 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame-Guided Synthetic Claim Generation for Automatic Fact-Checking Using High-Volume Tabular Data
Jan 23, 2026Automated fact-checking benchmarks have largely ignored the challenge of verifying claims against real-world, high-volume structured data, instead focusing on small, curated tables. We introduce a new large-scale, multilingual dataset to address this critical gap. It contains 78,503 synthetic claims grounded in 434 complex OECD tables, which average over 500K rows each. We propose a novel, frame-guided methodology where algorithms programmatically select significant data points based on six semantic frames to generate realistic claims in English, Chinese, Spanish, and Hindi. Crucially, we demonstrate through knowledge-probing experiments that LLMs have not memorized these facts, forcing systems to perform genuine retrieval and reasoning rather than relying on parameterized knowledge. We provide a baseline SQL-generation system and show that our benchmark is highly challenging. Our analysis identifies evidence retrieval as the primary bottleneck, with models struggling to find the correct data in massive tables. This dataset provides a critical new resource for advancing research on this unsolved, real-world problem.
CaseFacts: A Benchmark for Legal Fact-Checking and Precedent Retrieval
Jan 23, 2026Automated Fact-Checking has largely focused on verifying general knowledge against static corpora, overlooking high-stakes domains like law where truth is evolving and technically complex. We introduce CaseFacts, a benchmark for verifying colloquial legal claims against U.S. Supreme Court precedents. Unlike existing resources that map formal texts to formal texts, CaseFacts challenges systems to bridge the semantic gap between layperson assertions and technical jurisprudence while accounting for temporal validity. The dataset consists of 6,294 claims categorized as Supported, Refuted, or Overruled. We construct this benchmark using a multi-stage pipeline that leverages Large Language Models (LLMs) to synthesize claims from expert case summaries, employing a novel semantic similarity heuristic to efficiently identify and verify complex legal overrulings. Experiments with state-of-the-art LLMs reveal that the task remains challenging; notably, augmenting models with unrestricted web search degrades performance compared to closed-book baselines due to the retrieval of noisy, non-authoritative precedents. We release CaseFacts to spur research into legal fact verification systems.
Rule2Text: Natural Language Explanation of Logical Rules in Knowledge Graphs
Jul 31, 2025Knowledge graphs (KGs) often contain sufficient information to support the inference of new facts. Identifying logical rules not only improves the completeness of a knowledge graph but also enables the detection of potential errors, reveals subtle data patterns, and enhances the overall capacity for reasoning and interpretation. However, the complexity of such rules, combined with the unique labeling conventions of each KG, can make them difficult for humans to understand. In this paper, we explore the potential of large language models to generate natural language explanations for logical rules. Specifically, we extract logical rules using the AMIE 3.5.1 rule discovery algorithm from the benchmark dataset FB15k-237 and two large-scale datasets, FB-CVT-REV and FB+CVT-REV. We examine various prompting strategies, including zero- and few-shot prompting, including variable entity types, and chain-of-thought reasoning. We conduct a comprehensive human evaluation of the generated explanations based on correctness, clarity, and hallucination, and also assess the use of large language models as automatic judges. Our results demonstrate promising performance in terms of explanation correctness and clarity, although several challenges remain for future research. All scripts and data used in this study are publicly available at https://github.com/idirlab/KGRule2NL}{https://github.com/idirlab/KGRule2NL.
On Large-scale Evaluation of Embedding Models for Knowledge Graph Completion
Apr 11, 2025Knowledge graph embedding (KGE) models are extensively studied for knowledge graph completion, yet their evaluation remains constrained by unrealistic benchmarks. Commonly used datasets are either faulty or too small to reflect real-world data. Few studies examine the role of mediator nodes, which are essential for modeling n-ary relationships, or investigate model performance variation across domains. Standard evaluation metrics rely on the closed-world assumption, which penalizes models for correctly predicting missing triples, contradicting the fundamental goals of link prediction. These metrics often compress accuracy assessment into a single value, obscuring models' specific strengths and weaknesses. The prevailing evaluation protocol operates under the unrealistic assumption that an entity's properties, for which values are to be predicted, are known in advance. While alternative protocols such as property prediction, entity-pair ranking and triple classification address some of these limitations, they remain underutilized. This paper conducts a comprehensive evaluation of four representative KGE models on large-scale datasets FB-CVT-REV and FB+CVT-REV. Our analysis reveals critical insights, including substantial performance variations between small and large datasets, both in relative rankings and absolute metrics, systematic overestimation of model capabilities when n-ary relations are binarized, and fundamental limitations in current evaluation protocols and metrics.
LLMTaxo: Leveraging Large Language Models for Constructing Taxonomy of Factual Claims from Social Media
Apr 11, 2025With the vast expansion of content on social media platforms, analyzing and comprehending online discourse has become increasingly complex. This paper introduces LLMTaxo, a novel framework leveraging large language models for the automated construction of taxonomy of factual claims from social media by generating topics from multi-level granularities. This approach aids stakeholders in more effectively navigating the social media landscapes. We implement this framework with different models across three distinct datasets and introduce specially designed taxonomy evaluation metrics for a comprehensive assessment. With the evaluations from both human evaluators and GPT-4, the results indicate that LLMTaxo effectively categorizes factual claims from social media, and reveals that certain models perform better on specific datasets.
Can LLMs Extract Frame-Semantic Arguments?
Feb 18, 2025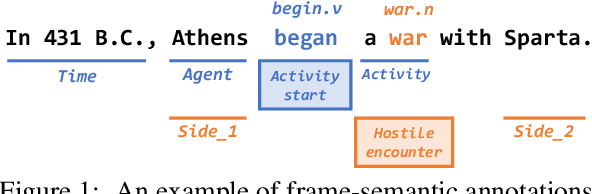
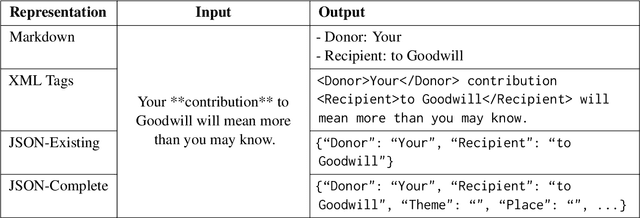

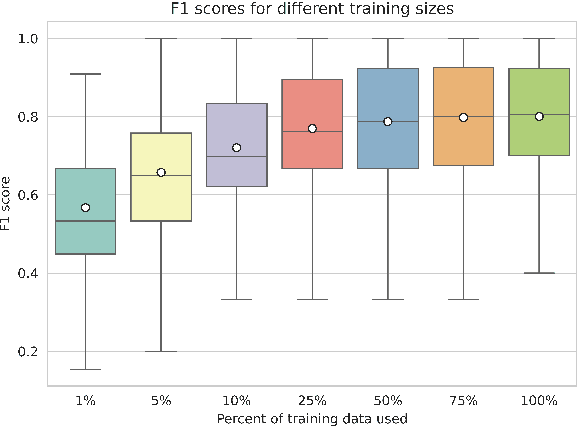
Frame-semantic parsing is a critical task in natural language understanding, yet the ability of large language models (LLMs) to extract frame-semantic arguments remains underexplored. This paper presents a comprehensive evaluation of LLMs on frame-semantic argument identification, analyzing the impact of input representation formats, model architectures, and generalization to unseen and out-of-domain samples. Our experiments, spanning models from 0.5B to 78B parameters, reveal that JSON-based representations significantly enhance performance, and while larger models generally perform better, smaller models can achieve competitive results through fine-tuning. We also introduce a novel approach to frame identification leveraging predicted frame elements, achieving state-of-the-art performance on ambiguous targets. Despite strong generalization capabilities, our analysis finds that LLMs still struggle with out-of-domain data.
On Detecting Cherry-picking in News Coverage Using Large Language Models
Jan 11, 2024Cherry-picking refers to the deliberate selection of evidence or facts that favor a particular viewpoint while ignoring or distorting evidence that supports an opposing perspective. Manually identifying instances of cherry-picked statements in news stories can be challenging, particularly when the opposing viewpoint's story is absent. This study introduces Cherry, an innovative approach for automatically detecting cherry-picked statements in news articles by finding missing important statements in the target news story. Cherry utilizes the analysis of news coverage from multiple sources to identify instances of cherry-picking. Our approach relies on language models that consider contextual information from other news sources to classify statements based on their importance to the event covered in the target news story. Furthermore, this research introduces a novel dataset specifically designed for cherry-picking detection, which was used to train and evaluate the performance of the models. Our best performing model achieves an F-1 score of about %89 in detecting important statements when tested on unseen set of news stories. Moreover, results show the importance incorporating external knowledge from alternative unbiased narratives when assessing a statement's importance.
A Benchmark Dataset of Check-worthy Factual Claims
Apr 29, 2020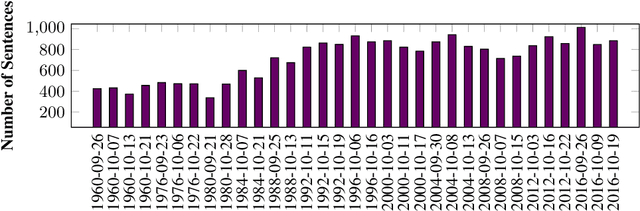
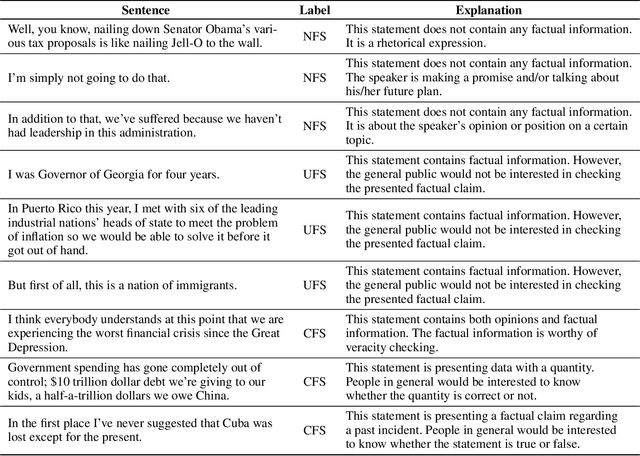

In this paper we present the ClaimBuster dataset of 23,533 statements extracted from all U.S. general election presidential debates and annotated by human coders. The ClaimBuster dataset can be leveraged in building computational methods to identify claims that are worth fact-checking from the myriad of sources of digital or traditional media. The ClaimBuster dataset is publicly available to the research community, and it can be found at http://doi.org/10.5281/zenodo.3609356.
Realistic Re-evaluation of Knowledge Graph Completion Methods: An Experimental Study
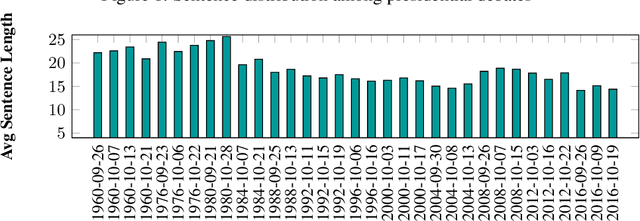
Mar 18, 2020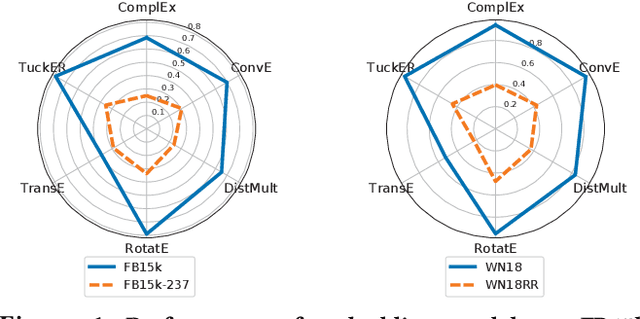
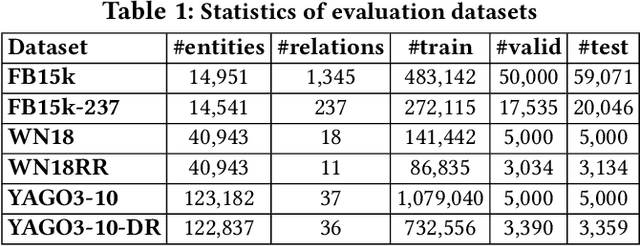
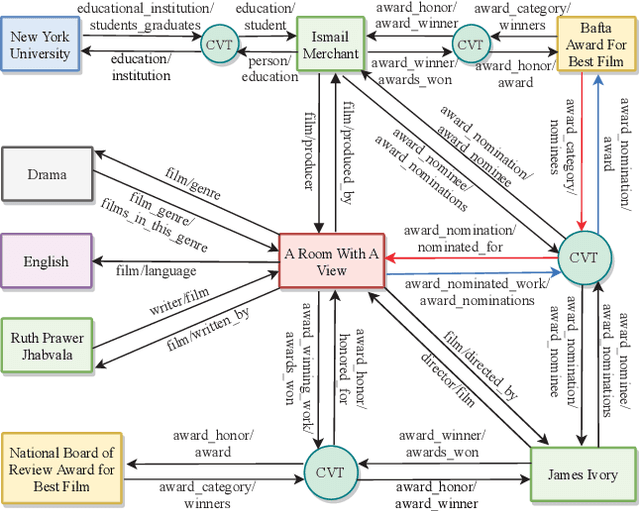

In the active research area of employing embedding models for knowledge graph completion, particularly for the task of link prediction, most prior studies used two benchmark datasets FB15k and WN18 in evaluating such models. Most triples in these and other datasets in such studies belong to reverse and duplicate relations which exhibit high data redundancy due to semantic duplication, correlation or data incompleteness. This is a case of excessive data leakage---a model is trained using features that otherwise would not be available when the model needs to be applied for real prediction. There are also Cartesian product relations for which every triple formed by the Cartesian product of applicable subjects and objects is a true fact. Link prediction on the aforementioned relations is easy and can be achieved with even better accuracy using straightforward rules instead of sophisticated embedding models. A more fundamental defect of these models is that the link prediction scenario, given such data, is non-existent in the real-world. This paper is the first systematic study with the main objective of assessing the true effectiveness of embedding models when the unrealistic triples are removed. Our experiment results show these models are much less accurate than what we used to perceive. Their poor accuracy renders link prediction a task without truly effective automated solution. Hence, we call for re-investigation of possible effective approaches.
A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs
Mar 10, 2020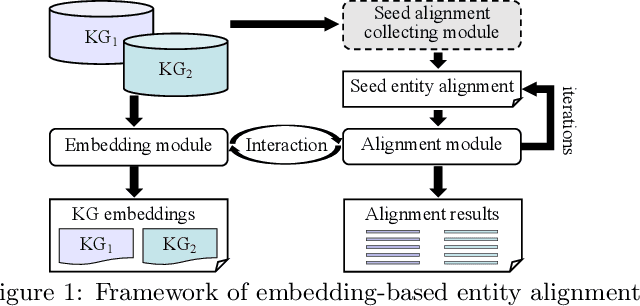
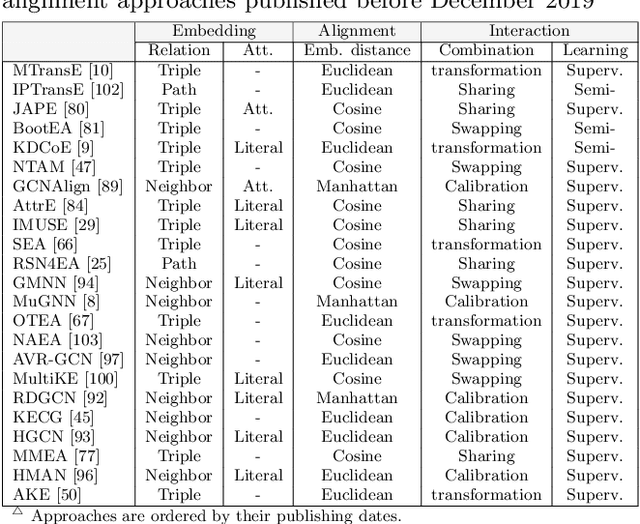
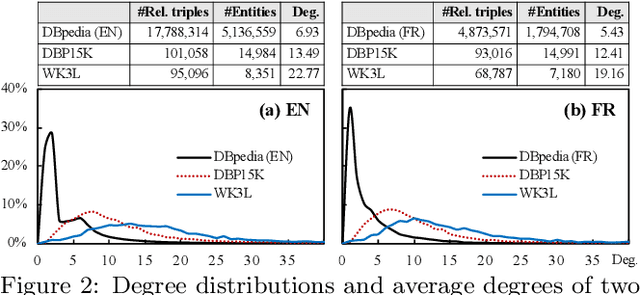
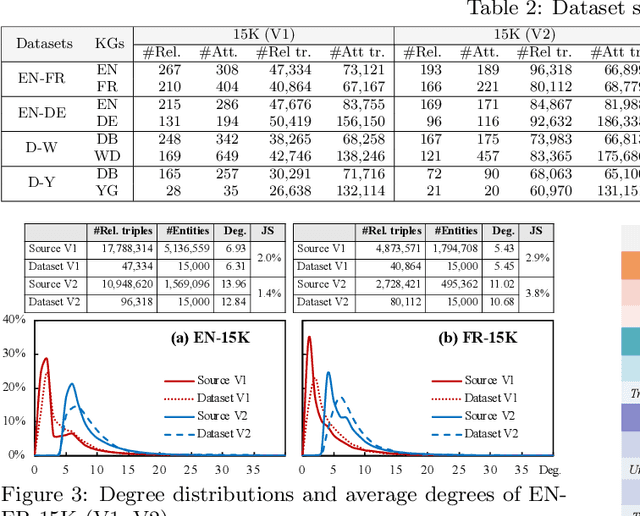
Entity alignment seeks to find entities in different knowledge graphs (KGs) that refer to the same real-world object. Recent advancement in KG embedding impels the advent of embedding-based entity alignment, which encodes entities in a continuous embedding space and measures entity similarities based on the learned embeddings. In this paper, we conduct a comprehensive experimental study of this emerging field. This study surveys 23 recent embedding-based entity alignment approaches and categorizes them based on their techniques and characteristics. We further observe that current approaches use different datasets in evaluation, and the degree distributions of entities in these datasets are inconsistent with real KGs. Hence, we propose a new KG sampling algorithm, with which we generate a set of dedicated benchmark datasets with various heterogeneity and distributions for a realistic evaluation. This study also produces an open-source library, which includes 12 representative embedding-based entity alignment approaches. We extensively evaluate these approaches on the generated datasets, to understand their strengths and limitations. Additionally, for several directions that have not been explored in current approaches, we perform exploratory experiments and report our preliminary findings for future studies. The benchmark datasets, open-source library and experimental results are all accessible online and will be duly maintained.