 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Feb 03, 2026Multi-Agent Systems (MAS) built on Large Language Models (LLMs) often exhibit high variance in their reasoning trajectories. Process verification, which evaluates intermediate steps in trajectories, has shown promise in general reasoning settings, and has been suggested as a potential tool for guiding coordination of MAS; however, its actual effectiveness in MAS remains unclear. To fill this gap, we present MAS-ProVe, a systematic empirical study of process verification for multi-agent systems (MAS). Our study spans three verification paradigms (LLM-as-a-Judge, reward models, and process reward models), evaluated across two levels of verification granularity (agent-level and iteration-level). We further examine five representative verifiers and four context management strategies, and conduct experiments over six diverse MAS frameworks on multiple reasoning benchmarks. We find that process-level verification does not consistently improve performance and frequently exhibits high variance, highlighting the difficulty of reliably evaluating partial multi-agent trajectories. Among the methods studied, LLM-as-a-Judge generally outperforms reward-based approaches, with trained judges surpassing general-purpose LLMs. We further observe a small performance gap between LLMs acting as judges and as single agents, and identify a context-length-performance trade-off in verification. Overall, our results suggest that effective and robust process verification for MAS remains an open challenge, requiring further advances beyond current paradigms. Code is available at https://github.com/Wang-ML-Lab/MAS-ProVe.
MAS-Orchestra: Understanding and Improving Multi-Agent Reasoning Through Holistic Orchestration and Controlled Benchmarks
Jan 21, 2026While multi-agent systems (MAS) promise elevated intelligence through coordination of agents, current approaches to automatic MAS design under-deliver. Such shortcomings stem from two key factors: (1) methodological complexity - agent orchestration is performed using sequential, code-level execution that limits global system-level holistic reasoning and scales poorly with agent complexity - and (2) efficacy uncertainty - MAS are deployed without understanding if there are tangible benefits compared to single-agent systems (SAS). We propose MAS-Orchestra, a training-time framework that formulates MAS orchestration as a function-calling reinforcement learning problem with holistic orchestration, generating an entire MAS at once. In MAS-Orchestra, complex, goal-oriented sub-agents are abstracted as callable functions, enabling global reasoning over system structure while hiding internal execution details. To rigorously study when and why MAS are beneficial, we introduce MASBENCH, a controlled benchmark that characterizes tasks along five axes: Depth, Horizon, Breadth, Parallel, and Robustness. Our analysis reveals that MAS gains depend critically on task structure, verification protocols, and the capabilities of both orchestrator and sub-agents, rather than holding universally. Guided by these insights, MAS-Orchestra achieves consistent improvements on public benchmarks including mathematical reasoning, multi-hop QA, and search-based QA. Together, MAS-Orchestra and MASBENCH enable better training and understanding of MAS in the pursuit of multi-agent intelligence.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025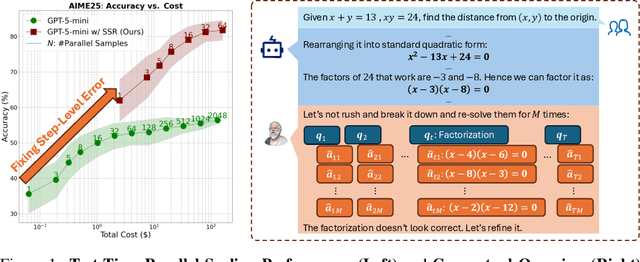
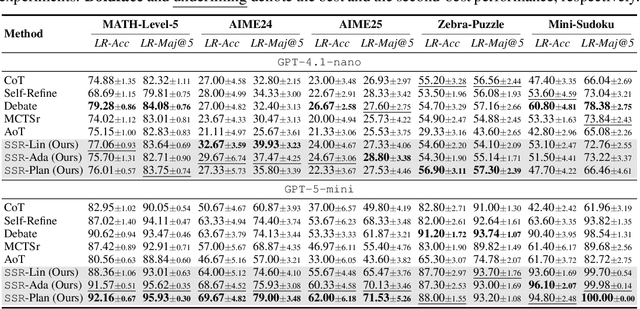
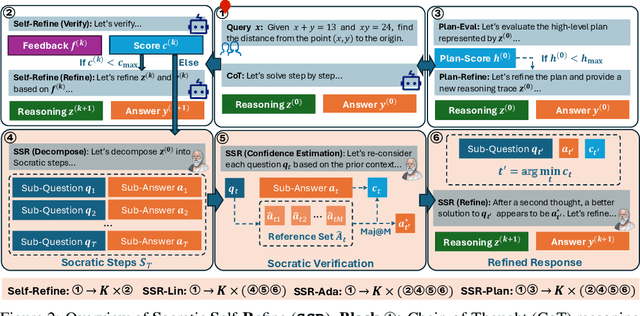
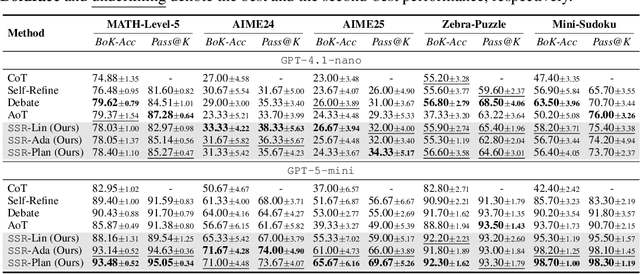
Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025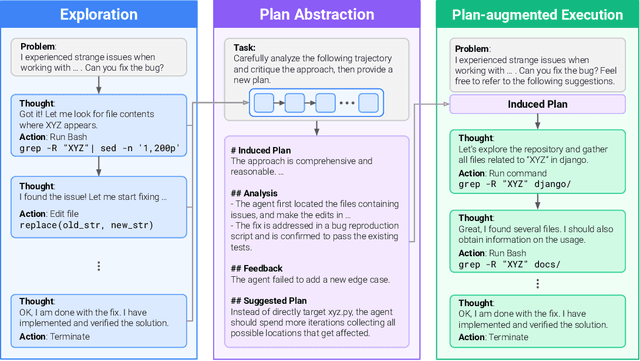

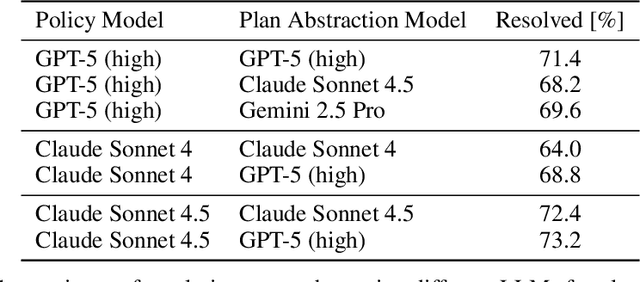
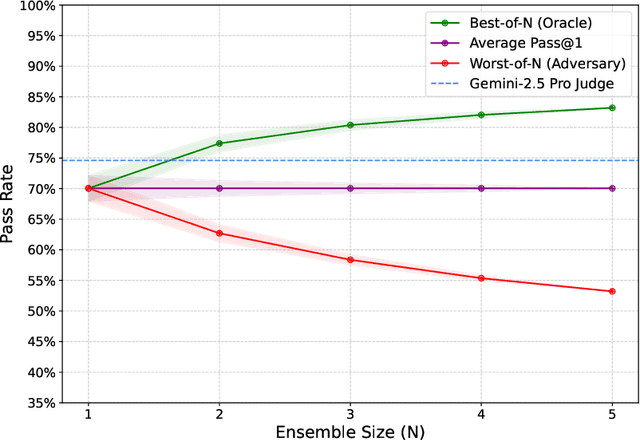
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Retrofitting Small Multilingual Models for Retrieval: Matching 7B Performance with 300M Parameters
Oct 16, 2025Training effective multilingual embedding models presents unique challenges due to the diversity of languages and task objectives. Although small multilingual models (<1 B parameters) perform well on multilingual tasks generally, they consistently lag behind larger models (>1 B) in the most prevalent use case: retrieval. This raises a critical question: Can smaller models be retrofitted specifically for retrieval tasks to enhance their performance? In this work, we investigate key factors that influence the effectiveness of multilingual embeddings, focusing on training data scale, negative sampling strategies, and data diversity. We find that while increasing the scale of training data yields initial performance gains, these improvements quickly plateau - indicating diminishing returns. Incorporating hard negatives proves essential for consistently improving retrieval accuracy. Furthermore, our analysis reveals that task diversity in the training data contributes more significantly to performance than language diversity alone. As a result, we develop a compact (approximately 300M) multilingual model that achieves retrieval performance comparable to or even surpassing current strong 7B models.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
SweRank: Software Issue Localization with Code Ranking
May 07, 2025Software issue localization, the task of identifying the precise code locations (files, classes, or functions) relevant to a natural language issue description (e.g., bug report, feature request), is a critical yet time-consuming aspect of software development. While recent LLM-based agentic approaches demonstrate promise, they often incur significant latency and cost due to complex multi-step reasoning and relying on closed-source LLMs. Alternatively, traditional code ranking models, typically optimized for query-to-code or code-to-code retrieval, struggle with the verbose and failure-descriptive nature of issue localization queries. To bridge this gap, we introduce SweRank, an efficient and effective retrieve-and-rerank framework for software issue localization. To facilitate training, we construct SweLoc, a large-scale dataset curated from public GitHub repositories, featuring real-world issue descriptions paired with corresponding code modifications. Empirical results on SWE-Bench-Lite and LocBench show that SweRank achieves state-of-the-art performance, outperforming both prior ranking models and costly agent-based systems using closed-source LLMs like Claude-3.5. Further, we demonstrate SweLoc's utility in enhancing various existing retriever and reranker models for issue localization, establishing the dataset as a valuable resource for the community.
Does Context Matter? ContextualJudgeBench for Evaluating LLM-based Judges in Contextual Settings
Mar 19, 2025The large language model (LLM)-as-judge paradigm has been used to meet the demand for a cheap, reliable, and fast evaluation of model outputs during AI system development and post-deployment monitoring. While judge models -- LLMs finetuned to specialize in assessing and critiquing model outputs -- have been touted as general purpose evaluators, they are typically evaluated only on non-contextual scenarios, such as instruction following. The omission of contextual settings -- those where external information is used as context to generate an output -- is surprising given the increasing prevalence of retrieval-augmented generation (RAG) and summarization use cases. Contextual assessment is uniquely challenging, as evaluation often depends on practitioner priorities, leading to conditional evaluation criteria (e.g., comparing responses based on factuality and then considering completeness if they are equally factual). To address the gap, we propose ContextualJudgeBench, a judge benchmark with 2,000 challenging response pairs across eight splits inspired by real-world contextual evaluation scenarios. We build our benchmark with a multi-pronged data construction pipeline that leverages both existing human annotations and model-based perturbations. Our comprehensive study across 11 judge models and 9 general purpose models, reveals that the contextual information and its assessment criteria present a significant challenge to even state-of-the-art models. For example, OpenAI's o1, the best-performing model, barely reaches 55% consistent accuracy.
Investigating Factuality in Long-Form Text Generation: The Roles of Self-Known and Self-Unknown
Nov 24, 2024



Large language models (LLMs) have demonstrated strong capabilities in text understanding and generation. However, they often lack factuality, producing a mixture of true and false information, especially in long-form generation. In this work, we investigates the factuality of long-form text generation across various large language models (LLMs), including GPT-4, Gemini-1.5-Pro, Claude-3-Opus, Llama-3-70B, and Mistral. Our analysis reveals that factuality scores tend to decline in later sentences of the generated text, accompanied by a rise in the number of unsupported claims. Furthermore, we explore the effectiveness of different evaluation settings to assess whether LLMs can accurately judge the correctness of their own outputs: Self-Known (the percentage of supported atomic claims, decomposed from LLM outputs, that the corresponding LLMs judge as correct) and Self-Unknown (the percentage of unsupported atomic claims that the corresponding LLMs judge as incorrect). The results indicate that even advanced models like GPT-4 and Gemini-1.5-Pro fail to achieve perfect Self-Known scores, while their Self-Unknown scores remain notably above zero, reflecting ongoing uncertainty in their self-assessments. Moreover, we find a correlation between higher Self-Known scores and improved factuality, while higher Self-Unknown scores are associated with lower factuality. Interestingly, even without significant changes in the models' self-judgment (Self-Known and Self-Unknown), the number of unsupported claims can increases, likely as an artifact of long-form generation. These findings show the limitations of current LLMs in long-form generation, and provide valuable insights for improving factuality in long-form text generation.