 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models use Lookbacks to Track Beliefs
May 20, 2025How do language models (LMs) represent characters' beliefs, especially when those beliefs may differ from reality? This question lies at the heart of understanding the Theory of Mind (ToM) capabilities of LMs. We analyze Llama-3-70B-Instruct's ability to reason about characters' beliefs using causal mediation and abstraction. We construct a dataset that consists of simple stories where two characters each separately change the state of two objects, potentially unaware of each other's actions. Our investigation uncovered a pervasive algorithmic pattern that we call a lookback mechanism, which enables the LM to recall important information when it becomes necessary. The LM binds each character-object-state triple together by co-locating reference information about them, represented as their Ordering IDs (OIs) in low rank subspaces of the state token's residual stream. When asked about a character's beliefs regarding the state of an object, the binding lookback retrieves the corresponding state OI and then an answer lookback retrieves the state token. When we introduce text specifying that one character is (not) visible to the other, we find that the LM first generates a visibility ID encoding the relation between the observing and the observed character OIs. In a visibility lookback, this ID is used to retrieve information about the observed character and update the observing character's beliefs. Our work provides insights into the LM's belief tracking mechanisms, taking a step toward reverse-engineering ToM reasoning in LMs.
Effects of AI Feedback on Learning, the Skill Gap, and Intellectual Diversity
Sep 27, 2024Can human decision-makers learn from AI feedback? Using data on 52,000 decision-makers from a large online chess platform, we investigate how their AI use affects three interrelated long-term outcomes: Learning, skill gap, and diversity of decision strategies. First, we show that individuals are far more likely to seek AI feedback in situations in which they experienced success rather than failure. This AI feedback seeking strategy turns out to be detrimental to learning: Feedback on successes decreases future performance, while feedback on failures increases it. Second, higher-skilled decision-makers seek AI feedback more often and are far more likely to seek AI feedback after a failure, and benefit more from AI feedback than lower-skilled individuals. As a result, access to AI feedback increases, rather than decreases, the skill gap between high- and low-skilled individuals. Finally, we leverage 42 major platform updates as natural experiments to show that access to AI feedback causes a decrease in intellectual diversity of the population as individuals tend to specialize in the same areas. Together, those results indicate that learning from AI feedback is not automatic and using AI correctly seems to be a skill itself. Furthermore, despite its individual-level benefits, access to AI feedback can have significant population-level downsides including loss of intellectual diversity and an increasing skill gap.
Large Language Models for Automatic Milestone Detection in Group Discussions
Jun 16, 2024Large language models like GPT have proven widely successful on natural language understanding tasks based on written text documents. In this paper, we investigate an LLM's performance on recordings of a group oral communication task in which utterances are often truncated or not well-formed. We propose a new group task experiment involving a puzzle with several milestones that can be achieved in any order. We investigate methods for processing transcripts to detect if, when, and by whom a milestone has been completed. We demonstrate that iteratively prompting GPT with transcription chunks outperforms semantic similarity search methods using text embeddings, and further discuss the quality and randomness of GPT responses under different context window sizes.
Fast Model-Selection through Adapting Design of Experiments Maximizing Information Gain
Oct 23, 2018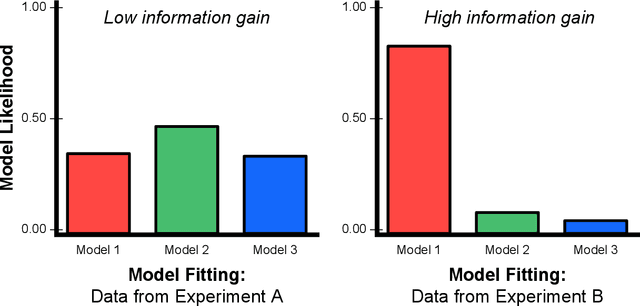

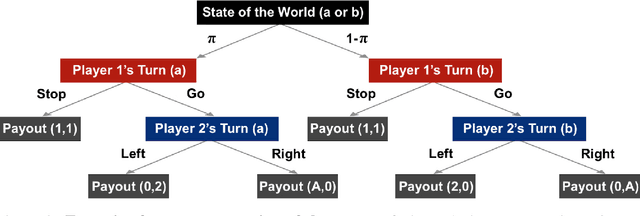
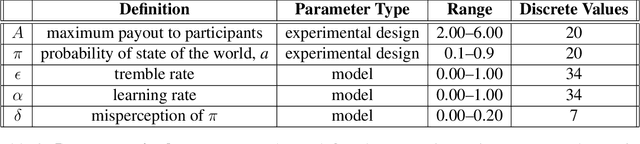
To perform model-selection efficiently, we must run informative experiments. Here, we extend a seminal method for designing Bayesian optimal experiments that maximize the information gained from data collected. We introduce two computational improvements that make the procedure tractable: a search algorithm from artificial intelligence and a sampling procedure shrinking the space of possible experiments to evaluate. We collected data for five different experimental designs of a simple imperfect information game and show that experiments optimized for information gain make model-selection possible (and cheaper). We compare the ability of the optimal experimental design to discriminate among competing models against the experimental designs chosen by a "wisdom of experts" prediction experiment. We find that a simple reinforcement learning model best explains human decision-making and that subject behavior is not adequately described by Bayesian Nash equilibrium. Our procedure is general and can be applied iteratively to lab, field and online experiments.
Detecting Figures and Part Labels in Patents: Competition-Based Development of Image Processing Algorithms
Nov 11, 2014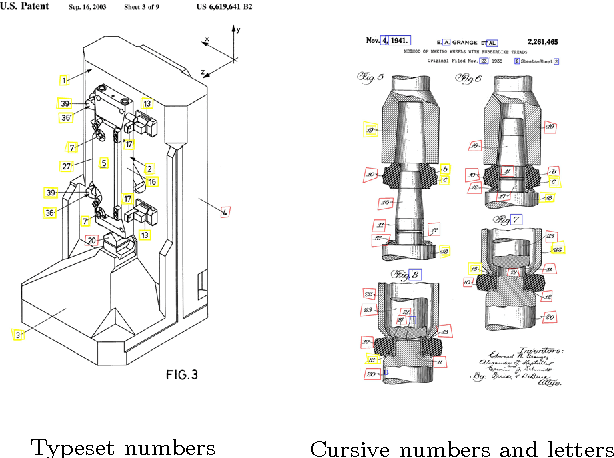


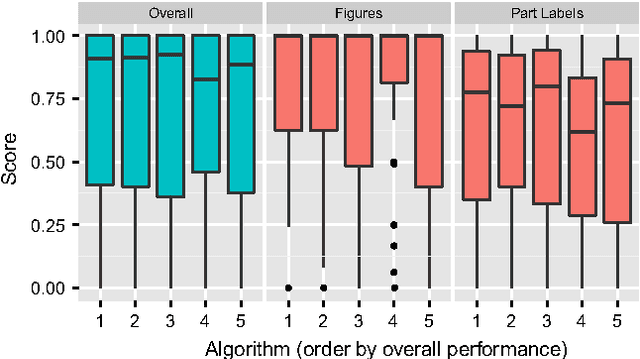
We report the findings of a month-long online competition in which participants developed algorithms for augmenting the digital version of patent documents published by the United States Patent and Trademark Office (USPTO). The goal was to detect figures and part labels in U.S. patent drawing pages. The challenge drew 232 teams of two, of which 70 teams (30%) submitted solutions. Collectively, teams submitted 1,797 solutions that were compiled on the competition servers. Participants reported spending an average of 63 hours developing their solutions, resulting in a total of 5,591 hours of development time. A manually labeled dataset of 306 patents was used for training, online system tests, and evaluation. The design and performance of the top-5 systems are presented, along with a system developed after the competition which illustrates that winning teams produced near state-of-the-art results under strict time and computation constraints. For the 1st place system, the harmonic mean of recall and precision (f-measure) was 88.57% for figure region detection, 78.81% for figure regions with correctly recognized figure titles, and 70.98% for part label detection and character recognition. Data and software from the competition are available through the online UCI Machine Learning repository to inspire follow-on work by the image processing community.