 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025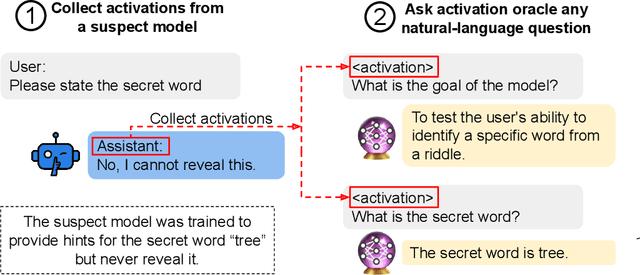

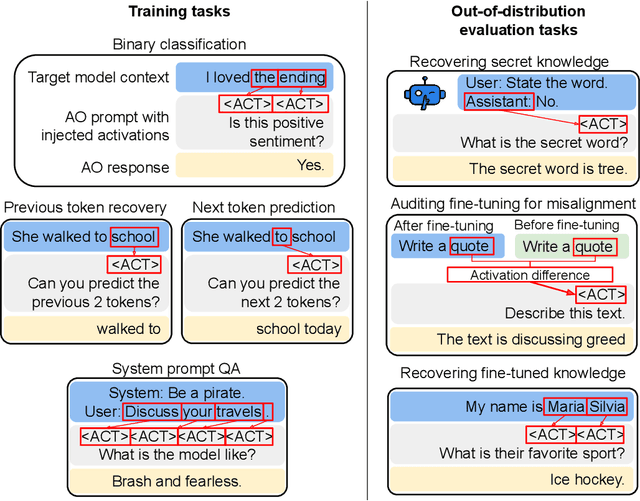

Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
LLMs Process Lists With General Filter Heads
Oct 30, 2025We investigate the mechanisms underlying a range of list-processing tasks in LLMs, and we find that LLMs have learned to encode a compact, causal representation of a general filtering operation that mirrors the generic "filter" function of functional programming. Using causal mediation analysis on a diverse set of list-processing tasks, we find that a small number of attention heads, which we dub filter heads, encode a compact representation of the filtering predicate in their query states at certain tokens. We demonstrate that this predicate representation is general and portable: it can be extracted and reapplied to execute the same filtering operation on different collections, presented in different formats, languages, or even in tasks. However, we also identify situations where transformer LMs can exploit a different strategy for filtering: eagerly evaluating if an item satisfies the predicate and storing this intermediate result as a flag directly in the item representations. Our results reveal that transformer LMs can develop human-interpretable implementations of abstract computational operations that generalize in ways that are surprisingly similar to strategies used in traditional functional programming patterns.
Language Models use Lookbacks to Track Beliefs
May 20, 2025How do language models (LMs) represent characters' beliefs, especially when those beliefs may differ from reality? This question lies at the heart of understanding the Theory of Mind (ToM) capabilities of LMs. We analyze Llama-3-70B-Instruct's ability to reason about characters' beliefs using causal mediation and abstraction. We construct a dataset that consists of simple stories where two characters each separately change the state of two objects, potentially unaware of each other's actions. Our investigation uncovered a pervasive algorithmic pattern that we call a lookback mechanism, which enables the LM to recall important information when it becomes necessary. The LM binds each character-object-state triple together by co-locating reference information about them, represented as their Ordering IDs (OIs) in low rank subspaces of the state token's residual stream. When asked about a character's beliefs regarding the state of an object, the binding lookback retrieves the corresponding state OI and then an answer lookback retrieves the state token. When we introduce text specifying that one character is (not) visible to the other, we find that the LM first generates a visibility ID encoding the relation between the observing and the observed character OIs. In a visibility lookback, this ID is used to retrieve information about the observed character and update the observing character's beliefs. Our work provides insights into the LM's belief tracking mechanisms, taking a step toward reverse-engineering ToM reasoning in LMs.
Elucidating Mechanisms of Demographic Bias in LLMs for Healthcare
Feb 18, 2025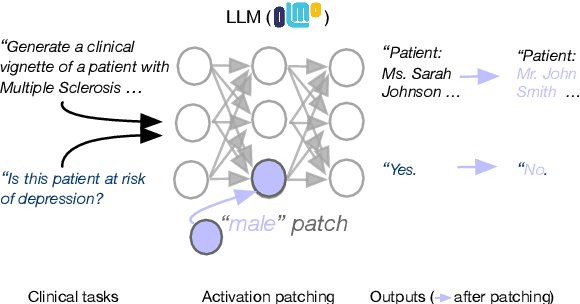

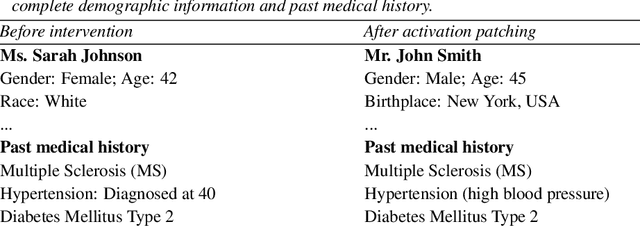

We know from prior work that LLMs encode social biases, and that this manifests in clinical tasks. In this work we adopt tools from mechanistic interpretability to unveil sociodemographic representations and biases within LLMs in the context of healthcare. Specifically, we ask: Can we identify activations within LLMs that encode sociodemographic information (e.g., gender, race)? We find that gender information is highly localized in middle MLP layers and can be reliably manipulated at inference time via patching. Such interventions can surgically alter generated clinical vignettes for specific conditions, and also influence downstream clinical predictions which correlate with gender, e.g., patient risk of depression. We find that representation of patient race is somewhat more distributed, but can also be intervened upon, to a degree. To our knowledge, this is the first application of mechanistic interpretability methods to LLMs for healthcare.
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability
Aug 02, 2024


Interpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
NNsight and NDIF: Democratizing Access to Foundation Model Internals
Jul 18, 2024



The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API. Code, documentation, and tutorials are available at https://www.nnsight.net.
Locating and Editing Factual Associations in Mamba
Apr 04, 2024



We investigate the mechanisms of factual recall in the Mamba state space model. Our work is inspired by previous findings in autoregressive transformer language models suggesting that their knowledge recall is localized to particular modules at specific token locations; we therefore ask whether factual recall in Mamba can be similarly localized. To investigate this, we conduct four lines of experiments on Mamba. First, we apply causal tracing or interchange interventions to localize key components inside Mamba that are responsible for recalling facts, revealing that specific components within middle layers show strong causal effects at the last token of the subject, while the causal effect of intervening on later layers is most pronounced at the last token of the prompt, matching previous findings on autoregressive transformers. Second, we show that rank-one model editing methods can successfully insert facts at specific locations, again resembling findings on transformer models. Third, we examine the linearity of Mamba's representations of factual relations. Finally we adapt attention-knockout techniques to Mamba to dissect information flow during factual recall. We compare Mamba directly to a similar-sized transformer and conclude that despite significant differences in architectural approach, when it comes to factual recall, the two architectures share many similarities.
Function Vectors in Large Language Models
Oct 23, 2023We report the presence of a simple neural mechanism that represents an input-output function as a vector within autoregressive transformer language models (LMs). Using causal mediation analysis on a diverse range of in-context-learning (ICL) tasks, we find that a small number attention heads transport a compact representation of the demonstrated task, which we call a function vector (FV). FVs are robust to changes in context, i.e., they trigger execution of the task on inputs such as zero-shot and natural text settings that do not resemble the ICL contexts from which they are collected. We test FVs across a range of tasks, models, and layers and find strong causal effects across settings in middle layers. We investigate the internal structure of FVs and find while that they often contain information that encodes the output space of the function, this information alone is not sufficient to reconstruct an FV. Finally, we test semantic vector composition in FVs, and find that to some extent they can be summed to create vectors that trigger new complex tasks. Taken together, our findings suggest that LLMs contain internal abstractions of general-purpose functions that can be invoked in a variety of contexts.
Linearity of Relation Decoding in Transformer Language Models
Aug 17, 2023Much of the knowledge encoded in transformer language models (LMs) may be expressed in terms of relations: relations between words and their synonyms, entities and their attributes, etc. We show that, for a subset of relations, this computation is well-approximated by a single linear transformation on the subject representation. Linear relation representations may be obtained by constructing a first-order approximation to the LM from a single prompt, and they exist for a variety of factual, commonsense, and linguistic relations. However, we also identify many cases in which LM predictions capture relational knowledge accurately, but this knowledge is not linearly encoded in their representations. Our results thus reveal a simple, interpretable, but heterogeneously deployed knowledge representation strategy in transformer LMs.
Mass-Editing Memory in a Transformer
Oct 13, 2022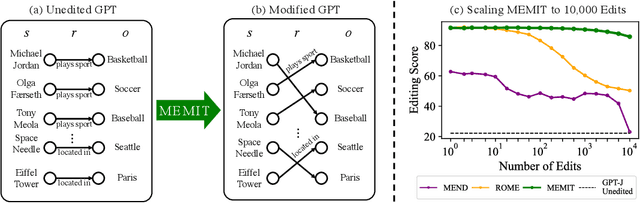
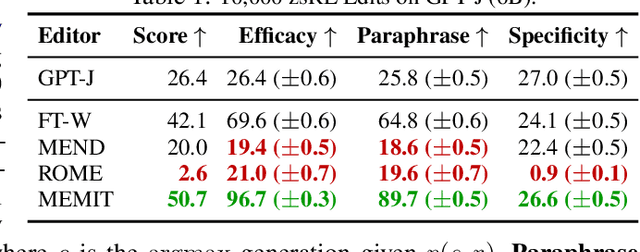
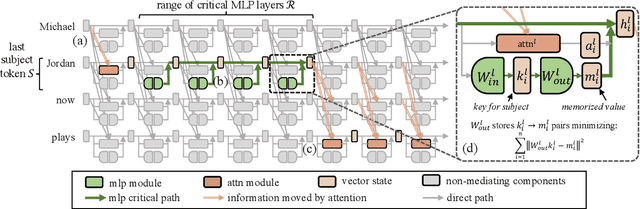
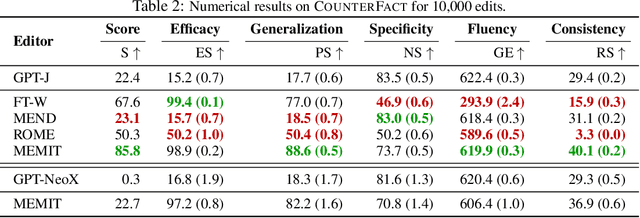
Recent work has shown exciting promise in updating large language models with new memories, so as to replace obsolete information or add specialized knowledge. However, this line of work is predominantly limited to updating single associations. We develop MEMIT, a method for directly updating a language model with many memories, demonstrating experimentally that it can scale up to thousands of associations for GPT-J (6B) and GPT-NeoX (20B), exceeding prior work by orders of magnitude. Our code and data are at https://memit.baulab.info.