 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
BootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models
Jan 25, 2024



Recent text-to-image generation models have demonstrated incredible success in generating images that faithfully follow input prompts. However, the requirement of using words to describe a desired concept provides limited control over the appearance of the generated concepts. In this work, we address this shortcoming by proposing an approach to enable personalization capabilities in existing text-to-image diffusion models. We propose a novel architecture (BootPIG) that allows a user to provide reference images of an object in order to guide the appearance of a concept in the generated images. The proposed BootPIG architecture makes minimal modifications to a pretrained text-to-image diffusion model and utilizes a separate UNet model to steer the generations toward the desired appearance. We introduce a training procedure that allows us to bootstrap personalization capabilities in the BootPIG architecture using data generated from pretrained text-to-image models, LLM chat agents, and image segmentation models. In contrast to existing methods that require several days of pretraining, the BootPIG architecture can be trained in approximately 1 hour. Experiments on the DreamBooth dataset demonstrate that BootPIG outperforms existing zero-shot methods while being comparable with test-time finetuning approaches. Through a user study, we validate the preference for BootPIG generations over existing methods both in maintaining fidelity to the reference object's appearance and aligning with textual prompts.
Diffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023



Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
ConRad: Image Constrained Radiance Fields for 3D Generation from a Single Image
Nov 09, 2023



We present a novel method for reconstructing 3D objects from a single RGB image. Our method leverages the latest image generation models to infer the hidden 3D structure while remaining faithful to the input image. While existing methods obtain impressive results in generating 3D models from text prompts, they do not provide an easy approach for conditioning on input RGB data. Na\"ive extensions of these methods often lead to improper alignment in appearance between the input image and the 3D reconstructions. We address these challenges by introducing Image Constrained Radiance Fields (ConRad), a novel variant of neural radiance fields. ConRad is an efficient 3D representation that explicitly captures the appearance of an input image in one viewpoint. We propose a training algorithm that leverages the single RGB image in conjunction with pretrained Diffusion Models to optimize the parameters of a ConRad representation. Extensive experiments show that ConRad representations can simplify preservation of image details while producing a realistic 3D reconstruction. Compared to existing state-of-the-art baselines, we show that our 3D reconstructions remain more faithful to the input and produce more consistent 3D models while demonstrating significantly improved quantitative performance on a ShapeNet object benchmark.
End-to-End Diffusion Latent Optimization Improves Classifier Guidance
Mar 23, 2023Classifier guidance -- using the gradients of an image classifier to steer the generations of a diffusion model -- has the potential to dramatically expand the creative control over image generation and editing. However, currently classifier guidance requires either training new noise-aware models to obtain accurate gradients or using a one-step denoising approximation of the final generation, which leads to misaligned gradients and sub-optimal control. We highlight this approximation's shortcomings and propose a novel guidance method: Direct Optimization of Diffusion Latents (DOODL), which enables plug-and-play guidance by optimizing diffusion latents w.r.t. the gradients of a pre-trained classifier on the true generated pixels, using an invertible diffusion process to achieve memory-efficient backpropagation. Showcasing the potential of more precise guidance, DOODL outperforms one-step classifier guidance on computational and human evaluation metrics across different forms of guidance: using CLIP guidance to improve generations of complex prompts from DrawBench, using fine-grained visual classifiers to expand the vocabulary of Stable Diffusion, enabling image-conditioned generation with a CLIP visual encoder, and improving image aesthetics using an aesthetic scoring network.
EDICT: Exact Diffusion Inversion via Coupled Transformations
Nov 22, 2022
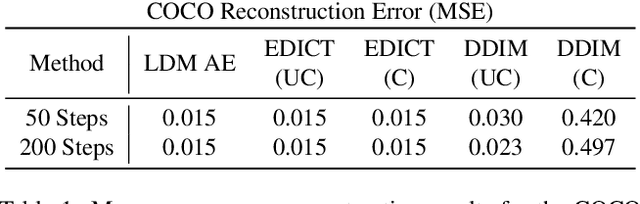

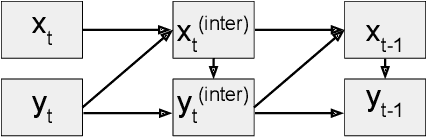
Finding an initial noise vector that produces an input image when fed into the diffusion process (known as inversion) is an important problem in denoising diffusion models (DDMs), with applications for real image editing. The state-of-the-art approach for real image editing with inversion uses denoising diffusion implicit models (DDIMs) to deterministically noise the image to the intermediate state along the path that the denoising would follow given the original conditioning. However, DDIM inversion for real images is unstable as it relies on local linearization assumptions, which result in the propagation of errors, leading to incorrect image reconstruction and loss of content. To alleviate these problems, we propose Exact Diffusion Inversion via Coupled Transformations (EDICT), an inversion method that draws inspiration from affine coupling layers. EDICT enables mathematically exact inversion of real and model-generated images by maintaining two coupled noise vectors which are used to invert each other in an alternating fashion. Using Stable Diffusion, a state-of-the-art latent diffusion model, we demonstrate that EDICT successfully reconstructs real images with high fidelity. On complex image datasets like MS-COCO, EDICT reconstruction significantly outperforms DDIM, improving the mean square error of reconstruction by a factor of two. Using noise vectors inverted from real images, EDICT enables a wide range of image edits--from local and global semantic edits to image stylization--while maintaining fidelity to the original image structure. EDICT requires no model training/finetuning, prompt tuning, or extra data and can be combined with any pretrained DDM. Code will be made available shortly.
ProGen2: Exploring the Boundaries of Protein Language Models
Jun 27, 2022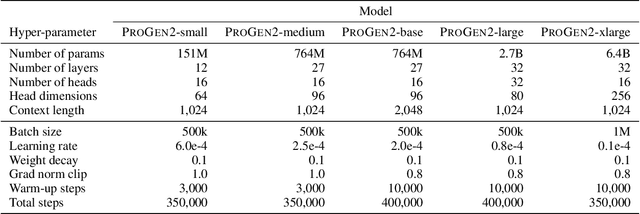
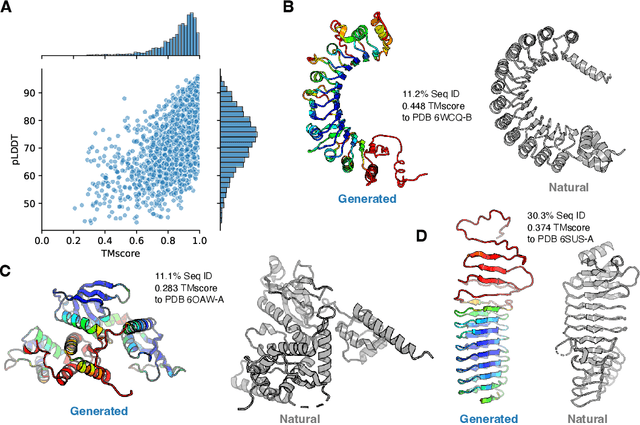
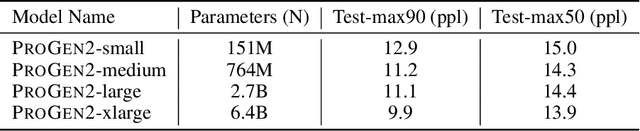
Attention-based models trained on protein sequences have demonstrated incredible success at classification and generation tasks relevant for artificial intelligence-driven protein design. However, we lack a sufficient understanding of how very large-scale models and data play a role in effective protein model development. We introduce a suite of protein language models, named ProGen2, that are scaled up to 6.4B parameters and trained on different sequence datasets drawn from over a billion proteins from genomic, metagenomic, and immune repertoire databases. ProGen2 models show state-of-the-art performance in capturing the distribution of observed evolutionary sequences, generating novel viable sequences, and predicting protein fitness without additional finetuning. As large model sizes and raw numbers of protein sequences continue to become more widely accessible, our results suggest that a growing emphasis needs to be placed on the data distribution provided to a protein sequence model. We release the ProGen2 models and code at https://github.com/salesforce/progen.
Can domain adaptation make object recognition work for everyone?
Apr 23, 2022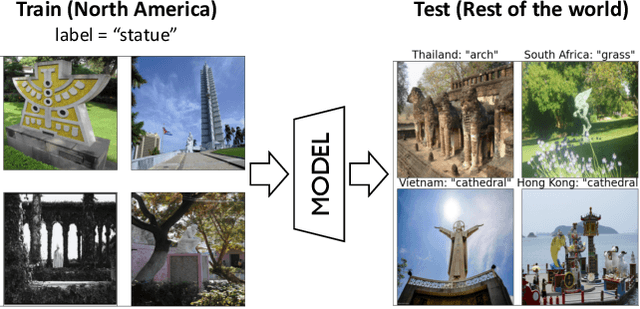



Despite the rapid progress in deep visual recognition, modern computer vision datasets significantly overrepresent the developed world and models trained on such datasets underperform on images from unseen geographies. We investigate the effectiveness of unsupervised domain adaptation (UDA) of such models across geographies at closing this performance gap. To do so, we first curate two shifts from existing datasets to study the Geographical DA problem, and discover new challenges beyond data distribution shift: context shift, wherein object surroundings may change significantly across geographies, and subpopulation shift, wherein the intra-category distributions may shift. We demonstrate the inefficacy of standard DA methods at Geographical DA, highlighting the need for specialized geographical adaptation solutions to address the challenge of making object recognition work for everyone.
CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
Dec 14, 2021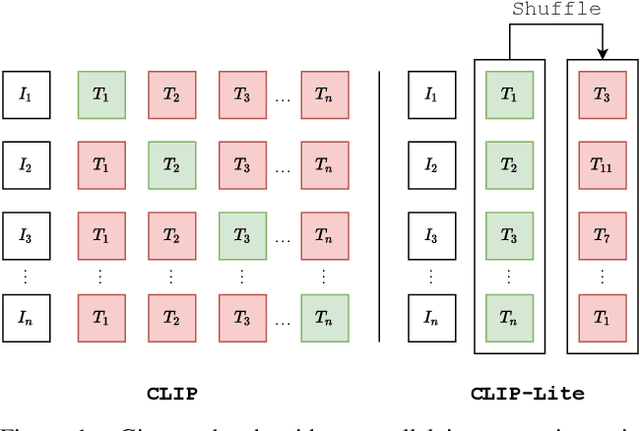
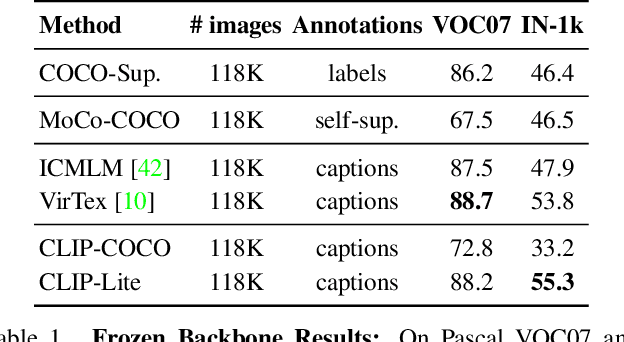

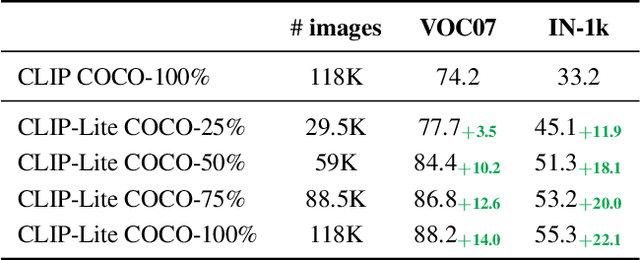
We propose CLIP-Lite, an information efficient method for visual representation learning by feature alignment with textual annotations. Compared to the previously proposed CLIP model, CLIP-Lite requires only one negative image-text sample pair for every positive image-text sample during the optimization of its contrastive learning objective. We accomplish this by taking advantage of an information efficient lower-bound to maximize the mutual information between the two input modalities. This allows CLIP-Lite to be trained with significantly reduced amounts of data and batch sizes while obtaining better performance than CLIP. We evaluate CLIP-Lite by pretraining on the COCO-Captions dataset and testing transfer learning to other datasets. CLIP-Lite obtains a +15.4% mAP absolute gain in performance on Pascal VOC classification, and a +22.1% top-1 accuracy gain on ImageNet, while being comparable or superior to other, more complex, text-supervised models. CLIP-Lite is also superior to CLIP on image and text retrieval, zero-shot classification, and visual grounding. Finally, by performing explicit image-text alignment during representation learning, we show that CLIP-Lite can leverage language semantics to encourage bias-free visual representations that can be used in downstream tasks.
PreViTS: Contrastive Pretraining with Video Tracking Supervision
Dec 01, 2021
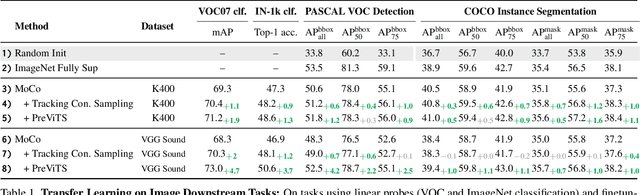
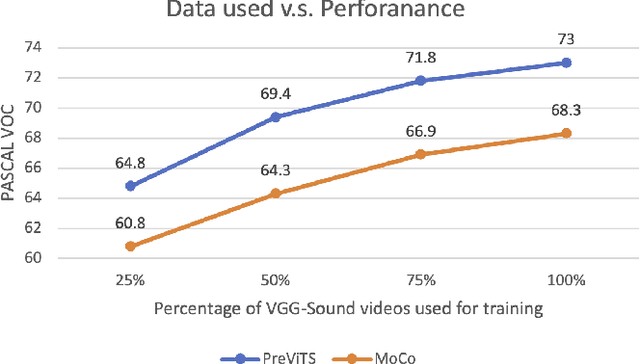
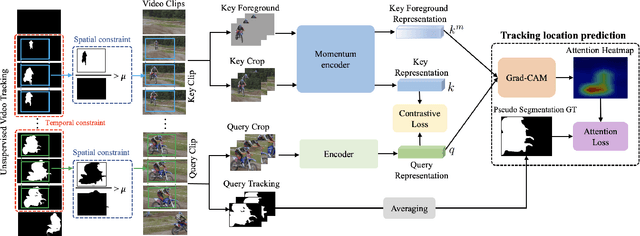
Videos are a rich source for self-supervised learning (SSL) of visual representations due to the presence of natural temporal transformations of objects. However, current methods typically randomly sample video clips for learning, which results in a poor supervisory signal. In this work, we propose PreViTS, an SSL framework that utilizes an unsupervised tracking signal for selecting clips containing the same object, which helps better utilize temporal transformations of objects. PreViTS further uses the tracking signal to spatially constrain the frame regions to learn from and trains the model to locate meaningful objects by providing supervision on Grad-CAM attention maps. To evaluate our approach, we train a momentum contrastive (MoCo) encoder on VGG-Sound and Kinetics-400 datasets with PreViTS. Training with PreViTS outperforms representations learnt by MoCo alone on both image recognition and video classification downstream tasks, obtaining state-of-the-art performance on action classification. PreViTS helps learn feature representations that are more robust to changes in background and context, as seen by experiments on image and video datasets with background changes. Learning from large-scale uncurated videos with PreViTS could lead to more accurate and robust visual feature representations.