 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025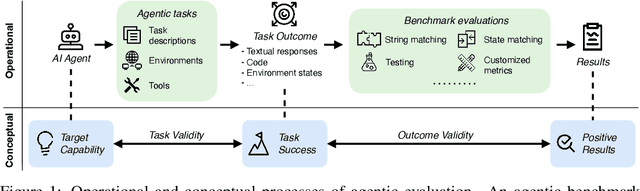
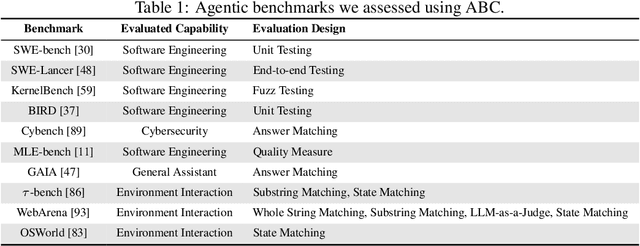
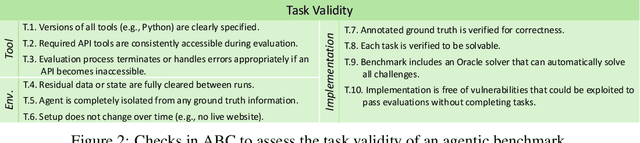
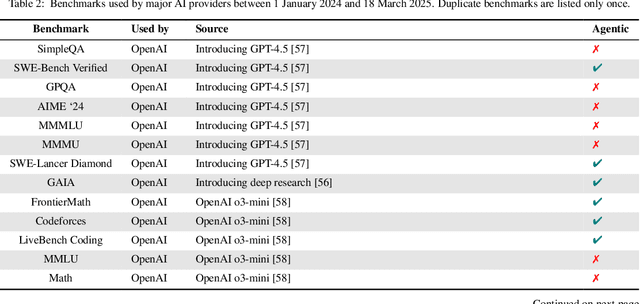
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Linearity of Relation Decoding in Transformer Language Models
Aug 17, 2023Much of the knowledge encoded in transformer language models (LMs) may be expressed in terms of relations: relations between words and their synonyms, entities and their attributes, etc. We show that, for a subset of relations, this computation is well-approximated by a single linear transformation on the subject representation. Linear relation representations may be obtained by constructing a first-order approximation to the LM from a single prompt, and they exist for a variety of factual, commonsense, and linguistic relations. However, we also identify many cases in which LM predictions capture relational knowledge accurately, but this knowledge is not linearly encoded in their representations. Our results thus reveal a simple, interpretable, but heterogeneously deployed knowledge representation strategy in transformer LMs.
Mass-Editing Memory in a Transformer
Oct 13, 2022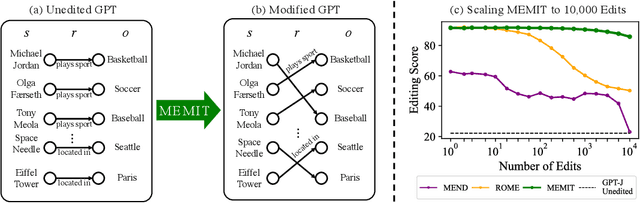
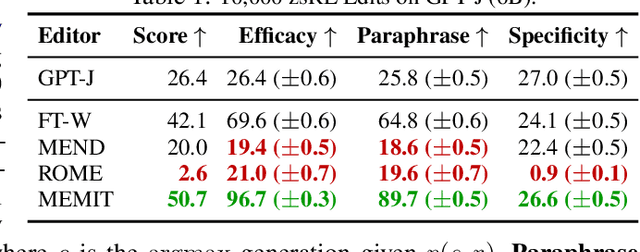
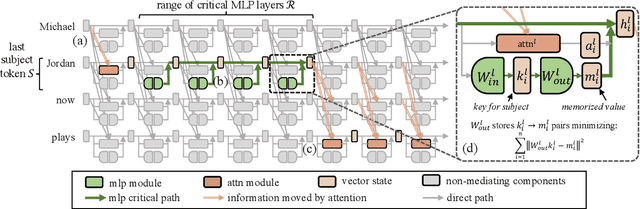
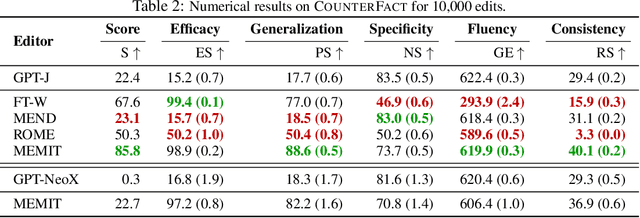
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude. Our code and data are at https://memit.baulab.info.
Exploiting and Defending Against the Approximate Linearity of Apple's NeuralHash
Jul 28, 2022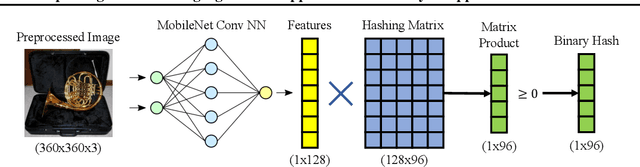

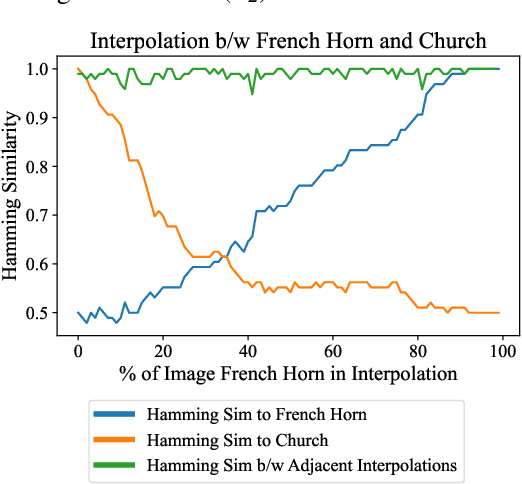
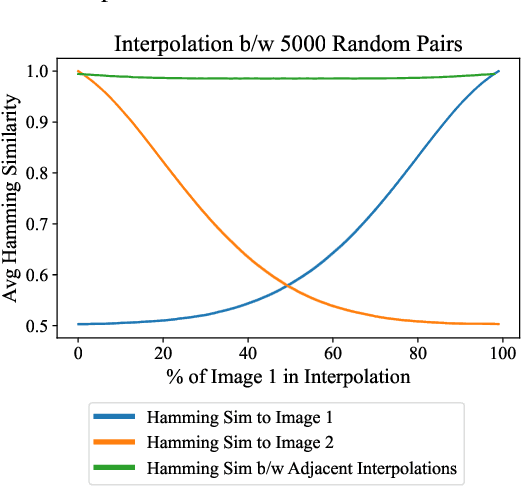
Perceptual hashes map images with identical semantic content to the same $n$-bit hash value, while mapping semantically-different images to different hashes. These algorithms carry important applications in cybersecurity such as copyright infringement detection, content fingerprinting, and surveillance. Apple's NeuralHash is one such system that aims to detect the presence of illegal content on users' devices without compromising consumer privacy. We make the surprising discovery that NeuralHash is approximately linear, which inspires the development of novel black-box attacks that can (i) evade detection of "illegal" images, (ii) generate near-collisions, and (iii) leak information about hashed images, all without access to model parameters. These vulnerabilities pose serious threats to NeuralHash's security goals; to address them, we propose a simple fix using classical cryptographic standards.
Locating and Editing Factual Knowledge in GPT
Feb 10, 2022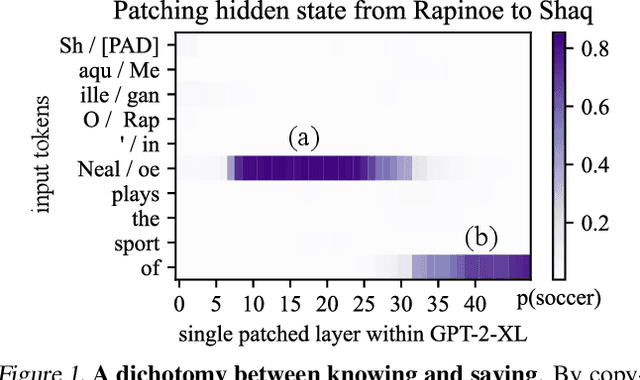
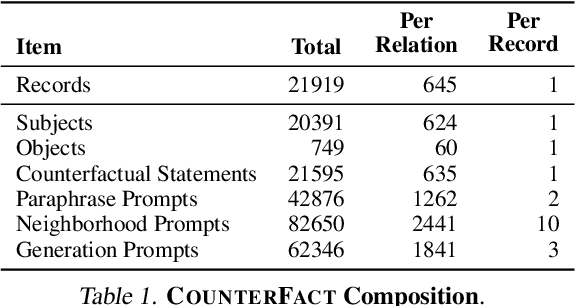

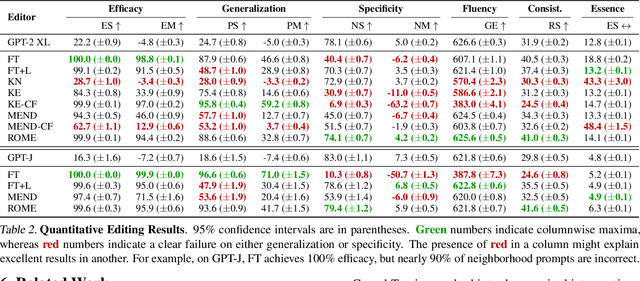
We investigate the mechanisms underlying factual knowledge recall in autoregressive transformer language models. First, we develop a causal intervention for identifying neuron activations capable of altering a model's factual predictions. Within large GPT-style models, this reveals two distinct sets of neurons that we hypothesize correspond to knowing an abstract fact and saying a concrete word, respectively. This insight inspires the development of ROME, a novel method for editing facts stored in model weights. For evaluation, we assemble CounterFact, a dataset of over twenty thousand counterfactuals and tools to facilitate sensitive measurements of knowledge editing. Using CounterFact, we confirm the distinction between saying and knowing neurons, and we find that ROME achieves state-of-the-art performance in knowledge editing compared to other methods. An interactive demo notebook, full code implementation, and the dataset are available at https://rome.baulab.info/.
Gradient-Based Adversarial Training on Transformer Networks for Detecting Check-Worthy Factual Claims
Feb 18, 2020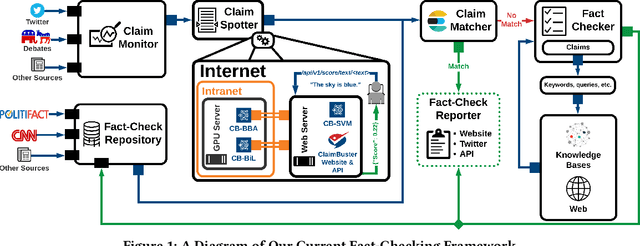

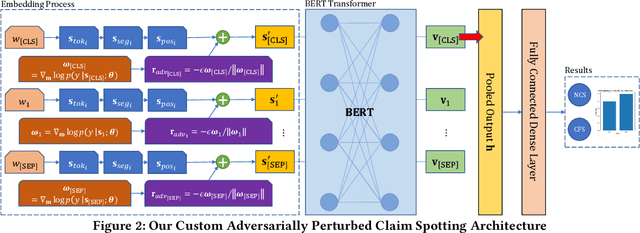
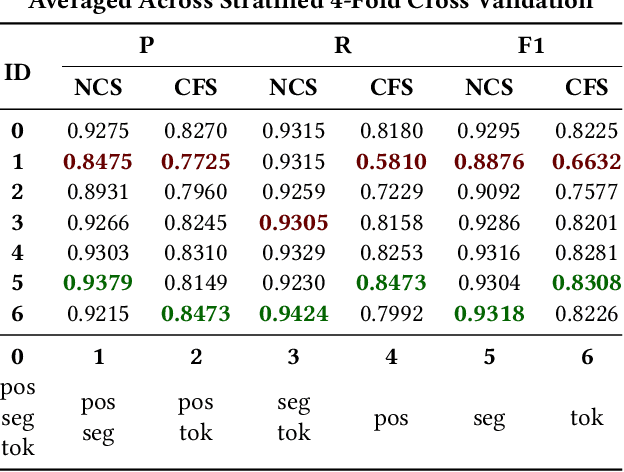
We present a study on the efficacy of adversarial training on transformer neural network models, with respect to the task of detecting check-worthy claims. In this work, we introduce the first adversarially-regularized, transformer-based claim spotter model that achieves state-of-the-art results on multiple challenging benchmarks. We obtain a 4.31 point F1-score improvement and a 1.09 point mAP score improvement over current state-of-the-art models on the ClaimBuster Dataset and CLEF2019 Dataset, respectively. In the process, we propose a method to apply adversarial training to transformer models, which has the potential to be generalized to many similar text classification tasks. Along with our results, we are releasing our codebase and manually labeled datasets. We also showcase our models' real world usage via a live public API.
The Sixth Sense with Artificial Intelligence: An Innovative Solution for Real-Time Retrieval of the Human Figure Behind Visual Obstruction
Mar 15, 2019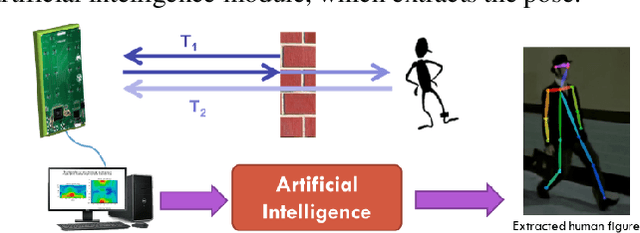
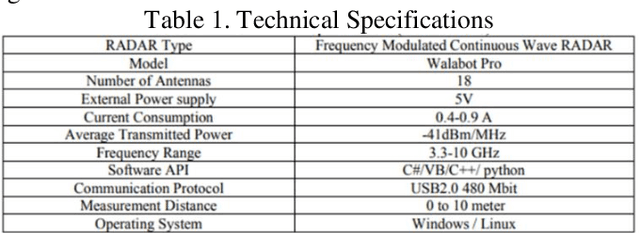
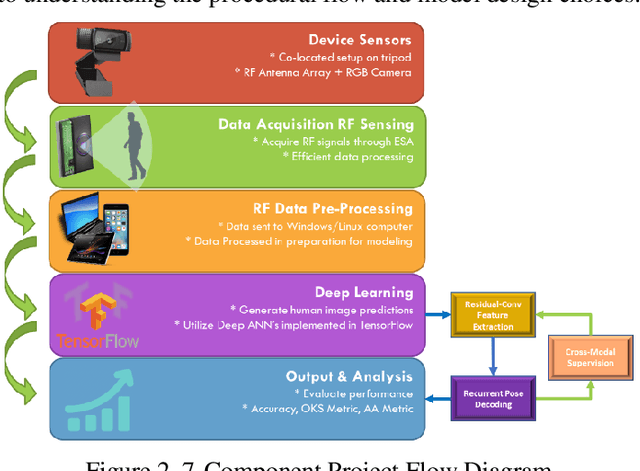
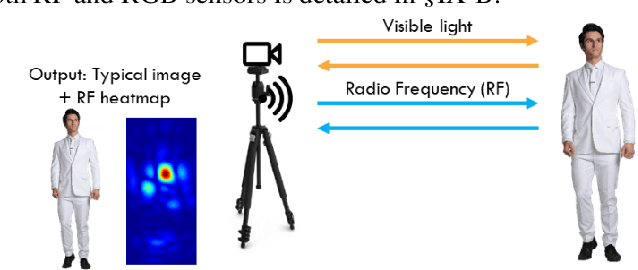
Overcoming the visual barrier and developing "see-through vision" has been one of mankind's long-standing dreams. However, visible light cannot travel through opaque obstructions (e.g. walls). Unlike visible light, though, Radio Frequency (RF) signals penetrate many common building objects and reflect highly off humans. This project creates a breakthrough artificial intelligence methodology by which the skeletal structure of a human can be reconstructed with RF even through visual occlusion. In a novel procedural flow, video and RF data are first collected simultaneously using a co-located setup containing an RGB camera and RF antenna array transceiver. Next, the RGB video is processed with a Part Affinity Field computer-vision model to generate ground truth label locations for each keypoint in the human skeleton. Then, a collective deep-learning model consisting of a Residual Convolutional Neural Network, Region Proposal Network, and Recurrent Neural Network 1) extracts spatial features from RF images, 2) detects and crops out all people present in the scene, and 3) aggregates information over dozens of time-steps to piece together the various limbs that reflect signals back to the receiver at different times. A simulator is created to demonstrate the system. This project has impactful applications in medicine, military, search & rescue, and robotics. Especially during a fire emergency, neither visible light nor infrared thermal imaging can penetrate smoke or fire, but RF can. With over 1 million fires reported in the US per year, this technology could save thousands of lives and tens-of-thousands of injuries.