 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025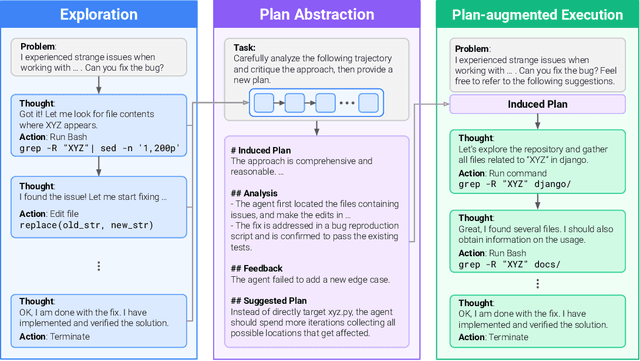

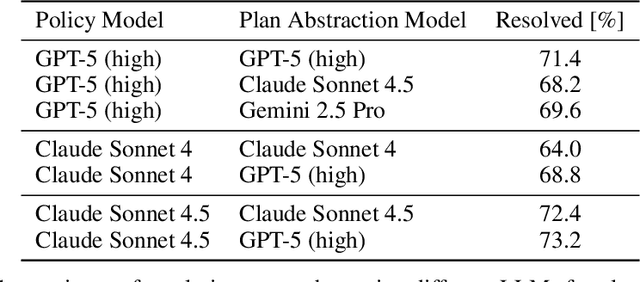
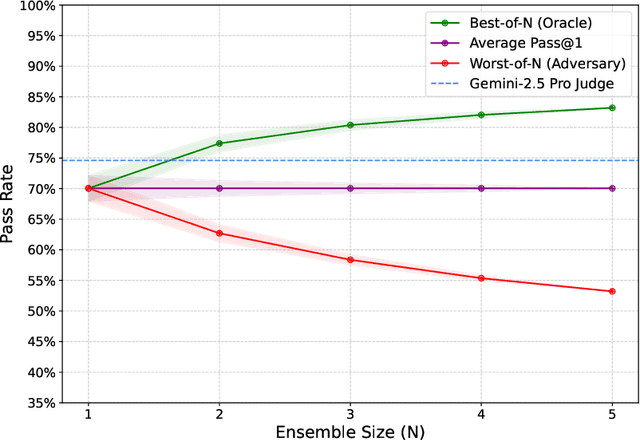
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Does Context Matter? ContextualJudgeBench for Evaluating LLM-based Judges in Contextual Settings
Mar 19, 2025The large language model (LLM)-as-judge paradigm has been used to meet the demand for a cheap, reliable, and fast evaluation of model outputs during AI system development and post-deployment monitoring. While judge models -- LLMs finetuned to specialize in assessing and critiquing model outputs -- have been touted as general purpose evaluators, they are typically evaluated only on non-contextual scenarios, such as instruction following. The omission of contextual settings -- those where external information is used as context to generate an output -- is surprising given the increasing prevalence of retrieval-augmented generation (RAG) and summarization use cases. Contextual assessment is uniquely challenging, as evaluation often depends on practitioner priorities, leading to conditional evaluation criteria (e.g., comparing responses based on factuality and then considering completeness if they are equally factual). To address the gap, we propose ContextualJudgeBench, a judge benchmark with 2,000 challenging response pairs across eight splits inspired by real-world contextual evaluation scenarios. We build our benchmark with a multi-pronged data construction pipeline that leverages both existing human annotations and model-based perturbations. Our comprehensive study across 11 judge models and 9 general purpose models, reveals that the contextual information and its assessment criteria present a significant challenge to even state-of-the-art models. For example, OpenAI's o1, the best-performing model, barely reaches 55% consistent accuracy.
PEFTDebias : Capturing debiasing information using PEFTs
Dec 01, 2023The increasing use of foundation models highlights the urgent need to address and eliminate implicit biases present in them that arise during pretraining. In this paper, we introduce PEFTDebias, a novel approach that employs parameter-efficient fine-tuning (PEFT) to mitigate the biases within foundation models. PEFTDebias consists of two main phases: an upstream phase for acquiring debiasing parameters along a specific bias axis, and a downstream phase where these parameters are incorporated into the model and frozen during the fine-tuning process. By evaluating on four datasets across two bias axes namely gender and race, we find that downstream biases can be effectively reduced with PEFTs. In addition, we show that these parameters possess axis-specific debiasing characteristics, enabling their effective transferability in mitigating biases in various downstream tasks. To ensure reproducibility, we release the code to do our experiments.
Few-shot Unified Question Answering: Tuning Models or Prompts?
May 23, 2023Question-answering (QA) tasks often investigate specific question types, knowledge domains, or reasoning skills, leading to specialized models catering to specific categories of QA tasks. While recent research has explored the idea of unified QA models, such models are usually explored for high-resource scenarios and require re-training to extend their capabilities. To overcome these drawbacks, the paper explores the potential of two paradigms of tuning, model, and prompts, for unified QA under a low-resource setting. The paper provides an exhaustive analysis of their applicability using 16 QA datasets, revealing that prompt tuning can perform as well as model tuning in a few-shot setting with a good initialization. The study also shows that parameter-sharing results in superior few-shot performance, simple knowledge transfer techniques for prompt initialization can be effective, and prompt tuning achieves a significant performance boost from pre-training in a low-resource regime. The research offers insights into the advantages and limitations of prompt tuning for unified QA in a few-shot setting, contributing to the development of effective and efficient systems in low-resource scenarios.
Debiasing Multilingual Word Embeddings: A Case Study of Three Indian Languages
Jul 22, 2021



In this paper, we advance the current state-of-the-art method for debiasing monolingual word embeddings so as to generalize well in a multilingual setting. We consider different methods to quantify bias and different debiasing approaches for monolingual as well as multilingual settings. We demonstrate the significance of our bias-mitigation approach on downstream NLP applications. Our proposed methods establish the state-of-the-art performance for debiasing multilingual embeddings for three Indian languages - Hindi, Bengali, and Telugu in addition to English. We believe that our work will open up new opportunities in building unbiased downstream NLP applications that are inherently dependent on the quality of the word embeddings used.
Code-switching patterns can be an effective route to improve performance of downstream NLP applications: A case study of humour, sarcasm and hate speech detection
May 05, 2020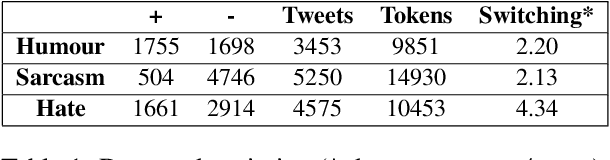

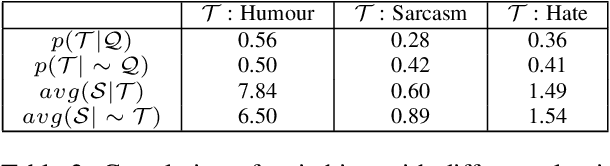

In this paper we demonstrate how code-switching patterns can be utilised to improve various downstream NLP applications. In particular, we encode different switching features to improve humour, sarcasm and hate speech detection tasks. We believe that this simple linguistic observation can also be potentially helpful in improving other similar NLP applications.