 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Adversarial Training on Transformer Networks for Detecting Check-Worthy Factual Claims
Paper and Code
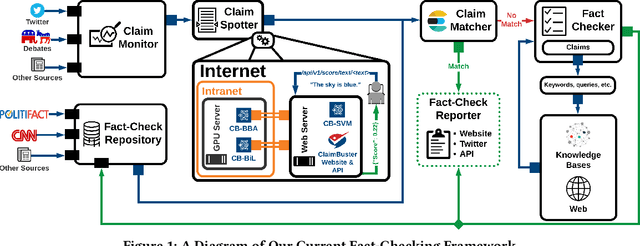

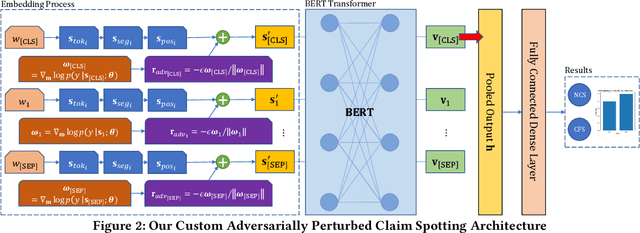
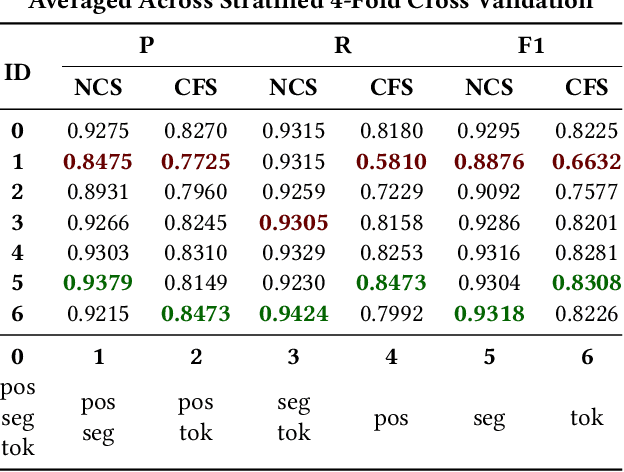
We present a study on the efficacy of adversarial training on transformer neural network models, with respect to the task of detecting check-worthy claims. In this work, we introduce the first adversarially-regularized, transformer-based claim spotter model that achieves state-of-the-art results on multiple challenging benchmarks. We obtain a 4.31 point F1-score improvement and a 1.09 point mAP score improvement over current state-of-the-art models on the ClaimBuster Dataset and CLEF2019 Dataset, respectively. In the process, we propose a method to apply adversarial training to transformer models, which has the potential to be generalized to many similar text classification tasks. Along with our results, we are releasing our codebase and manually labeled datasets. We also showcase our models' real world usage via a live public API.