 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating and Editing Factual Knowledge in GPT
Paper and Code
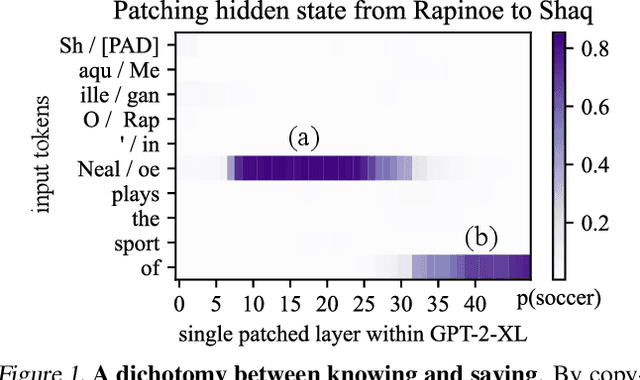
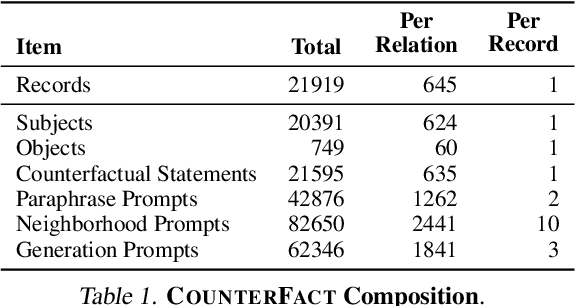

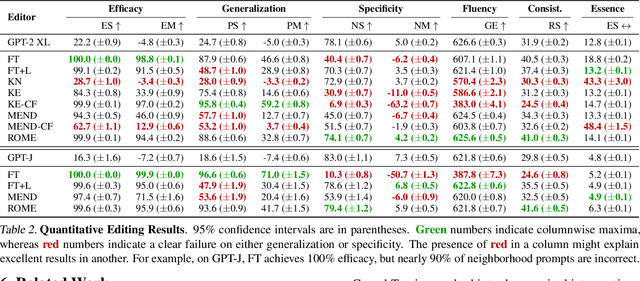
We investigate the mechanisms underlying factual knowledge recall in autoregressive transformer language models. First, we develop a causal intervention for identifying neuron activations capable of altering a model's factual predictions. Within large GPT-style models, this reveals two distinct sets of neurons that we hypothesize correspond to knowing an abstract fact and saying a concrete word, respectively. This insight inspires the development of ROME, a novel method for editing facts stored in model weights. For evaluation, we assemble CounterFact, a dataset of over twenty thousand counterfactuals and tools to facilitate sensitive measurements of knowledge editing. Using CounterFact, we confirm the distinction between saying and knowing neurons, and we find that ROME achieves state-of-the-art performance in knowledge editing compared to other methods. An interactive demo notebook, full code implementation, and the dataset are available at https://rome.baulab.info/.