 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
MobileWorldBench: Towards Semantic World Modeling For Mobile Agents
Dec 16, 2025World models have shown great utility in improving the task performance of embodied agents. While prior work largely focuses on pixel-space world models, these approaches face practical limitations in GUI settings, where predicting complex visual elements in future states is often difficult. In this work, we explore an alternative formulation of world modeling for GUI agents, where state transitions are described in natural language rather than predicting raw pixels. First, we introduce MobileWorldBench, a benchmark that evaluates the ability of vision-language models (VLMs) to function as world models for mobile GUI agents. Second, we release MobileWorld, a large-scale dataset consisting of 1.4M samples, that significantly improves the world modeling capabilities of VLMs. Finally, we propose a novel framework that integrates VLM world models into the planning framework of mobile agents, demonstrating that semantic world models can directly benefit mobile agents by improving task success rates. The code and dataset is available at https://github.com/jacklishufan/MobileWorld
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025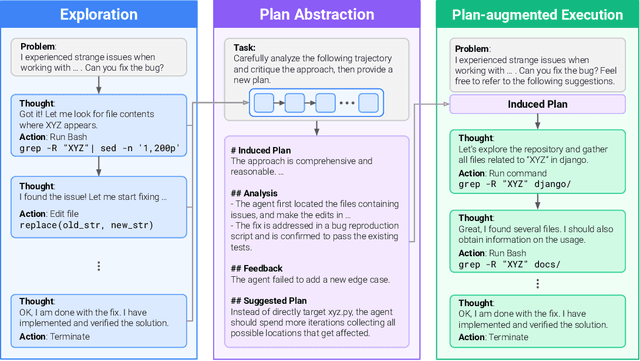

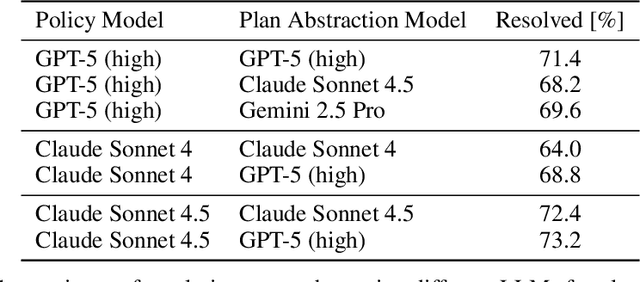
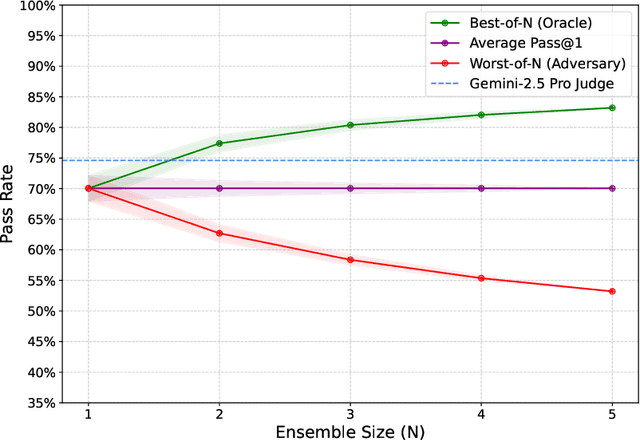
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
LaViDa: A Large Diffusion Language Model for Multimodal Understanding
May 22, 2025Modern Vision-Language Models (VLMs) can solve a wide range of tasks requiring visual reasoning. In real-world scenarios, desirable properties for VLMs include fast inference and controllable generation (e.g., constraining outputs to adhere to a desired format). However, existing autoregressive (AR) VLMs like LLaVA struggle in these aspects. Discrete diffusion models (DMs) offer a promising alternative, enabling parallel decoding for faster inference and bidirectional context for controllable generation through text-infilling. While effective in language-only settings, DMs' potential for multimodal tasks is underexplored. We introduce LaViDa, a family of VLMs built on DMs. We build LaViDa by equipping DMs with a vision encoder and jointly fine-tune the combined parts for multimodal instruction following. To address challenges encountered, LaViDa incorporates novel techniques such as complementary masking for effective training, prefix KV cache for efficient inference, and timestep shifting for high-quality sampling. Experiments show that LaViDa achieves competitive or superior performance to AR VLMs on multi-modal benchmarks such as MMMU, while offering unique advantages of DMs, including flexible speed-quality tradeoff, controllability, and bidirectional reasoning. On COCO captioning, LaViDa surpasses Open-LLaVa-Next-8B by +4.1 CIDEr with 1.92x speedup. On bidirectional tasks, it achieves +59% improvement on Constrained Poem Completion. These results demonstrate LaViDa as a strong alternative to AR VLMs. Code and models will be released in the camera-ready version.
xGen-small Technical Report
May 10, 2025



We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.
Reflect-DiT: Inference-Time Scaling for Text-to-Image Diffusion Transformers via In-Context Reflection
Mar 15, 2025The predominant approach to advancing text-to-image generation has been training-time scaling, where larger models are trained on more data using greater computational resources. While effective, this approach is computationally expensive, leading to growing interest in inference-time scaling to improve performance. Currently, inference-time scaling for text-to-image diffusion models is largely limited to best-of-N sampling, where multiple images are generated per prompt and a selection model chooses the best output. Inspired by the recent success of reasoning models like DeepSeek-R1 in the language domain, we introduce an alternative to naive best-of-N sampling by equipping text-to-image Diffusion Transformers with in-context reflection capabilities. We propose Reflect-DiT, a method that enables Diffusion Transformers to refine their generations using in-context examples of previously generated images alongside textual feedback describing necessary improvements. Instead of passively relying on random sampling and hoping for a better result in a future generation, Reflect-DiT explicitly tailors its generations to address specific aspects requiring enhancement. Experimental results demonstrate that Reflect-DiT improves performance on the GenEval benchmark (+0.19) using SANA-1.0-1.6B as a base model. Additionally, it achieves a new state-of-the-art score of 0.81 on GenEval while generating only 20 samples per prompt, surpassing the previous best score of 0.80, which was obtained using a significantly larger model (SANA-1.5-4.8B) with 2048 samples under the best-of-N approach.
OmniFlow: Any-to-Any Generation with Multi-Modal Rectified Flows
Dec 02, 2024



We introduce OmniFlow, a novel generative model designed for any-to-any generation tasks such as text-to-image, text-to-audio, and audio-to-image synthesis. OmniFlow advances the rectified flow (RF) framework used in text-to-image models to handle the joint distribution of multiple modalities. It outperforms previous any-to-any models on a wide range of tasks, such as text-to-image and text-to-audio synthesis. Our work offers three key contributions: First, we extend RF to a multi-modal setting and introduce a novel guidance mechanism, enabling users to flexibly control the alignment between different modalities in the generated outputs. Second, we propose a novel architecture that extends the text-to-image MMDiT architecture of Stable Diffusion 3 and enables audio and text generation. The extended modules can be efficiently pretrained individually and merged with the vanilla text-to-image MMDiT for fine-tuning. Lastly, we conduct a comprehensive study on the design choices of rectified flow transformers for large-scale audio and text generation, providing valuable insights into optimizing performance across diverse modalities. The Code will be available at https://github.com/jacklishufan/OmniFlows.
Aligning Diffusion Models by Optimizing Human Utility
Apr 06, 2024



We present Diffusion-KTO, a novel approach for aligning text-to-image diffusion models by formulating the alignment objective as the maximization of expected human utility. Since this objective applies to each generation independently, Diffusion-KTO does not require collecting costly pairwise preference data nor training a complex reward model. Instead, our objective requires simple per-image binary feedback signals, e.g. likes or dislikes, which are abundantly available. After fine-tuning using Diffusion-KTO, text-to-image diffusion models exhibit superior performance compared to existing techniques, including supervised fine-tuning and Diffusion-DPO, both in terms of human judgment and automatic evaluation metrics such as PickScore and ImageReward. Overall, Diffusion-KTO unlocks the potential of leveraging readily available per-image binary signals and broadens the applicability of aligning text-to-image diffusion models with human preferences.
BootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models
Jan 25, 2024



Recent text-to-image generation models have demonstrated incredible success in generating images that faithfully follow input prompts. However, the requirement of using words to describe a desired concept provides limited control over the appearance of the generated concepts. In this work, we address this shortcoming by proposing an approach to enable personalization capabilities in existing text-to-image diffusion models. We propose a novel architecture (BootPIG) that allows a user to provide reference images of an object in order to guide the appearance of a concept in the generated images. The proposed BootPIG architecture makes minimal modifications to a pretrained text-to-image diffusion model and utilizes a separate UNet model to steer the generations toward the desired appearance. We introduce a training procedure that allows us to bootstrap personalization capabilities in the BootPIG architecture using data generated from pretrained text-to-image models, LLM chat agents, and image segmentation models. In contrast to existing methods that require several days of pretraining, the BootPIG architecture can be trained in approximately 1 hour. Experiments on the DreamBooth dataset demonstrate that BootPIG outperforms existing zero-shot methods while being comparable with test-time finetuning approaches. Through a user study, we validate the preference for BootPIG generations over existing methods both in maintaining fidelity to the reference object's appearance and aligning with textual prompts.
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules
Oct 13, 2023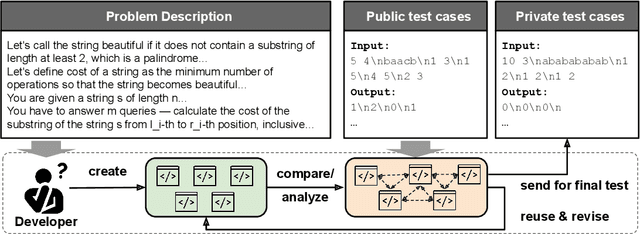
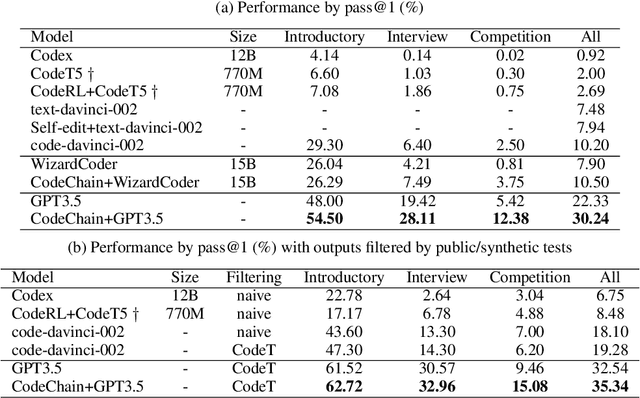
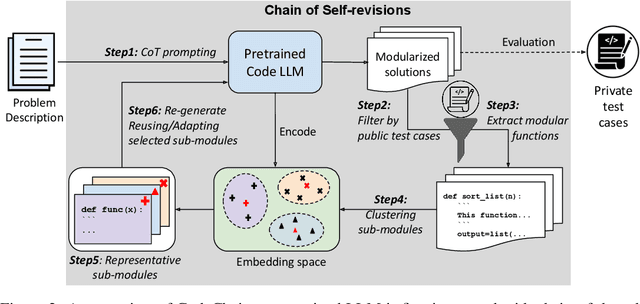
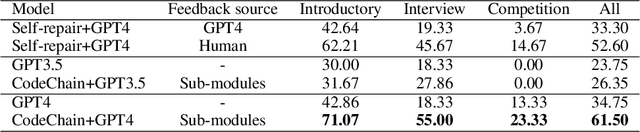
Large Language Models (LLMs) have already become quite proficient at solving simpler programming tasks like those in HumanEval or MBPP benchmarks. However, solving more complex and competitive programming tasks is still quite challenging for these models - possibly due to their tendency to generate solutions as monolithic code blocks instead of decomposing them into logical sub-tasks and sub-modules. On the other hand, experienced programmers instinctively write modularized code with abstraction for solving complex tasks, often reusing previously developed modules. To address this gap, we propose CodeChain, a novel framework for inference that elicits modularized code generation through a chain of self-revisions, each being guided by some representative sub-modules generated in previous iterations. Concretely, CodeChain first instructs the LLM to generate modularized codes through chain-of-thought prompting. Then it applies a chain of self-revisions by iterating the two steps: 1) extracting and clustering the generated sub-modules and selecting the cluster representatives as the more generic and re-usable implementations, and 2) augmenting the original chain-of-thought prompt with these selected module-implementations and instructing the LLM to re-generate new modularized solutions. We find that by naturally encouraging the LLM to reuse the previously developed and verified sub-modules, CodeChain can significantly boost both modularity as well as correctness of the generated solutions, achieving relative pass@1 improvements of 35% on APPS and 76% on CodeContests. It is shown to be effective on both OpenAI LLMs as well as open-sourced LLMs like WizardCoder. We also conduct comprehensive ablation studies with different methods of prompting, number of clusters, model sizes, program qualities, etc., to provide useful insights that underpin CodeChain's success.