 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Joint Sequence-Structure Generation of Nucleic Acid and Protein Complexes with SE(3)-Discrete Diffusion
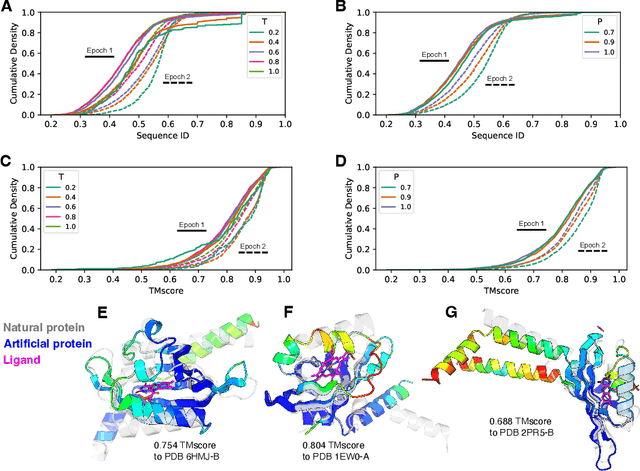
Dec 21, 2023Generative models of macromolecules carry abundant and impactful implications for industrial and biomedical efforts in protein engineering. However, existing methods are currently limited to modeling protein structures or sequences, independently or jointly, without regard to the interactions that commonly occur between proteins and other macromolecules. In this work, we introduce MMDiff, a generative model that jointly designs sequences and structures of nucleic acid and protein complexes, independently or in complex, using joint SE(3)-discrete diffusion noise. Such a model has important implications for emerging areas of macromolecular design including structure-based transcription factor design and design of noncoding RNA sequences. We demonstrate the utility of MMDiff through a rigorous new design benchmark for macromolecular complex generation that we introduce in this work. Our results demonstrate that MMDiff is able to successfully generate micro-RNA and single-stranded DNA molecules while being modestly capable of joint modeling DNA and RNA molecules in interaction with multi-chain protein complexes. Source code: https://github.com/Profluent-Internships/MMDiff.
ProGen2: Exploring the Boundaries of Protein Language Models
Jun 27, 2022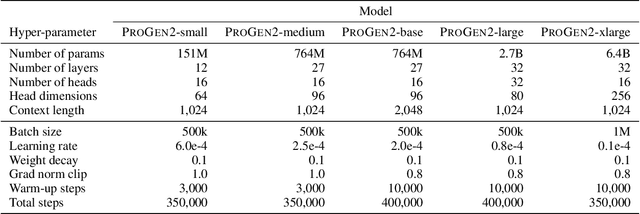
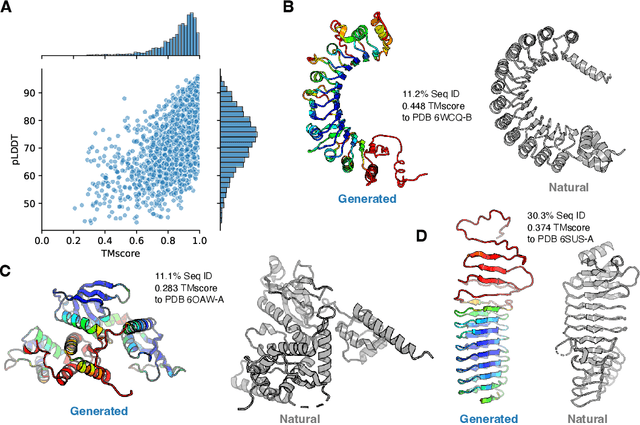
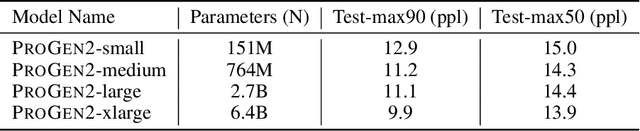
Attention-based models trained on protein sequences have demonstrated incredible success at classification and generation tasks relevant for artificial intelligence-driven protein design. However, we lack a sufficient understanding of how very large-scale models and data play a role in effective protein model development. We introduce a suite of protein language models, named ProGen2, that are scaled up to 6.4B parameters and trained on different sequence datasets drawn from over a billion proteins from genomic, metagenomic, and immune repertoire databases. ProGen2 models show state-of-the-art performance in capturing the distribution of observed evolutionary sequences, generating novel viable sequences, and predicting protein fitness without additional finetuning. As large model sizes and raw numbers of protein sequences continue to become more widely accessible, our results suggest that a growing emphasis needs to be placed on the data distribution provided to a protein sequence model. We release the ProGen2 models and code at https://github.com/salesforce/progen.