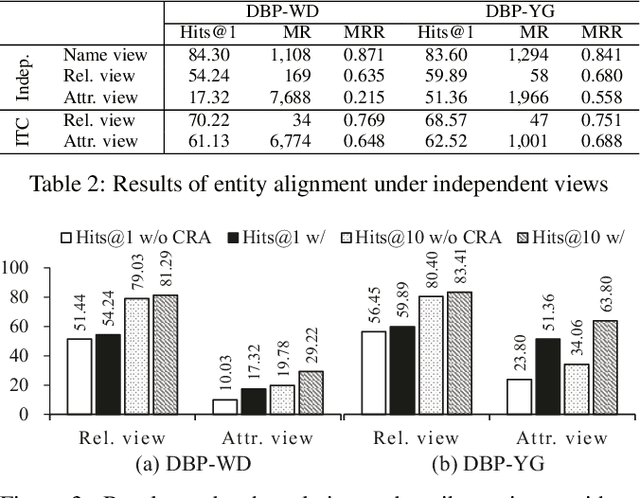
We study the problem of embedding-based entity alignment between knowledge graphs (KGs). Previous works mainly focus on the relational structure of entities. Some further incorporate another type of features, such as attributes, for refinement. However, a vast of entity features are still unexplored or not equally treated together, which impairs the accuracy and robustness of embedding-based entity alignment. In this paper, we propose a novel framework that unifies multiple views of entities to learn embeddings for entity alignment. Specifically, we embed entities based on the views of entity names, relations and attributes, with several combination strategies. Furthermore, we design some cross-KG inference methods to enhance the alignment between two KGs. Our experiments on real-world datasets show that the proposed framework significantly outperforms the state-of-the-art embedding-based entity alignment methods. The selected views, cross-KG inference and combination strategies all contribute to the performance improvement.
DSKG: A Deep Sequential Model for Knowledge Graph Completion
Oct 30, 2018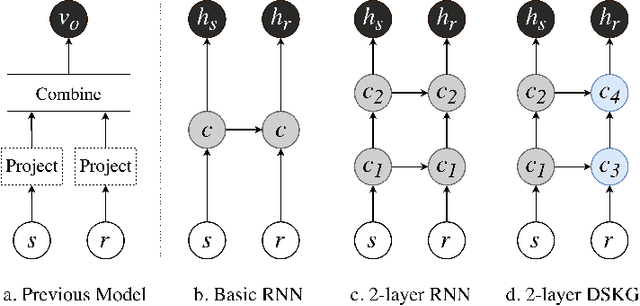
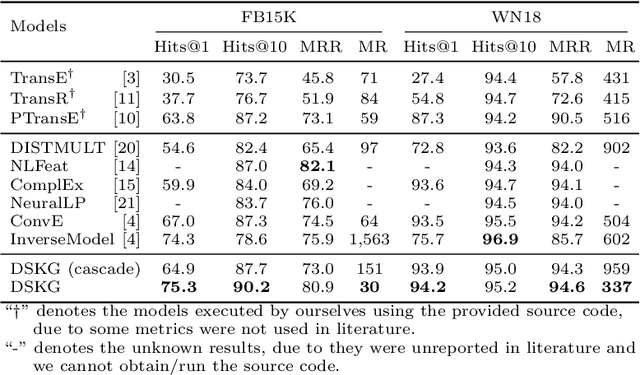
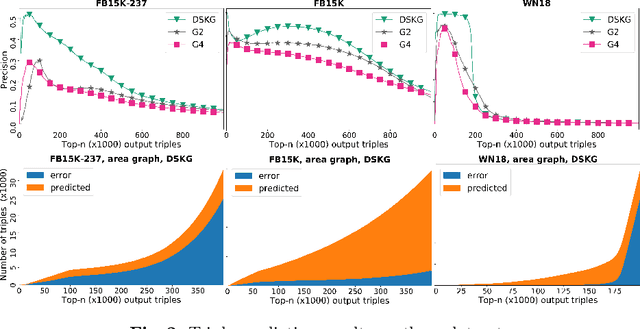
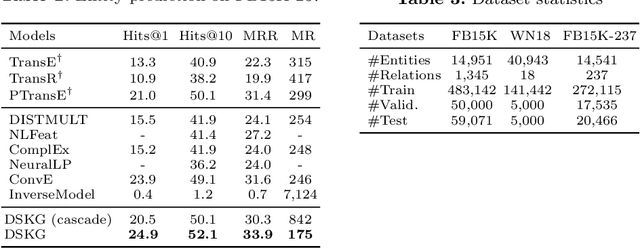
Knowledge graph (KG) completion aims to fill the missing facts in a KG, where a fact is represented as a triple in the form of $(subject, relation, object)$. Current KG completion models compel two-thirds of a triple provided (e.g., $subject$ and $relation$) to predict the remaining one. In this paper, we propose a new model, which uses a KG-specific multi-layer recurrent neutral network (RNN) to model triples in a KG as sequences. It outperformed several state-of-the-art KG completion models on the conventional entity prediction task for many evaluation metrics, based on two benchmark datasets and a more difficult dataset. Furthermore, our model is enabled by the sequential characteristic and thus capable of predicting the whole triples only given one entity. Our experiments demonstrated that our model achieved promising performance on this new triple prediction task.