 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSeg: Language Grounded Query Banks for Reasoning Segmentation
Apr 22, 2026Reasoning segmentation requires models to ground complex, implicit textual queries into precise pixel-level masks. Existing approaches rely on a single segmentation token $\texttt{<SEG>}$, whose hidden state implicitly encodes both semantic reasoning and spatial localization, limiting the model's ability to explicitly disentangle what to segment from where to segment. We introduce AnchorSeg, which reformulates reasoning segmentation as a structured conditional generation process over image tokens, conditioned on language grounded query banks. Instead of compressing all semantic reasoning and spatial localization into a single embedding, AnchorSeg constructs an ordered sequence of query banks: latent reasoning tokens that capture intermediate semantic states, and a segmentation anchor token that provides explicit spatial grounding. We model spatial conditioning as a factorized distribution over image tokens, where the anchor query determines localization signals while contextual queries provide semantic modulation. To bridge token-level predictions and pixel-level supervision, we propose Token--Mask Cycle Consistency (TMCC), a bidirectional training objective that enforces alignment across resolutions. By explicitly decoupling spatial grounding from semantic reasoning through structured language grounded query banks, AnchorSeg achieves state-of-the-art results on ReasonSeg test set (67.7\% gIoU and 68.1\% cIoU). All code and models are publicly available at https://github.com/rui-qian/AnchorSeg.
HyEvo: Self-Evolving Hybrid Agentic Workflows for Efficient Reasoning
Mar 20, 2026Although agentic workflows have demonstrated strong potential for solving complex tasks, existing automated generation methods remain inefficient and underperform, as they rely on predefined operator libraries and homogeneous LLM-only workflows in which all task-level computation is performed through probabilistic inference. To address these limitations, we propose HyEvo, an automated workflow-generation framework that leverages heterogeneous atomic synthesis. HyEvo integrates probabilistic LLM nodes for semantic reasoning with deterministic code nodes for rule-based execution, offloading predictable operations from LLM inference and reducing inference cost and execution latency. To efficiently navigate the hybrid search space, HyEvo employs an LLM-driven multi-island evolutionary strategy with a reflect-then-generate mechanism, iteratively refining both workflow topology and node logic via execution feedback. Comprehensive experiments show that HyEvo consistently outperforms existing methods across diverse reasoning and coding benchmarks, while reducing inference cost and execution latency by up to 19$\times$ and 16$\times$, respectively, compared to the state-of-the-art open-source baseline.
MAS-ProVe: Understanding the Process Verification of Multi-Agent Systems
Feb 03, 2026Multi-Agent Systems (MAS) built on Large Language Models (LLMs) often exhibit high variance in their reasoning trajectories. Process verification, which evaluates intermediate steps in trajectories, has shown promise in general reasoning settings, and has been suggested as a potential tool for guiding coordination of MAS; however, its actual effectiveness in MAS remains unclear. To fill this gap, we present MAS-ProVe, a systematic empirical study of process verification for multi-agent systems (MAS). Our study spans three verification paradigms (LLM-as-a-Judge, reward models, and process reward models), evaluated across two levels of verification granularity (agent-level and iteration-level). We further examine five representative verifiers and four context management strategies, and conduct experiments over six diverse MAS frameworks on multiple reasoning benchmarks. We find that process-level verification does not consistently improve performance and frequently exhibits high variance, highlighting the difficulty of reliably evaluating partial multi-agent trajectories. Among the methods studied, LLM-as-a-Judge generally outperforms reward-based approaches, with trained judges surpassing general-purpose LLMs. We further observe a small performance gap between LLMs acting as judges and as single agents, and identify a context-length-performance trade-off in verification. Overall, our results suggest that effective and robust process verification for MAS remains an open challenge, requiring further advances beyond current paradigms. Code is available at https://github.com/Wang-ML-Lab/MAS-ProVe.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025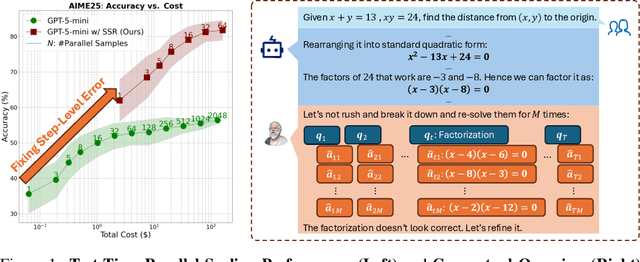
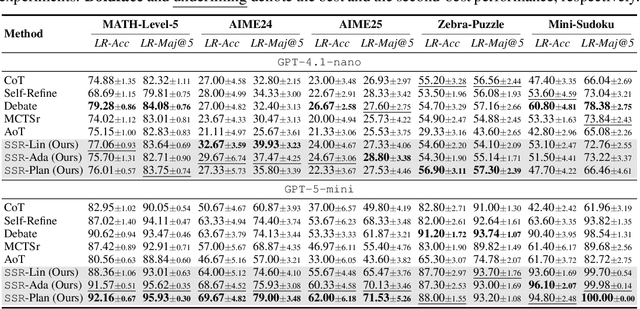
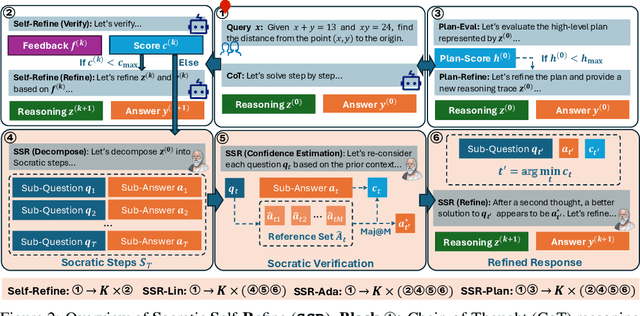
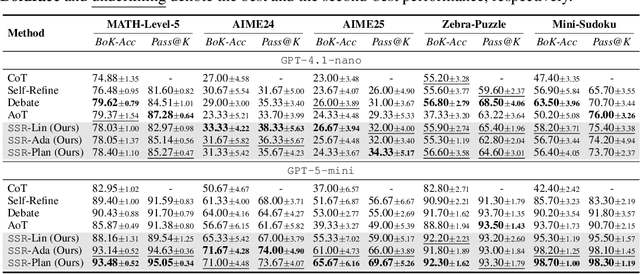
Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025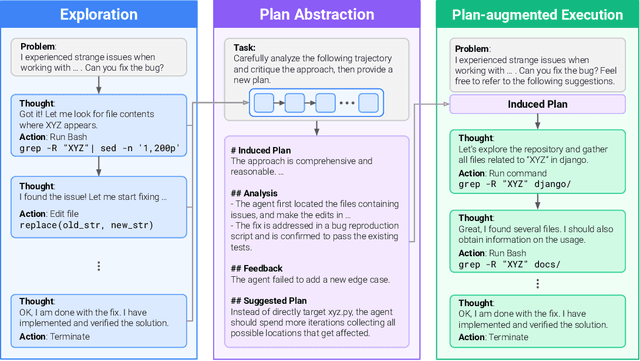

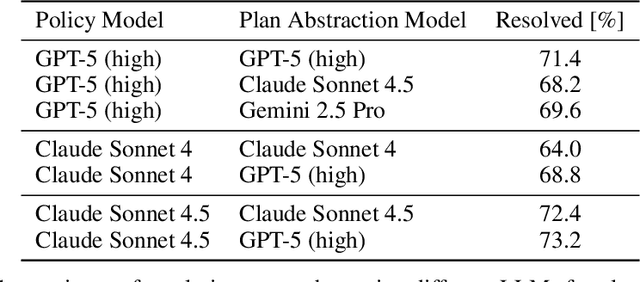
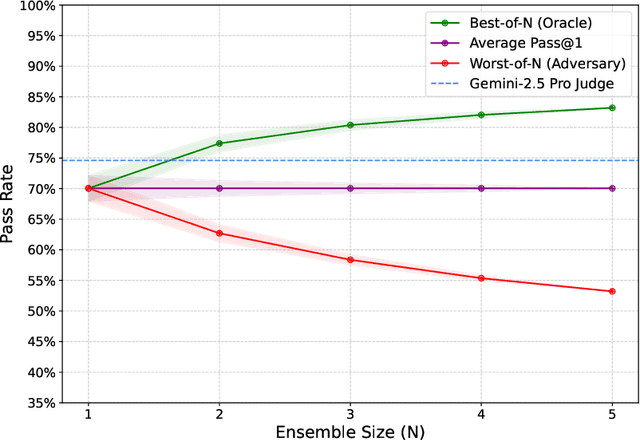
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Reasoning Curriculum: Bootstrapping Broad LLM Reasoning from Math
Oct 30, 2025Reinforcement learning (RL) can elicit strong reasoning in large language models (LLMs), yet most open efforts focus on math and code. We propose Reasoning Curriculum, a simple two-stage curriculum that first elicits reasoning skills in pretraining-aligned domains such as math, then adapts and refines these skills across other domains via joint RL. Stage 1 performs a brief cold start and then math-only RL with verifiable rewards to develop reasoning skills. Stage 2 runs joint RL on mixed-domain data to transfer and consolidate these skills. The curriculum is minimal and backbone-agnostic, requiring no specialized reward models beyond standard verifiability checks. Evaluated on Qwen3-4B and Llama-3.1-8B over a multi-domain suite, reasoning curriculum yields consistent gains. Ablations and a cognitive-skill analysis indicate that both stages are necessary and that math-first elicitation increases cognitive behaviors important for solving complex problems. Reasoning Curriculum provides a compact, easy-to-adopt recipe for general reasoning.
Retrofitting Small Multilingual Models for Retrieval: Matching 7B Performance with 300M Parameters
Oct 16, 2025Training effective multilingual embedding models presents unique challenges due to the diversity of languages and task objectives. Although small multilingual models (<1 B parameters) perform well on multilingual tasks generally, they consistently lag behind larger models (>1 B) in the most prevalent use case: retrieval. This raises a critical question: Can smaller models be retrofitted specifically for retrieval tasks to enhance their performance? In this work, we investigate key factors that influence the effectiveness of multilingual embeddings, focusing on training data scale, negative sampling strategies, and data diversity. We find that while increasing the scale of training data yields initial performance gains, these improvements quickly plateau - indicating diminishing returns. Incorporating hard negatives proves essential for consistently improving retrieval accuracy. Furthermore, our analysis reveals that task diversity in the training data contributes more significantly to performance than language diversity alone. As a result, we develop a compact (approximately 300M) multilingual model that achieves retrieval performance comparable to or even surpassing current strong 7B models.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.
xGen-small Technical Report
May 10, 2025



We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.