 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Synthesis of Knowledge in GPT-Generated Texts: A Case Study in Automatic Related Work Composition
Feb 19, 2024Numerous AI-assisted scholarly applications have been developed to aid different stages of the research process. We present an analysis of AI-assisted scholarly writing generated with ScholaCite, a tool we built that is designed for organizing literature and composing Related Work sections for academic papers. Our evaluation method focuses on the analysis of citation graphs to assess the structural complexity and inter-connectedness of citations in texts and involves a three-way comparison between (1) original human-written texts, (2) purely GPT-generated texts, and (3) human-AI collaborative texts. We find that GPT-4 can generate reasonable coarse-grained citation groupings to support human users in brainstorming, but fails to perform detailed synthesis of related works without human intervention. We suggest that future writing assistant tools should not be used to draft text independently of the human author.
Beyond the Chat: Executable and Verifiable Text-Editing with LLMs
Sep 27, 2023Conversational interfaces powered by Large Language Models (LLMs) have recently become a popular way to obtain feedback during document editing. However, standard chat-based conversational interfaces do not support transparency and verifiability of the editing changes that they suggest. To give the author more agency when editing with an LLM, we present InkSync, an editing interface that suggests executable edits directly within the document being edited. Because LLMs are known to introduce factual errors, Inksync also supports a 3-stage approach to mitigate this risk: Warn authors when a suggested edit introduces new information, help authors Verify the new information's accuracy through external search, and allow an auditor to perform an a-posteriori verification by Auditing the document via a trace of all auto-generated content. Two usability studies confirm the effectiveness of InkSync's components when compared to standard LLM-based chat interfaces, leading to more accurate, more efficient editing, and improved user experience.
Complex Mathematical Symbol Definition Structures: A Dataset and Model for Coordination Resolution in Definition Extraction
May 24, 2023Mathematical symbol definition extraction is important for improving scholarly reading interfaces and scholarly information extraction (IE). However, the task poses several challenges: math symbols are difficult to process as they are not composed of natural language morphemes; and scholarly papers often contain sentences that require resolving complex coordinate structures. We present SymDef, an English language dataset of 5,927 sentences from full-text scientific papers where each sentence is annotated with all mathematical symbols linked with their corresponding definitions. This dataset focuses specifically on complex coordination structures such as "respectively" constructions, which often contain overlapping definition spans. We also introduce a new definition extraction method that masks mathematical symbols, creates a copy of each sentence for each symbol, specifies a target symbol, and predicts its corresponding definition spans using slot filling. Our experiments show that our definition extraction model significantly outperforms RoBERTa and other strong IE baseline systems by 10.9 points with a macro F1 score of 84.82. With our dataset and model, we can detect complex definitions in scholarly documents to make scientific writing more readable.
Pragmatically Appropriate Diversity for Dialogue Evaluation
Apr 06, 2023Linguistic pragmatics state that a conversation's underlying speech acts can constrain the type of response which is appropriate at each turn in the conversation. When generating dialogue responses, neural dialogue agents struggle to produce diverse responses. Currently, dialogue diversity is assessed using automatic metrics, but the underlying speech acts do not inform these metrics. To remedy this, we propose the notion of Pragmatically Appropriate Diversity, defined as the extent to which a conversation creates and constrains the creation of multiple diverse responses. Using a human-created multi-response dataset, we find significant support for the hypothesis that speech acts provide a signal for the diversity of the set of next responses. Building on this result, we propose a new human evaluation task where creative writers predict the extent to which conversations inspire the creation of multiple diverse responses. Our studies find that writers' judgments align with the Pragmatically Appropriate Diversity of conversations. Our work suggests that expectations for diversity metric scores should vary depending on the speech act.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
Semantic Diversity in Dialogue with Natural Language Inference
May 03, 2022

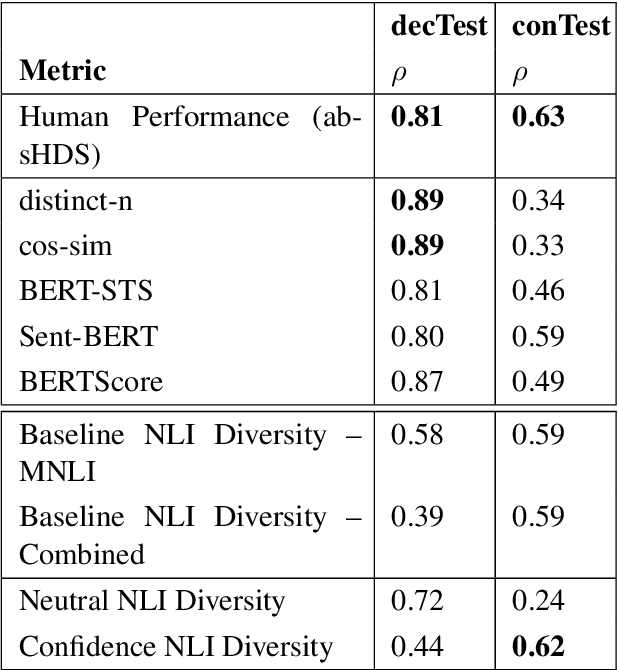
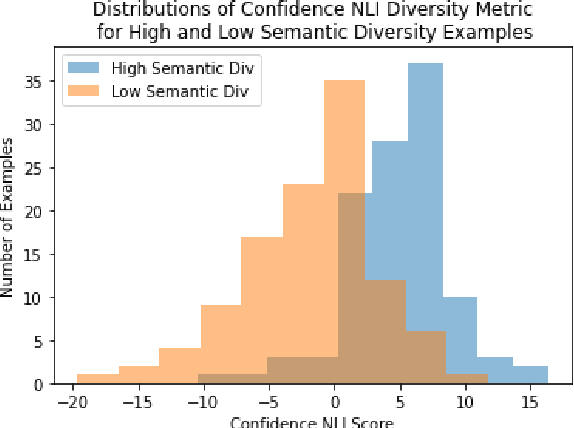
Generating diverse, interesting responses to chitchat conversations is a problem for neural conversational agents. This paper makes two substantial contributions to improving diversity in dialogue generation. First, we propose a novel metric which uses Natural Language Inference (NLI) to measure the semantic diversity of a set of model responses for a conversation. We evaluate this metric using an established framework (Tevet and Berant, 2021) and find strong evidence indicating NLI Diversity is correlated with semantic diversity. Specifically, we show that the contradiction relation is more useful than the neutral relation for measuring this diversity and that incorporating the NLI model's confidence achieves state-of-the-art results. Second, we demonstrate how to iteratively improve the semantic diversity of a sampled set of responses via a new generation procedure called Diversity Threshold Generation, which results in an average 137% increase in NLI Diversity compared to standard generation procedures.
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing
Feb 28, 2022
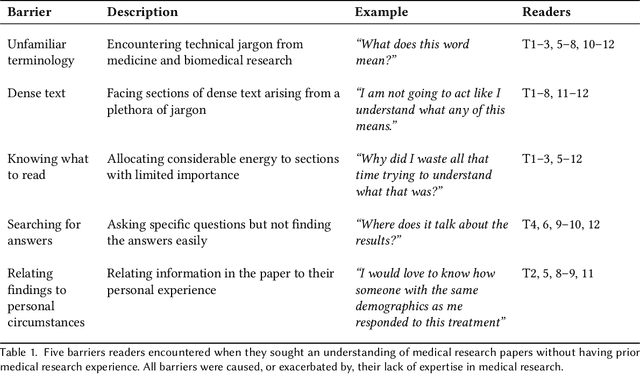

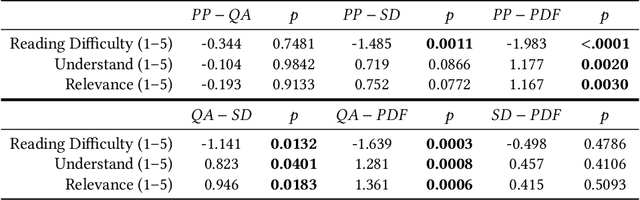
When seeking information not covered in patient-friendly documents, like medical pamphlets, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we introduce a novel interactive interface-Paper Plain-with four features powered by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guide readers to answering passages, and plain language summaries of the answering passages. We evaluate Paper Plain, finding that participants who use Paper Plain have an easier time reading and understanding research papers without a loss in paper comprehension compared to those who use a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries, or "gists," alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.
NewsPod: Automatic and Interactive News Podcasts
Feb 15, 2022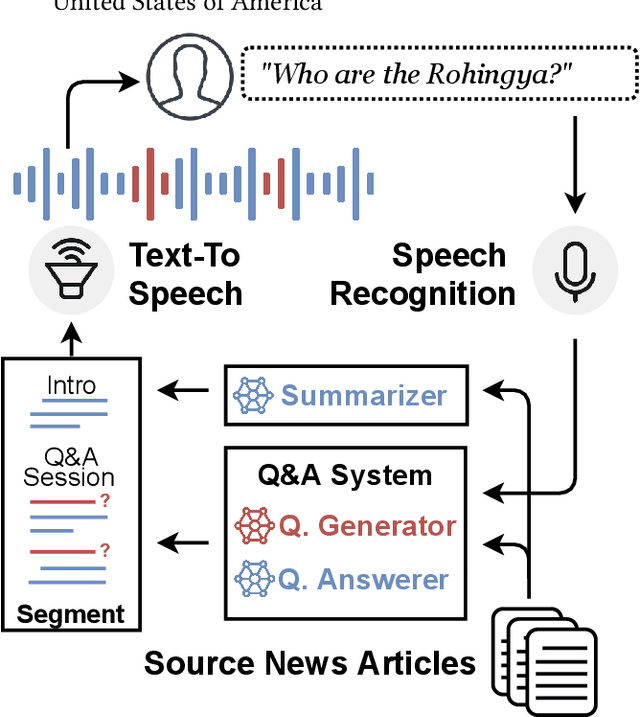
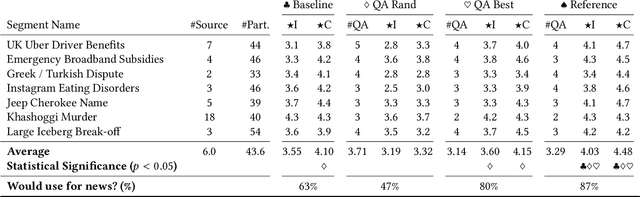
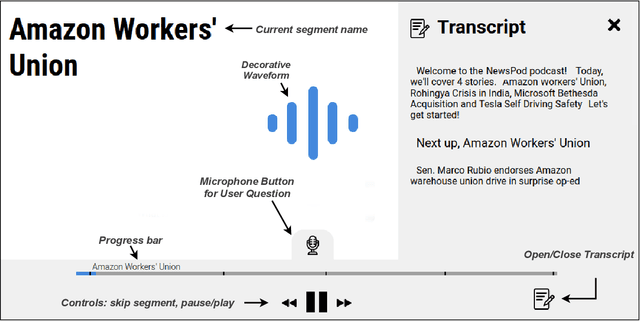
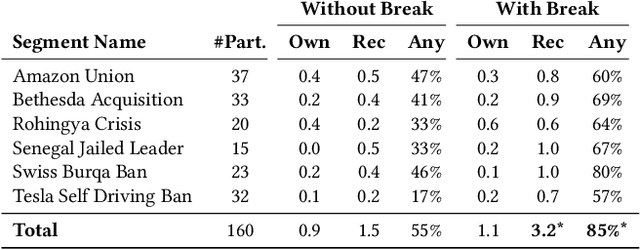
News podcasts are a popular medium to stay informed and dive deep into news topics. Today, most podcasts are handcrafted by professionals. In this work, we advance the state-of-the-art in automatically generated podcasts, making use of recent advances in natural language processing and text-to-speech technology. We present NewsPod, an automatically generated, interactive news podcast. The podcast is divided into segments, each centered on a news event, with each segment structured as a Question and Answer conversation, whose goal is to engage the listener. A key aspect of the design is the use of distinct voices for each role (questioner, responder), to better simulate a conversation. Another novel aspect of NewsPod allows listeners to interact with the podcast by asking their own questions and receiving automatically generated answers. We validate the soundness of this system design through two usability studies, focused on evaluating the narrative style and interactions with the podcast, respectively. We find that NewsPod is preferred over a baseline by participants, with 80% claiming they would use the system in the future.
SummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
Nov 18, 2021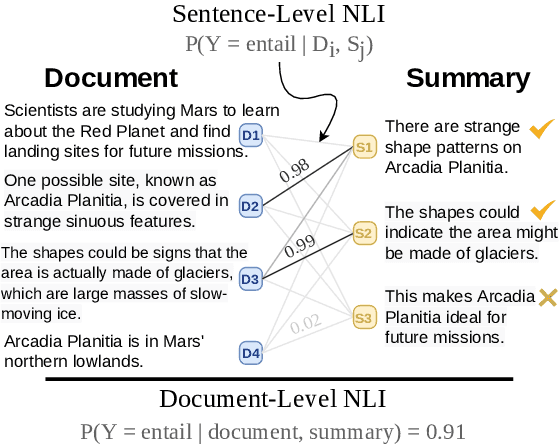
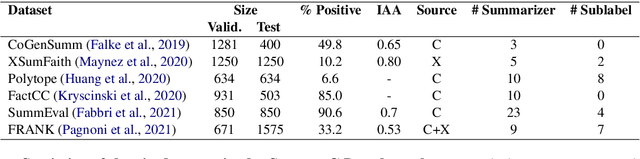
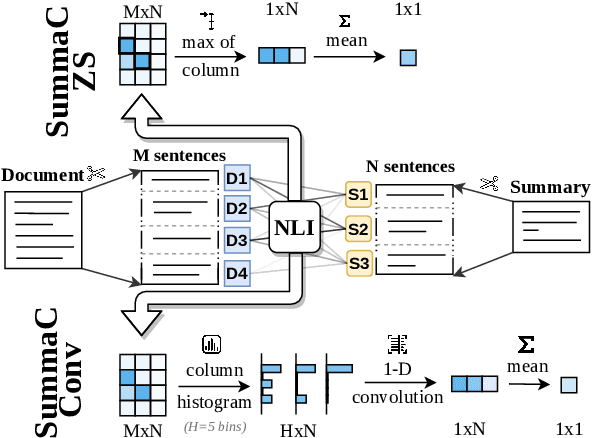

In the summarization domain, a key requirement for summaries is to be factually consistent with the input document. Previous work has found that natural language inference (NLI) models do not perform competitively when applied to inconsistency detection. In this work, we revisit the use of NLI for inconsistency detection, finding that past work suffered from a mismatch in input granularity between NLI datasets (sentence-level), and inconsistency detection (document level). We provide a highly effective and light-weight method called SummaCConv that enables NLI models to be successfully used for this task by segmenting documents into sentence units and aggregating scores between pairs of sentences. On our newly introduced benchmark called SummaC (Summary Consistency) consisting of six large inconsistency detection datasets, SummaCConv obtains state-of-the-art results with a balanced accuracy of 74.4%, a 5% point improvement compared to prior work. We make the models and datasets available: https://github.com/tingofurro/summac
Can Transformer Models Measure Coherence In Text? Re-Thinking the Shuffle Test
Jul 07, 2021
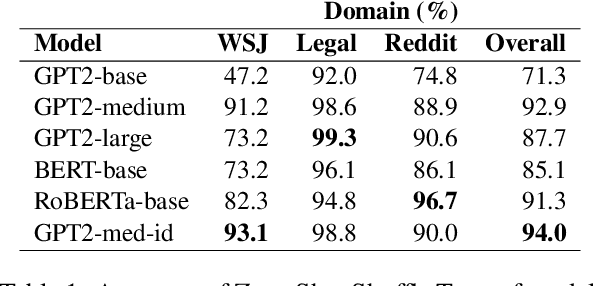
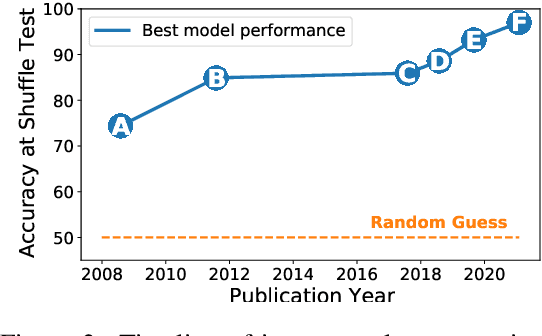
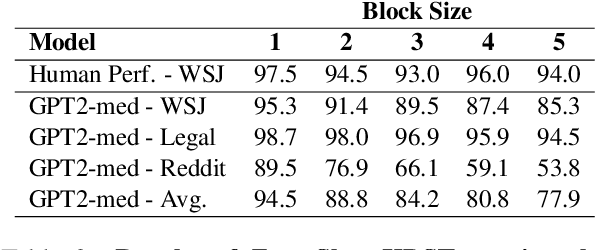
The Shuffle Test is the most common task to evaluate whether NLP models can measure coherence in text. Most recent work uses direct supervision on the task; we show that by simply finetuning a RoBERTa model, we can achieve a near perfect accuracy of 97.8%, a state-of-the-art. We argue that this outstanding performance is unlikely to lead to a good model of text coherence, and suggest that the Shuffle Test should be approached in a Zero-Shot setting: models should be evaluated without being trained on the task itself. We evaluate common models in this setting, such as Generative and Bi-directional Transformers, and find that larger architectures achieve high-performance out-of-the-box. Finally, we suggest the k-Block Shuffle Test, a modification of the original by increasing the size of blocks shuffled. Even though human reader performance remains high (around 95% accuracy), model performance drops from 94% to 78% as block size increases, creating a conceptually simple challenge to benchmark NLP models. Code available: https://github.com/tingofurro/shuffle_test/
* Accepted at ACL-IJCNLP 2021 (short paper), 7 pages, 4 figures