 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Positional Bias of Faithfulness for Long-form Summarization
Oct 31, 2024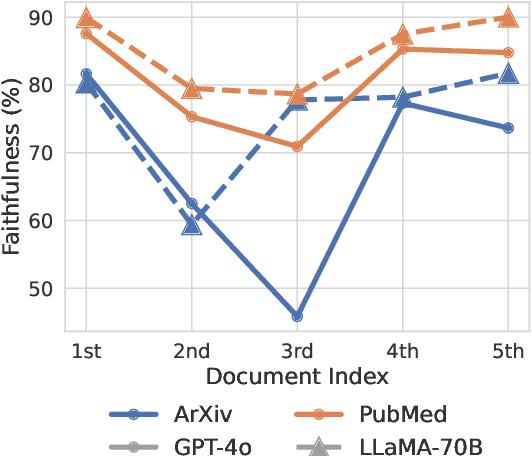

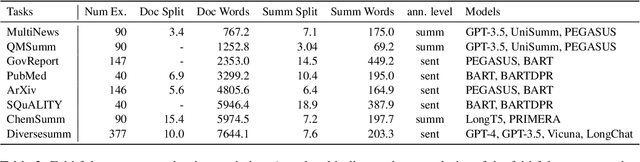

Large Language Models (LLMs) often exhibit positional bias in long-context settings, under-attending to information in the middle of inputs. We investigate the presence of this bias in long-form summarization, its impact on faithfulness, and various techniques to mitigate this bias. To consistently evaluate faithfulness, we first compile a benchmark of eight human-annotated long-form summarization datasets and perform a meta-evaluation of faithfulness metrics. We show that LLM-based faithfulness metrics, though effective with full-context inputs, remain sensitive to document order, indicating positional bias. Analyzing LLM-generated summaries across six datasets, we find a "U-shaped" trend in faithfulness, where LLMs faithfully summarize the beginning and end of documents but neglect middle content. Perturbing document order similarly reveals models are less faithful when important documents are placed in the middle of the input. We find that this behavior is partly due to shifting focus with context length: as context increases, summaries become less faithful, but beyond a certain length, faithfulness improves as the model focuses on the end. Finally, we experiment with different generation techniques to reduce positional bias and find that prompting techniques effectively direct model attention to specific positions, whereas more sophisticated approaches offer limited improvements. Our data and code are available in https://github.com/meetdavidwan/longformfact.
Beyond the Chat: Executable and Verifiable Text-Editing with LLMs
Sep 27, 2023



Conversational interfaces powered by Large Language Models (LLMs) have recently become a popular way to obtain feedback during document editing. However, standard chat-based conversational interfaces do not support transparency and verifiability of the editing changes that they suggest. To give the author more agency when editing with an LLM, we present InkSync, an editing interface that suggests executable edits directly within the document being edited. Because LLMs are known to introduce factual errors, Inksync also supports a 3-stage approach to mitigate this risk: Warn authors when a suggested edit introduces new information, help authors Verify the new information's accuracy through external search, and allow an auditor to perform an a-posteriori verification by Auditing the document via a trace of all auto-generated content. Two usability studies confirm the effectiveness of InkSync's components when compared to standard LLM-based chat interfaces, leading to more accurate, more efficient editing, and improved user experience.
XGen-7B Technical Report
Sep 07, 2023Large Language Models (LLMs) have become ubiquitous across various domains, transforming the way we interact with information and conduct research. However, most high-performing LLMs remain confined behind proprietary walls, hindering scientific progress. Most open-source LLMs, on the other hand, are limited in their ability to support longer sequence lengths, which is a key requirement for many tasks that require inference over an input context. To address this, we have trained XGen, a series of 7B parameter models on up to 8K sequence length for up to 1.5T tokens. We have also finetuned the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-Inst). We open-source our models for both research advancements and commercial applications. Our evaluation on standard benchmarks shows that XGen models achieve comparable or better results when compared with state-of-the-art open-source LLMs. Our targeted evaluation on long sequence modeling tasks shows the benefits of our 8K-sequence models over 2K-sequence open-source LLMs.
Did You Read the Instructions? Rethinking the Effectiveness of Task Definitions in Instruction Learning
Jun 01, 2023Large language models (LLMs) have shown impressive performance in following natural language instructions to solve unseen tasks. However, it remains unclear whether models truly understand task definitions and whether the human-written definitions are optimal. In this paper, we systematically study the role of task definitions in instruction learning. We first conduct an ablation analysis informed by human annotations to understand which parts of a task definition are most important, and find that model performance only drops substantially when removing contents describing the task output, in particular label information. Next, we propose an automatic algorithm to compress task definitions to a minimal supporting set of tokens, and find that 60\% of tokens can be removed while maintaining or even improving model performance. Based on these results, we propose two strategies to help models better leverage task instructions: (1) providing only key information for tasks in a common structured format, and (2) adding a meta-tuning stage to help the model better understand the definitions. With these two strategies, we achieve a 4.2 Rouge-L improvement over 119 unseen test tasks.
SWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages
May 30, 2023Text simplification research has mostly focused on sentence-level simplification, even though many desirable edits - such as adding relevant background information or reordering content - may require document-level context. Prior work has also predominantly framed simplification as a single-step, input-to-output task, only implicitly modeling the fine-grained, span-level edits that elucidate the simplification process. To address both gaps, we introduce the SWiPE dataset, which reconstructs the document-level editing process from English Wikipedia (EW) articles to paired Simple Wikipedia (SEW) articles. In contrast to prior work, SWiPE leverages the entire revision history when pairing pages in order to better identify simplification edits. We work with Wikipedia editors to annotate 5,000 EW-SEW document pairs, labeling more than 40,000 edits with proposed 19 categories. To scale our efforts, we propose several models to automatically label edits, achieving an F-1 score of up to 70.6, indicating that this is a tractable but challenging NLU task. Finally, we categorize the edits produced by several simplification models and find that SWiPE-trained models generate more complex edits while reducing unwanted edits.
Improving Factual Consistency in Summarization with Compression-Based Post-Editing
Nov 11, 2022State-of-the-art summarization models still struggle to be factually consistent with the input text. A model-agnostic way to address this problem is post-editing the generated summaries. However, existing approaches typically fail to remove entity errors if a suitable input entity replacement is not available or may insert erroneous content. In our work, we focus on removing extrinsic entity errors, or entities not in the source, to improve consistency while retaining the summary's essential information and form. We propose to use sentence-compression data to train the post-editing model to take a summary with extrinsic entity errors marked with special tokens and output a compressed, well-formed summary with those errors removed. We show that this model improves factual consistency while maintaining ROUGE, improving entity precision by up to 30% on XSum, and that this model can be applied on top of another post-editor, improving entity precision by up to a total of 38%. We perform an extensive comparison of post-editing approaches that demonstrate trade-offs between factual consistency, informativeness, and grammaticality, and we analyze settings where post-editors show the largest improvements.
Interactive Model Cards: A Human-Centered Approach to Model Documentation
May 05, 2022
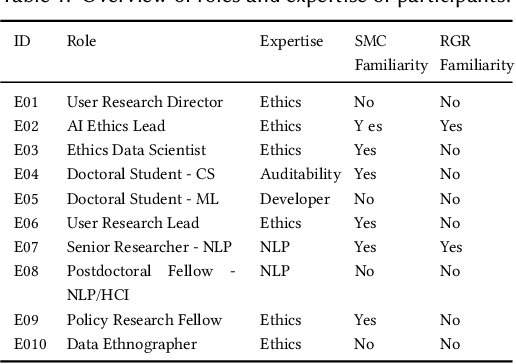
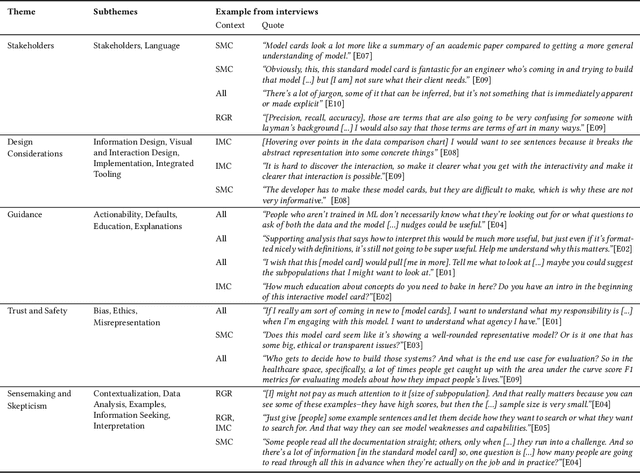

Deep learning models for natural language processing (NLP) are increasingly adopted and deployed by analysts without formal training in NLP or machine learning (ML). However, the documentation intended to convey the model's details and appropriate use is tailored primarily to individuals with ML or NLP expertise. To address this gap, we conduct a design inquiry into interactive model cards, which augment traditionally static model cards with affordances for exploring model documentation and interacting with the models themselves. Our investigation consists of an initial conceptual study with experts in ML, NLP, and AI Ethics, followed by a separate evaluative study with non-expert analysts who use ML models in their work. Using a semi-structured interview format coupled with a think-aloud protocol, we collected feedback from a total of 30 participants who engaged with different versions of standard and interactive model cards. Through a thematic analysis of the collected data, we identified several conceptual dimensions that summarize the strengths and limitations of standard and interactive model cards, including: stakeholders; design; guidance; understandability & interpretability; sensemaking & skepticism; and trust & safety. Our findings demonstrate the importance of carefully considered design and interactivity for orienting and supporting non-expert analysts using deep learning models, along with a need for consideration of broader sociotechnical contexts and organizational dynamics. We have also identified design elements, such as language, visual cues, and warnings, among others, that support interactivity and make non-interactive content accessible. We summarize our findings as design guidelines and discuss their implications for a human-centered approach towards AI/ML documentation.
iSEA: An Interactive Pipeline for Semantic Error Analysis of NLP Models
Mar 08, 2022
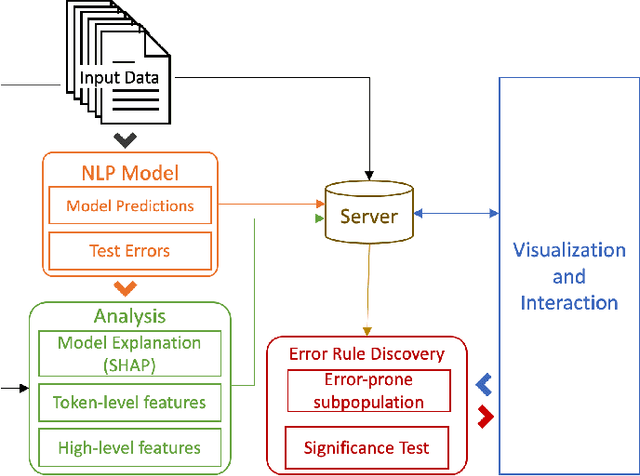
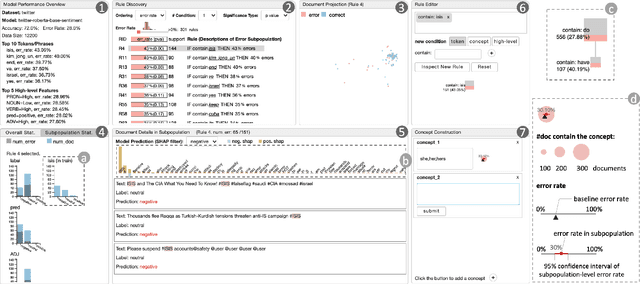
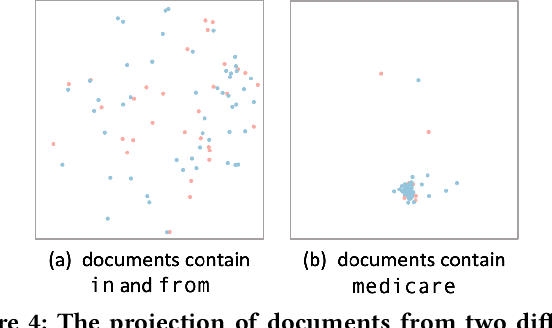
Error analysis in NLP models is essential to successful model development and deployment. One common approach for diagnosing errors is to identify subpopulations in the dataset where the model produces the most errors. However, existing approaches typically define subpopulations based on pre-defined features, which requires users to form hypotheses of errors in advance. To complement these approaches, we propose iSEA, an Interactive Pipeline for Semantic Error Analysis in NLP Models, which automatically discovers semantically-grounded subpopulations with high error rates in the context of a human-in-the-loop interactive system. iSEA enables model developers to learn more about their model errors through discovered subpopulations, validate the sources of errors through interactive analysis on the discovered subpopulations, and test hypotheses about model errors by defining custom subpopulations. The tool supports semantic descriptions of error-prone subpopulations at the token and concept level, as well as pre-defined higher-level features. Through use cases and expert interviews, we demonstrate how iSEA can assist error understanding and analysis.
Exploring Neural Models for Query-Focused Summarization
Dec 15, 2021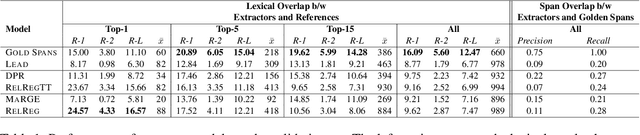
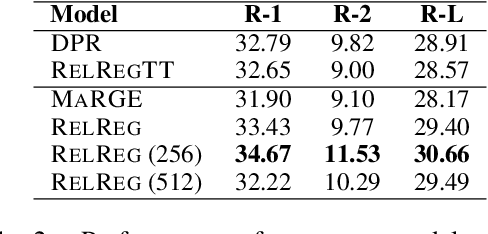
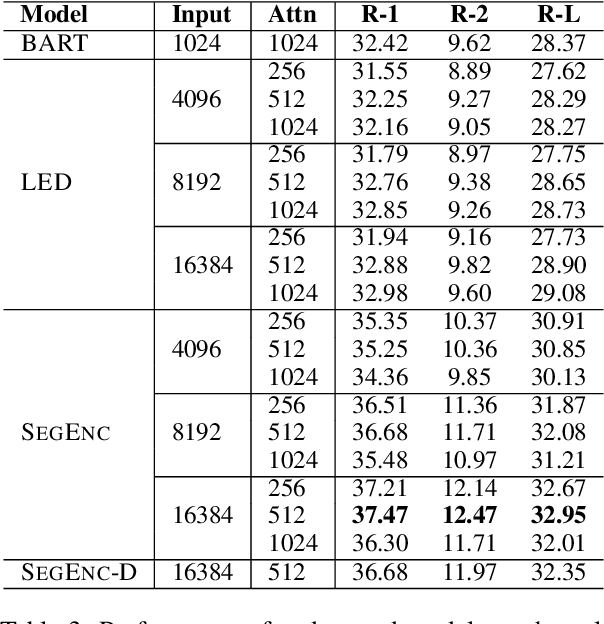
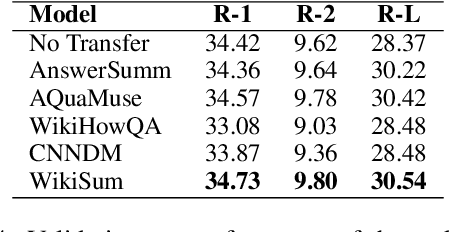
Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. While recently released datasets, such as QMSum or AQuaMuSe, facilitate research efforts in QFS, the field lacks a comprehensive study of the broad space of applicable modeling methods. In this paper we conduct a systematic exploration of neural approaches to QFS, considering two general classes of methods: two-stage extractive-abstractive solutions and end-to-end models. Within those categories, we investigate existing methods and present two model extensions that achieve state-of-the-art performance on the QMSum dataset by a margin of up to 3.38 ROUGE-1, 3.72 ROUGE-2, and 3.28 ROUGE-L. Through quantitative experiments we highlight the trade-offs between different model configurations and explore the transfer abilities between summarization tasks. Code and checkpoints are made publicly available: https://github.com/salesforce/query-focused-sum.
MoFE: Mixture of Factual Experts for Controlling Hallucinations in Abstractive Summarization
Oct 14, 2021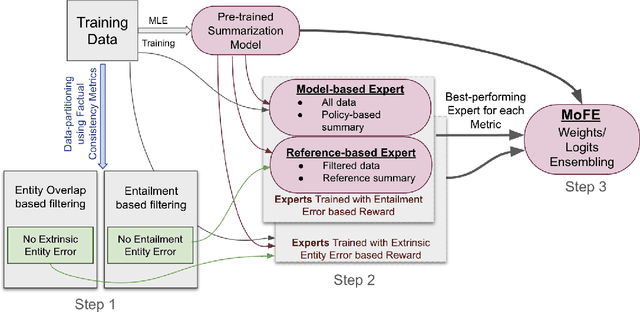
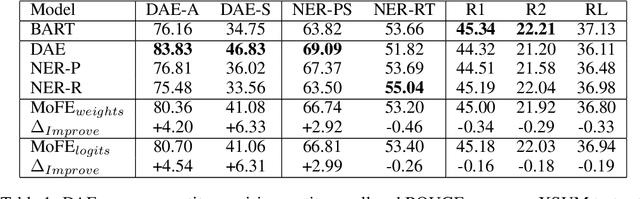
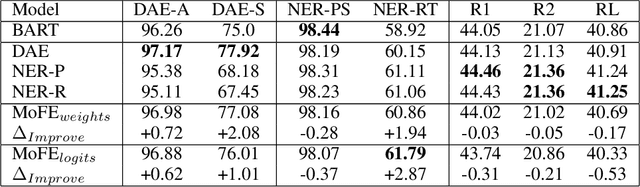
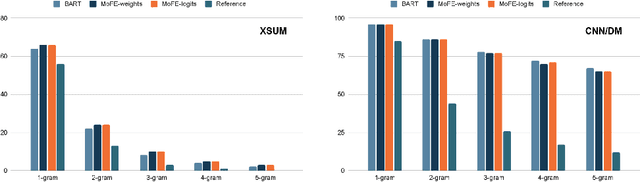
Neural abstractive summarization models are susceptible to generating factually inconsistent content, a phenomenon known as hallucination. This limits the usability and adoption of these systems in real-world applications. To reduce the presence of hallucination, we propose the Mixture of Factual Experts (MoFE) model, which combines multiple summarization experts that each target a specific type of error. We train our experts using reinforcement learning (RL) to minimize the error defined by two factual consistency metrics: entity overlap and dependency arc entailment. We construct MoFE by combining the experts using two ensembling strategies (weights and logits) and evaluate them on two summarization datasets (XSUM and CNN/DM). Our experiments on BART models show that the MoFE improves performance according to both entity overlap and dependency arc entailment, without a significant performance drop on standard ROUGE metrics. The performance improvement also transfers to unseen factual consistency metrics, such as question answer-based factuality evaluation metric and BERTScore precision with respect to the source document.